
Job schedulers that have their heritage in the supercomputing space are used to spreading work out over many server nodes and their underlying CPU cores and running them in batch mode, with parallel programming techniques. The focus is to drive up the utilization of the cluster and get the most jobs through the system in a given time. This type of scheduling does not work well for rapid-fire work that approaches real-time, such as the transaction processing that is commonly done on financial trading platforms.
The Grid Engine job scheduler is one of the most popular tools for scheduling HPC-style work on clusters, and has over 10,000 customers worldwide using either the open source version or a commercially supported variant available from Univa. Grid Engine cluster are designed to scale to 120,000 cores and have over 10,000 server nodes and run around 100 million jobs per month. But sometimes scale means doing lots of small things fast, not doing lots of big things efficiently, and that is why Univa has created a new add-on for Grid Engine called Short Jobs.
“The thing that Grid Engine has done really well is be a general purpose capability of applying policies and resource management to any kind of workload. The gap we had – and this was limited to the high-throughput area of financial services to a large extent – was the overhead of the scheduler. If you have a job that is going to run for a microsecond but it takes it thirty seconds to land it, it is already kind of slow. And this overhead was not just limited to Grid Engine, but also to Platform LSF from IBM, too.”
That is one of the reasons, in fact, that well before IBM bought Platform Computing back in the fall of 2011, that formerly independent company created a high-speed messaging platform called Symphony that was aimed specifically at the low latency, high throughput jobs that dominate the trading systems at financial institutions.
“A couple of financial institutions asked us to create Short Jobs,” Tyreman explains. “But this capability is also interesting to companies that are building microservices that they want to run very quickly, and electronic design automation also has a number of short jobs, too. This short jobs capability is broader than financial services, but it is really our stake in the ground on performance for this kind of work.”
Back in January, when IBM announced Platform Symphony V7.1 for its Power8-based systems, the company said that its benchmark tests on unspecific Power Systems machinery allowed it to push 17,000 tasks per second on these kinds of short jobs. Tyreman tells The Next Platform on its initial tests on X86 systems with a total of 80 cores, it was able to achieve a throughput of 20,000 tasks per second. Univa doesn’t think the Short Jobs extensions to Grid Engine will scale perfectly linearly, of course, and is working with early adopter customers in the financial services sector to see where the performance curve will start to bend.
Workload schedulers like LSF and Grid Engine were designed with supercomputing workloads in mind when they were created nearly two decades ago, and they are still largely playing Tetris across cluster nodes and time, planning when jobs will run in such a way as to maximize throughput through the system and keeping jobs within their specified service level agreements. On long-running jobs like a complex simulation of some physical object or process, which might take anywhere from hours to weeks, an extra couple dozen seconds to get it scheduled in overhead is no big deal. To schedule short jobs running at fractions of a second, Univa’s engineers had to basically turn Grid Engine on its head, deciding where to run short jobs first and then pulling them across the cluster lightning fast to get them done in the blink of an eye. The jobs are done and then next one is coming in before the traditional scheduler would have known what had happened.
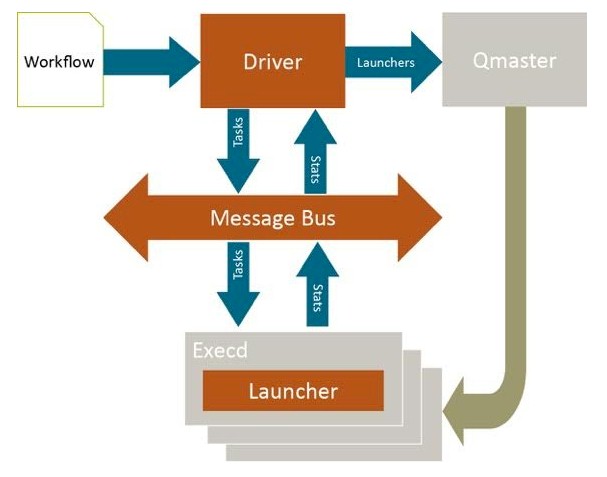
Depending on how busy the Grid Engine scheduler is at any given time, if you tried to do short jobs on the regular Grid Engine, explains Tyreman, you might be able to load up maybe 1,000 jobs per second into the scheduler. Then Grid Engine has to figure out where to put things, make a scheduling decision, and then start the work.
