



Hoarding data using commodity storage servers is “cheap and cheerful,” as the phrase goes. But finding that data and managing it is another matter entirely, and the problem gets worse as the number of files and objects grows.
That’s why a bunch of experts who designed the high-performance Isilon network-attached storage arrays, now part of the EMC portfolio, have teamed up with engineers who built storage systems at Microsoft, Google, and Amazon Web Services to launch a startup called Qumulo. The company has just uncloaked out of stealth mode and has created a new kind of file system with analytics embedded into it so management and monitoring of the storage scales linearly with the capacity.
The Qumulo Scalable File System has been in development for several years, and Peter Godman, co-founder and CEO at Qumulo and one of the creators of the Isilon system, tells The Next Platform that the software as well as storage appliances equipped with it will initially be targeted at customers with many petabytes of storage under management and the most pressing needs to manage access to their files and objects. The customers are the usual suspects that bridge the gap between large enterprises, HPC, including companies in media and entertainment, oil and gas, life sciences, and chip design sectors.
Qumulo is based in Seattle and was founded three years ago by the same team that developed the Isilon array and its OneFS file system. Godman says that the first big advance in storage was the creation of network attached storage as exemplified by NetApp in the 1990s. The systems were very good at storing lots of little files, but it was fairly labor intensive managing the movement of files across racks of files to balance capacity and performance needs. Then storage went to the other extreme with the advent of object storage, creating a huge bucket that could store files and let the system take care of the rebalancing of files. And, by and large, this was pretty successful, but then the data kept growing and growing.
“The problem gets exponentially more difficult,” says Godman. “We had a lot of feedback from people, and they said that NetApp was great for small files and transactions, but it was terrible at scale. Others said Isilon was super-easy at scale, but it was really bad with small files. Stuff like Panasas that is really good with performance against really large files. It is kind of crazy, but there is nothing that is really good across the board right now.”
Godman says that before Qumulo even wrote one line of the QSFS code, it talked to over 600 companies to get a sense of their most pressing issues as they managed multiple petabytes of data, and the same answer came back again and again: Companies can’t really do capacity planning because they don’t know how their data is being used in the aggregate and they can’t easily do a search on a file system or object store to find where data is located, or better still, locate hot spots in the data to try to get around bottlenecks. The kinds of things a storage administrator can do on storage with a million files will start breaking down at a billion files, and will not work at all on a trillion files.
“Traditionally, file systems are kind of dumb, it is just a tree and it doesn’t know what is happening except in the part of the tree that you are looking at. But QSFS has a hierarchical awareness and it can answer questions about data sets that are a lot more complicated than what is in a directory.”
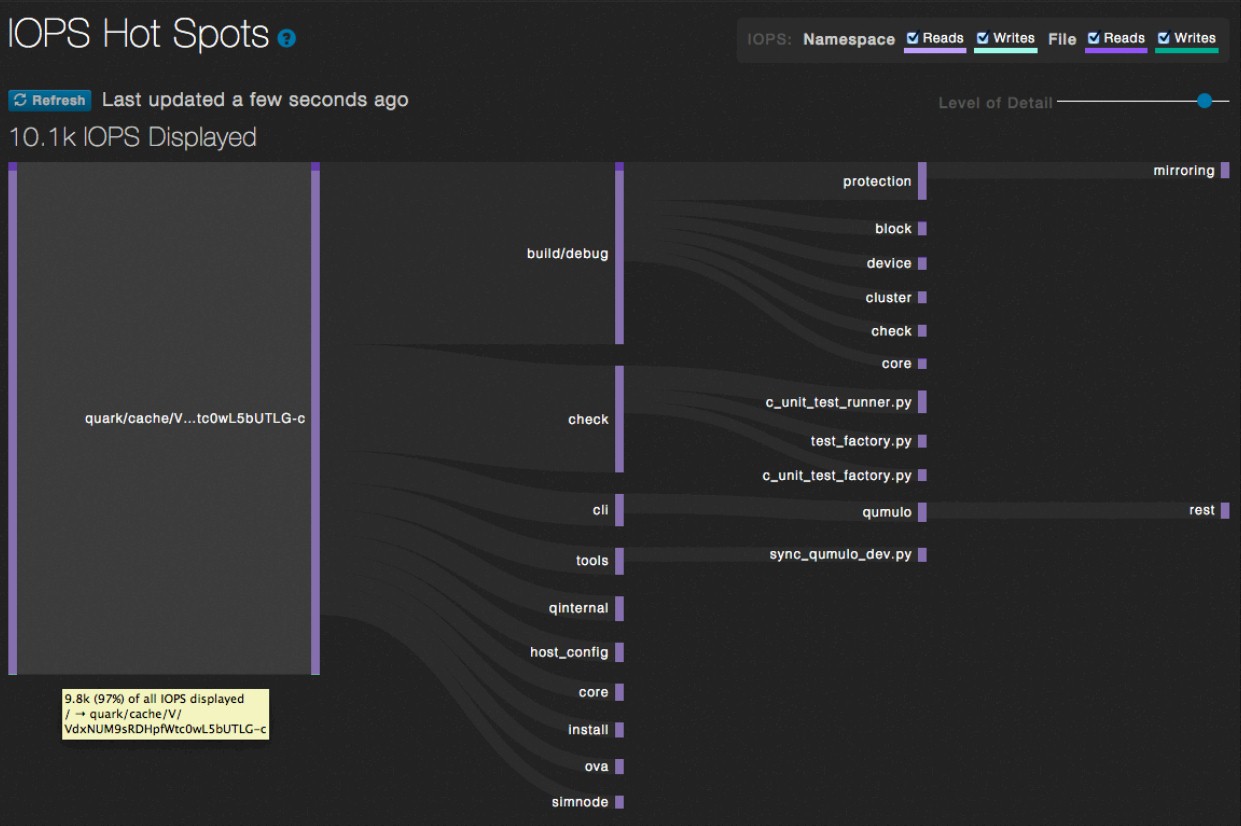
