
The widening performance disparity between compute and I/O is not likely to get any better in the fast-approaching exascale era. In fact, even though hardware advances in areas like storage-class memory, NVM-Express, and other flash-based componentry can accelerate the flow of data between the processor and storage, compute will continue to outpace I/O for the foreseeable future.
That leaves much of the heavy lifting to be done on the software side. And certainly there has been plenty of activity here, especially in areas like NVMe-over-Fabrics and burst buffers, as well as more specific solutions like DAOS. To one extent or another, all of these assume there is some underlying solid state storage or memory to speed things along.
A more general-purpose software approach can be found with the Adaptable IO System, also known as ADIOS, which is an I/O abstraction library originally developed at Oak Ridge National Laboratory and Georgia Tech. The first production version was released in 2009.
Essentially, ADIOS offers a set of APIs that enables HPC developers to more precisely control their data pipelines for things like checkpointing, diagnostics, and analytics. Although it has its own internal file format to do this, at the application level, it supports the open source Lustre file system as well as IBM’s Spectrum Scale (originally GPFS) file system. The schematic below illustrates its functionality and how other software components can be plugged into it.
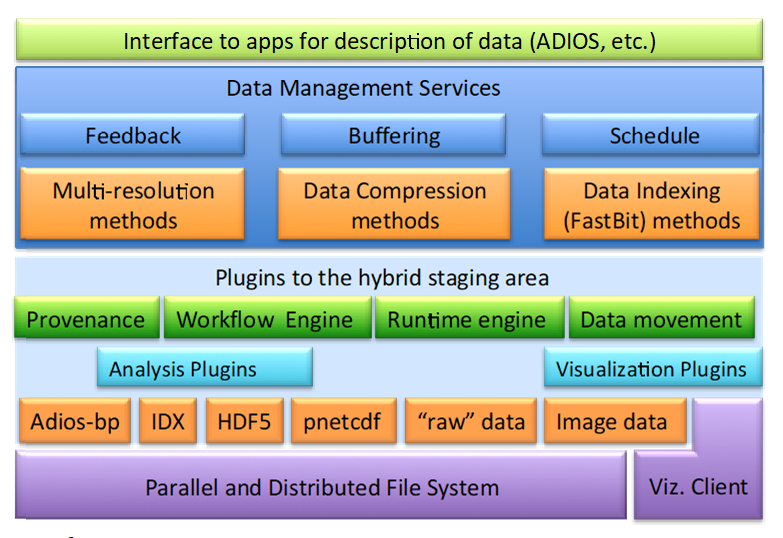
A lot of the speedup ADIOS delivers is the result of data staging, where intermediate results are buffered before outputting it out to a file. This can be looked at as a form of burst buffering, but here within a broader framework of I/O management and without the assumption of solid state memory. ADIOS also provides the capability of performing data transforms in this staging area, which could be analysis, compression, data reduction, or what have you. As a result of this staging model, file reads and writes, as well as the associated file metadata operations, can be kept to a minimum.
In addition, ADIOS offers a proprietary file format, known as BP, now in its third iteration. BP is especially useful for collecting an application’s log-based or time-stepped data in a single file. These subfile chunks are managed internally by the ADIOS runtime library. Not only does this avoid the expensive POSIX file creation process, it also has the practical advantage of recording the evolution of a particular kind of data in one place, which would simplify post-processing.
Performance-wise, users typically see a ten-fold increase in I/O throughput with ADIOS, although 100-fold and even 1,000-fold speedups have been reported. Applications areas encompass a wide array of HPC workloads, including astrophysics, climate analysis, seismology, fusion modeling, combustion, and industrial engineering, to name a few.
Since ADIOS was developed at ORNL, it stands to reason that it would end up getting a workout on “Summit,” the flagship supercomputer at Oak Ridge and currently the world’s most powerful HPC machine. In this case, ADIOS was used to speed I/O on the Gyrokinetic Toroidal Code (GTC), which simulates the movement of magnetic particles in a confined fusion plasma. Like many physics codes, GTC spits out reams of files during its simulation, in this case, made up of diagnostics data, field data, checkpoint-restart files, and particle data.
In a typical simulation run, GTC can be expected to write a few petabytes of file data, which is a daunting task even for Summit’s impressively large storage system, known as Alpine. Although Alpine has an aggregate capacity of 250 PB, Spectrum Scale system tops out at 2.5 TB/sec for sequential I/O and 2.2 TB/sec for random I/O. Thus, even at top speed, writing a single petabyte of data takes over eight minutes.
In the paper that describes the results of the ADIOS work on Summit, the researchers note that optimizing I/O performance for GTC is challenging, since each of these data pipelines has different characteristics.
“In general, diagnostics data are high velocity data that are written frequently, and read back multiple times for analysis, both online as well as offline,” the researchers write. “Checkpoint data are write-once; that is, they are written for resilience purposes with the intention of simulation restarts. Checkpoint and particle data are high volume and writing them usually consumes significant resources. Furthermore, checkpoint and restart data are high variety data, as their underlying variables are comprised of scalars, vectors, and multi-dimensional arrays.”