“With Short Jobs, we are packaging up the submission and the scheduling and simplifying that to a single step. The execution side of that, which is now started up and running, is done offline. So the lifecycle startup of the actual application or tasks run on their own and they are managed independently.”
The secret sauce that is part of the Univa commercial release of Grid Engine is a tweaked version of the scheduler in Grid Engine 8.2 that knows the difference between short jobs and batch work and can dispatch them to their own resource partitions on clusters independently.
Tyreman says a key distinction between Platform Symphony and Grid Engine Short Jobs is that the former requires some adaptations to applications and the latter does not to make use of low latency processing. “You can integrate directly through the command line, and a lot of people do using the QSub wrapper that sits atop the message queuing system at the heart of Short Jobs. We treat all jobs the same, and then we figure out that it is an array job that needs a certain number of cores and a specific environment, and we set that up quickly and start attacking it. DevOps doesn’t have to rewrite and test applications. Our approach, then, is to go in and sit beside the Symphony environment, which is needed for very specific types of applications. But the majority of jobs that people are running on Symphony we can handle now with Short Jobs, which makes it look like a batch workload but with very high throughput.”
The message broker back-end on the Grid Engine Short Jobs tool is the Redis key-value store. While Redis is supported on Linux platforms, it is not yet supported on Windows Server and therefore the Short Jobs feature is only supported on Linux clusters at the moment. (Univa added support for Windows with Grid Engine 8.2 last September.) Microsoft’s Open Technologies group is working on a port of Redis to Windows Server, and Tyreman says that as soon as this is ready, Short Jobs will work on Windows-based clusters that are managed by Grid Engine.
Univa has been more aggressive in recent years about expanding the use cases for Grid Engine, beginning with the port to Windows last year and with Universal Request Broker, which Univa announced back in April. Universal Request Broker is a layer of software that lets Grid Engine speak the APIs of Apache Mesos, and the combination of this broker and the new short jobs will allow Grid Engine to schedule long-running work and short jobs concurrently on systems while also hooking into the same microservices frameworks that are being added to Mesos by the open source community.
Mesos is the cluster controller and job scheduling software that was inspired by Google’s Borg tool and created at the AMPLab at the University of California at Berkeley and largely turned into a product by engineers at Airbnb and Twitter. Many of the key people behind Mesos are now working at Mesosphere, the startup that is offering commercial support and enterprise grade add-ons to Apache Mesos as it tries to bring the Google Way to the Global 2000.
Tyreman says that Univa is working on adding software container support to Grid Engine, and expects for the company to have support for Docker containers, created by the company of the same name, and rkt containers, created by CoreOS, both schedulable through Grid Engine by the early fall.
The base Grid Engine 8.2 costs $100 per core per year to license, and the Short Jobs add-on costs $50 per core per year. This is the same price that Univa is charging for the Universal Request Broker add-on. Univa does not expect for most companies to put all three tools across all their cores in this clusters, but over time, depending on industries and workloads, customers could have the broker for Mesos frameworks on a third of the cores and Short Jobs on anywhere from a quarter to half the cores. So a typical customer will be spending somewhere between $150 and $175 per core per year, on average at list price. (Customers in the real world get volume discounts, of course.) IBM, by contrast, is charging $625 per core for a perpetual license to Platform Symphony Advanced Edition V7.1 on its Power platforms. That perpetual license to Symphony includes one year of software support.


Four Essential Strategies To Avoid HPC Cloud Lock-In
(Sponsored Content) HPC workloads are rapidly moving to the cloud. Market sizing from HPC analyst firm Hyperion Research shows a dramatic 60 percent rise in cloud spending from just under $2.5 billion in 2018 to approximately $4 billion in 2019 and projects HPC cloud revenue will reach $7.4 billion in …

Time Is Always Money, Especially With HPC On The Cloud
Systems management has always been in a race to catch up with the innovation in systems, and it is always nipping at the heels. As systems have gotten more complex, first by expanding beyond a single chassis into clusters of machines operating in concert and then by adding progressive layers …
Understanding And Balancing HPC On-Premises And In The Cloud
HPC shops are used to doing math – it is what they do for a living, after all – and as they evaluate their hybrid computing and storage strategies, they will be doing a lot of math. And a lot of experimentation. And that is because no one can predict …
Be the first to comment