To accomplish this, the metadata describing the files in QSFS is embedded in indexes that are attached to file system tree itself. There are aggregates of data describing the files for any part of the file system, up and down the file system tree, all in real time. The QSFS interface combines these aggregates or drills down into them to provide different levels of granularity about what precisely is going on inside the file system in terms of how many directories and files there are encapsulated in it and where the I/O operations are being burned up. With current file systems, this is a poke and hope operation by storage administrators – and the issues always seem to crop up on the weekends. With the Qumulo tools, not only has the company created a file system that is pretty good at most kinds of work, but it is also able to present performance and capacity information for portions of the file system on the fly, making it easy – if not obvious – to see where capacity has run out or where performance bottlenecks are in the system. The hunting and pecking to figure this out is over.
The Feeds And Speeds Of QSFS
The QSFS file system is a user-mode Linux application that can run on bare metal, virtualized server instances running on a private cloud or a public cloud, and the appliances that Qumulo is building for itself. QSFS runs on the Linux kernel and uses cryptographic libraries from the open source community, but the file system, which has under 1 million lines of code according to Godwin, is a ground-up, brand-new file system that does not borrow code from any other open source file systems.
QSFS presents itself to applications as an NFS or an SMB file system, and also has an object store layer if companies want to go that route to store unstructured data like log files and clickstreams. QSFS assumes that the storage arrays, whether physical or virtual, will have a mix of flash and disk, and like other file systems, the hottest data is put on flash for fast access and the coldest data is put on spinning rust to get the lowest cost per unit of storage for the bulk of the data. The file system indexes that are part of the hierarchical database embedded in QSFS are stored in main memory and flash memory to speed up access to that data. QSFS has a command line interface for those storage techies that like to query and manage storage the old fashioned way, and it also has a graphic interface for newbies and a set of REST APIs to expose all of the functions of the file system and make its management programmatical and automatic.
The base Qumulo Q0626 appliance comes with four server nodes, each of them coming in a 1U form factor with four 6 TB Helium disk drives from HGST/Western Digital and four 800 GB solid state disks from Intel. The nodes in the appliance have a single Intel Xeon E5-1650 v2 processor with six cores running at 3.5 GHz and 64 GB of main memory to run the Qumulo Core software stack. The storage servers have two 10 Gb/sec Ethernet ports that allows them to be clustered together and customers have been buying Arista Networks switches for the most part to lash the nodes together, but they can use any 10 Gb/sec Ethernet switch that they want. The QSFS file system presents 25.6 TB of raw capacity per node and can scale to more than 1,000 nodes, tens of gigabytes per second of throughput, and petabytes of storage. It supports the NFS v3 and SMB v2.1 file protocols today and will support Qumulo’s object interface in the near future. The whole shebang costs $50,000 and about half of that is an annual license to the QSFS software and half is the hardware (minus the switch).