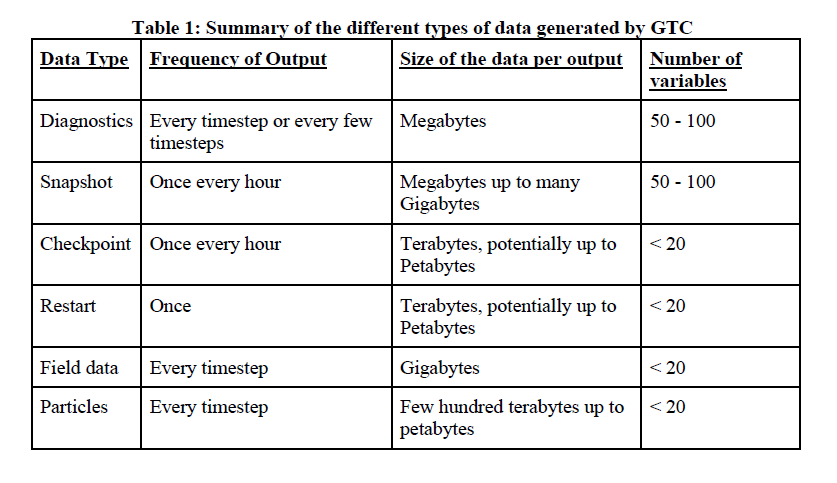 The particle data is probably hardest on the file system, since it represents both high frequency (every time-step in the simulation) and large data sizes (a few hundred terabytes up to petabytes). The checkpoint files can be just as large, but they are only written once an hour. On the other hand, field data is written every time-step, but data volume is on the order of just gigabytes. Overall, GTC can generate data at the rate of more than 100 TB per hour.
The particle data is probably hardest on the file system, since it represents both high frequency (every time-step in the simulation) and large data sizes (a few hundred terabytes up to petabytes). The checkpoint files can be just as large, but they are only written once an hour. On the other hand, field data is written every time-step, but data volume is on the order of just gigabytes. Overall, GTC can generate data at the rate of more than 100 TB per hour.
Data size notwithstanding, the frequency of creating and writing files at each time-step is always an issue at this scale since the metadata overhead can easily become a bottleneck. For a typical GTC run using POSIX I/O, we are talking about tens of thousands of individual files. This could theoretically be solved by writing to fewer files, but POSIX I/O is not very adept at aggregating data from multiple processes. Since ADIOS is able to stage the data and do its metadata management internally, this is much less of a problem.
The advantage of fewer files can be seen by the GTC results. The POSIX I/O version of the application created nearly 50,000 files, while the ADIOS version created just over 6,000 files. In the case of the “snapshot” data, 10,000 POSIX I/O files were reduced to just one ADIOS file, resulting in a 50X performance improvement.
The researchers also demonstrated that ADIOS was able to achieve over two terabytes per second of performance for writing GTC checkpoint files, although they neglected to offer the comparable metric for the POSIX I/O version. Nevertheless, since the maximum bandwidth for sequential I/O on the Summit’s Spectrum Scale storage system is 2.5 TB/sec, we can assume the ADIOS performance is about as good as it gets.
However, metadata management in ADIOS is not without its own challenges. Even though the metadata is being managed internally to keep track of each file chunk, as the time-steps grow, so does the overhead. That’s because ADIOS uses an MPI “writer” process for each of these chunks, which comes with its own overhead. For applications like GTC with a lot of chunked time-steps, the result is that the metadata overhead is going to get onerous as the scale of these applications gets larger and larger.
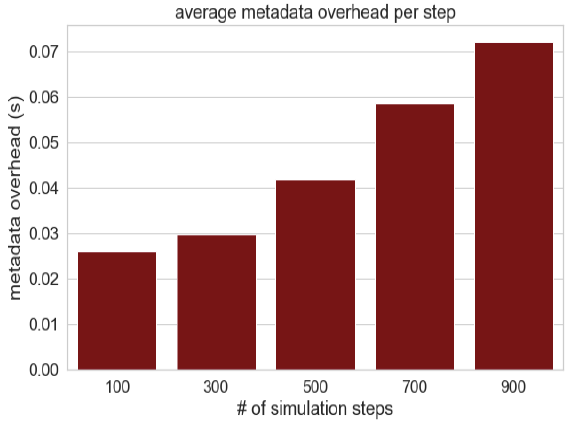
To get around this problem, ADIOS is introducing its fourth-generation BP format (BP4), which is specifically geared for exascale applications. The key element here is that it will use an index table to get around the need to serially sort and parse the chunked metadata. Early tests here have shown that the average overhead is not only reduced but is relatively constant as the number of time-steps is increased.
Of course, ADIOS is not the last word in HPC data management. The researchers note that there is plenty of work to be done in other areas of the I/O stack, including software for better utilization of solid state memory and innovations with new parallel file systems.

Frontier: Step By Step, Over Decades, To Exascale
Any time you build anything with more than 60 million parts, it is going to be a headache. And if you have to create a space in a datacenter and build an exascale system with all of those parts, each of which is crucial, during a global pandemic, it gets …
The Final Frontier: Talking Exascale With Oak Ridge’s Jeff Nichols
Just ahead of the revelations about the feeds and speeds of the “Frontier” supercomputer at Oak Ridge National Laboratory concurrent with the International Supercomputing conference in Hamburg, Germany and the concurrent publishing of the summer Top500 rankings of supercomputers, we had a chat with Jeff Nichols, who has steered the …
Lining Up The “El Capitan” Supercomputer Against The AI Upstarts
The question is no longer whether or not the “El Capitan” supercomputer that has been in the process of being installed at Lawrence Livermore National Laboratory for the past week – with photographic evidence to prove it – will be the most powerful system in the world. The question is …
Be the first to comment