


Chip maker Nvidia has come a long way in transforming its graphics processors so they can not only be used to drive screens, but also to work as efficient and powerful floating point engines to accelerate modeling and simulation workloads.
At the GPU Technology Conference hosted in its hometown of San Jose, co-founder and CEO Jen-Hsun Huang declared the adjacent market of deep learning – a more neutral term than machine learning – as the next big wave of GPU computing. And, as Huang tells it, deep learning could be more important in the grand scheme of things than the advent of the Internet as intelligent automation makes its way into our professional and personal lives, doing tasks better than we can.
All makers of compute engines, including Nvidia, as well as storage devices and networking gear very much want for these new classes of deep learning workloads to take off because that will keep companies consuming more IT gear. All of the big hyperscale players have deep learning facilities, doing everything from speech, text, image, and video recognition to operating machinery, like our cars, autonomously on our behalf. Deep learning got its start in academia, with the creation of neural networks that emulate some of the processes in the human brain, decades ago, and in recent years have flowered as hyperscale companies have to process unprecedented volumes of rich media data and are using more sophisticated and accurate neural network software, painfully developed over decades, to do this. It is beginning to look like a “big bang” in deep learning is about to happen, as Huang put it, thanks to the confluence of better approaches, such as convoluted neural networks and cheap floating point performance.
As you might expect, while talking up the potential future market for its GPU engines, the company bragged a bit about the transformation of the HPC market by Tesla GPU coprocessors as adjuncts for CPUs in X86, ARM, and Power systems and clusters. GPU coprocessors give such systems substantially more floating point performance at a lower cost, lower electricity consumption, and lower heat dissipation than sticking with CPU-only machinery. During his keynote, Huang revealed some figures to show just how pervasive Tesla coprocessors have become in HPC:

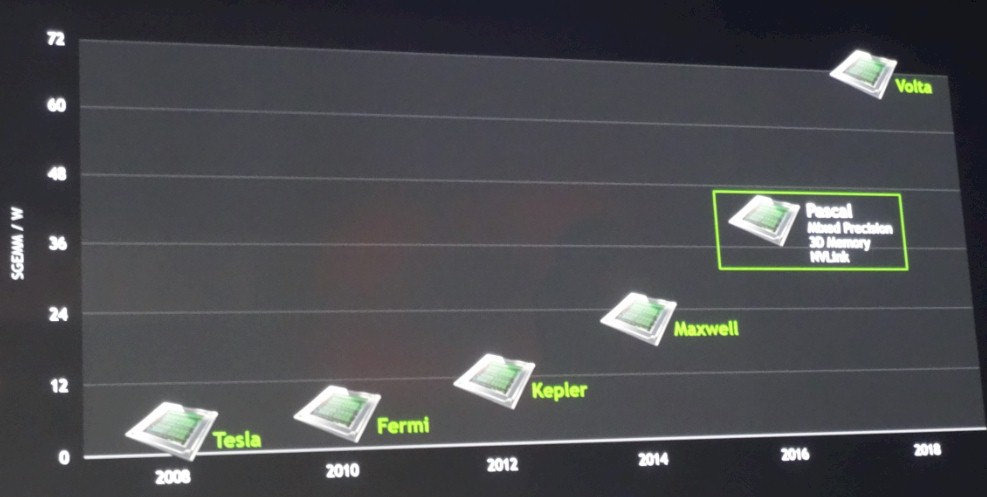
While the CUDA programming environment for GPU offload was invented in 2006 for the GeForce 8800 graphics cards, the concept of a separate Tesla GPU coprocessor aimed at supercomputing clusters did not happen until two years later with the launch of the Tesla C870 and D870 devices, which offered single precision floating point processing. From there, Nvidia has moved through four generations of GPUs – code-named Tesla, Fermi, Kepler, and Maxwell, with Pascal and Volta still on the horizon – has increased the performance by roughly an order of magnitude and, interestingly enough, the Tesla computing installed base has grown by about an order of magnitude, too. (It is really about a factor of 8X, but as Huang himself admitted, he does “CEO Math,” where things are expressed in generalities, not with precision. Ironic, isn’t it?)
The growth in the Tesla business has been phenomenal, and as The Next Platform has recently reported, through Nvidia’s fiscal 2015 year (which ended in January), the Tesla line is now at an annual revenue run rate of “several hundred million dollars” and grew at around 50 percent in the last fiscal year for Nvidia, driven by strong adoption by both HPC and hyperscale organizations. Nvidia has talked about the number of CUDA downloads, the number of CUDA-enabled applications, and academic papers relating to GPU coprocessing in the past. New at the GTC 2015 event this week was Huang divulging that Nvidia has shipped a cumulative 450,000 Tesla coprocessors, an increase of 7.5 percent from 2008. (Cumulative CUDA downloads have increased by a factor of 20X, and that is because CUDA works on all Nvidia GPUs, not just Tesla coprocessors.) The CUDA app count is up by a factor of 12X, to 319, as the fiscal year ended.
“This is amazing progress in a few short years,” Huang said, and it probably will not be long before sales of Tesla products are material enough that they will be broken out separately from other GPU sales for client devices. These days, all kinds of applications are being accelerated by GPUs, including databases and data stores, various kinds of streaming applications, as well as the traditional simulation and modeling workloads that are commonly called HPC.
Like in the past, software developers who have been looking at how to deploy cheap flops to run applications to get better bang for the buck have been driving Nvidia into the deep learning market. And Nvidia is reacting to the needs of this nascent but fast-growing market by doing what all compute engine makers do: Offering chips that are more precisely tuned to goose the performance of workloads. To that end, Huang flashed up a roadmap of future GPUs:
The new data on that roadmap is that the future “Pascal” processors will not only support 3D memory, which has high bandwidth as well as high capacity, but also will offer mixed precision floating point calculation, specifically 16-bit FP16 instructions. Jonah Alben, senior vice president of GPU engineering at Nvidia, tells The Next Platform that this 16-bit floating point math would not only be useful for deep learning but also various kinds of imaging applications that can do fine with 16-bits rather than the 32-bits of single precision or the 64-bits of double precision.
Alben also confirmed that as has been the case with past generations of GPUs, some features that are available in high-end, server coprocessor variants of the Nvidia GPUs are not cascaded down to workstation and client parts. The dynamic parallelism and Hyper-Q features of the “Kepler” family of GPUs, for instance, were only available in the Tesla coprocessors, not in the rest of the Kepler family. Having said that, given the preference for inexpensive compute at single precision among the hyperscalers that are driving machine learning these days, it seems likely that the GeForce line will support FP16 processing as an inexpensive option. Not all GPUs will support the NVLink point-to-point interconnect in the Pascal family, either. It would not be surprising to see Pascal cards with NVLink for dual-GPU workstations and with four or eight connections between GPUs for compute farm nodes.