Accumulating Petabytes Made Manageable
To prove that QSFS can handle lots of file, Qumulo stacked up a minimum configuration of its appliance, which has four storage server nodes and loaded it up with over 4 billion files and nearly 300,000 directories. Godman says you cannot do this with Isilon arrays because if you blew a disk drive it would take you months to rebuild the data. But the Qumulo appliance can rebuild the data from a lost drive in about 17 hours. (The company is not saying how it is protecting the data and what mechanism it is using to rebuild lost data if a drive fails, but says the process takes orders of magnitude less time than in other scale-out storage arrays sold today.) Godman says that the system can do a rebuild and continue to perform its analytics regardless of the load on this entry system. Most of the current methods to manage file systems break down at tens of millions of files, according to Qumulo. It takes about 90 seconds to add a node and have its capacity available for files.
Here is where Qumulo puts itself on the storage tree of life:
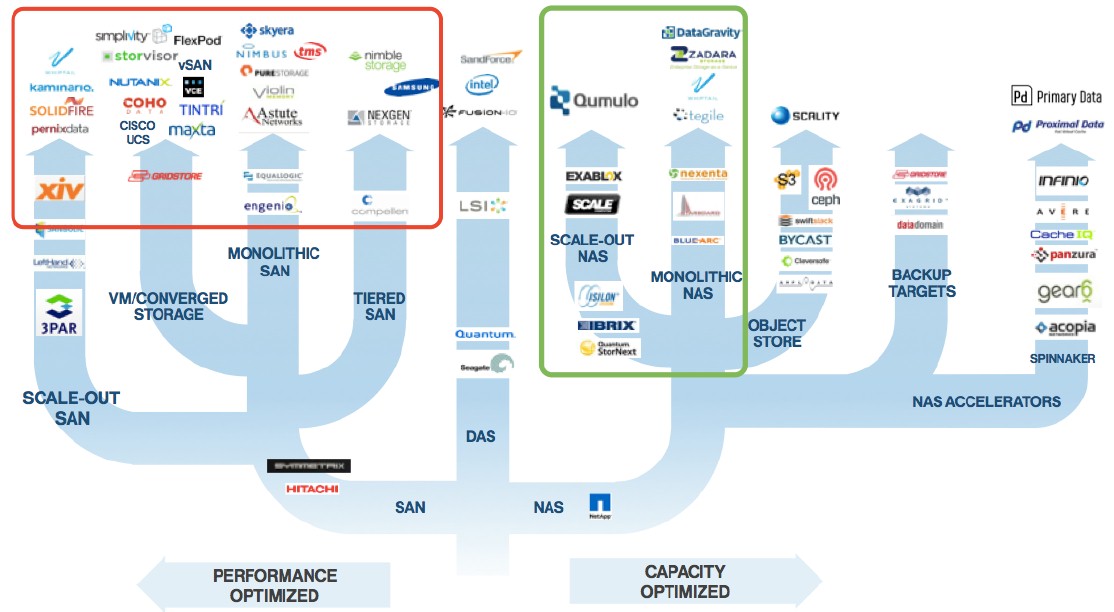
Qumulo has raised $67 million in several rounds of venture funding, and after getting rolling with product development in the wake of all of those interviews with enterprises managing lots of storage, Godman says that he reckoned the company would end up on the left side of the storage array tree above. But after pondering the options and what issues to tackle, the company’s founders decided to create a product that fits more on the right side.
Of the company’s initial 16 customers, the majority are buying the Qumulo appliances because they come ready to run with no setup required, and more importantly, Qumulo operates the devices under a SaaS model and pushes out updates to the underlying file system every two weeks and monitors the health of the file system remotely through a service called MissionQ. The Qumulo Core software stack, as it is called, can be run on bare metal servers, either the appliances from Qumulo or on any X86 servers provided they have an appropriate mix of flash and disk, and they can also be run on public cloud server instances so long as they have a mix of flash and disk available.