Huang did a little rough math to explain how the future Pascal GPUs would excel compared to the Maxwell GPUs when running deep learning applications, saying once again to expect around an order of magnitude more performance using his “CEO Math” rough approximations.

The comparison above is interesting because it shows the effects of the FP16 instructions, the 3D stacked memory, called High Bandwidth Memory (HBM) developed by AMD and Hynix, and NVLink all added up and relating to the deep learning applications that Nvidia is counting on to push its Tesla business to the next level. At last year’s GTC event, when Nvidia rejiggered its GPU roadmap, the company pushed out the hardware-assisted unified memory that was expected with the Maxwell GPUs to the Pascal GPUs. At the time, Huang also said to expect that by 2016, when Pascal is expected to ship, Nvidia could deliver 1 TB/sec of memory bandwidth on the GPU, roughly 4X that of the Maxwell GPUs.
In his keynote address this year, Huang said that the Pascal GPU would have twice the performance per watt as the Maxwell GPU, and added that the Pascal card would have 32 GB of this HBM memory on the card (it is not 3D, strictly speaking, but what is referred to as 2.5D, with memory chips jammed side-by-side very tightly). That is a factor of 2.7 increase in memory, and he added that the FP16 would double the instructions and that the memory bandwidth would increase by a factor of 3X, so the resulting instruction bandwidth into and out of memory would increase by a factor of 6X. Average it all out over the various stages of deep learning, when neural nets are learning and refining their models, customers should expect a 5X improvement in performance on deep learning applications. That performance improvement assumes that the final weighting stage of the machine learning application can make use of NVLink interconnect on a machine with four GPUs sharing their HBM memory. Huang hinted that the Pascal-based machine with would deliver a 10X improvement when it shifted to eight GPUs in a single NVLink cluster.
Not everyone will necessarily go the Tesla route with deep learning applications. The GeForce Titan X card, based on a Maxwell chip with 7.1 teraflops of single precision math on its 3,072 CUDA cores, costs a mere $999. A follow-on Titan X card based on Pascal, which will no doubt come to market, will deliver twice the performance per watt, generally speaking, and so will have even better bang for the buck. If FP16 instructions are supported on Pascal variants of the Titan X cards and NVLink does not help so much on certain portions of the deep learning algorithms, it is possible that companies will even go so far as to build hybrid systems using a mix of different styles of Pascal GPUs within their systems.
The one thing that Nvidia did not launch today was a Maxwell-based Tesla coprocessor card, and Sumit Gupta, general manager of the Tesla GPU Accelerated Computing division at Nvidia, did not comment on when or if the company would get such a device into the field. We are beginning to think, based on an OpenPower roadmap that IBM was showing off a week ago, that there never will be a Maxwell Tesla part:

As you can see, the roadmap shows the Kepler GK210 variant of the Tesla card as being part of the OpenPower platform in 2014, with the Pascal GP100 part coming in 2016 and the Volta GV100 coming in 2017. Just because the OpenPower partners are not showing a Maxwell variant of the Tesla does not mean it does not exist. In fact, we have heard of some Maxwell-based Tesla test units that were making the rounds with hardware partners last fall. The message thus far conveyed indirectly by Nvidia is that Pascal is what is coming next the Tesla line.