



For those in enterprise circles who still conjure black and white images of hulking supercomputers when they hear the name “Cray,” it is worth noting that the long-standing company has done a rather successful job of shifting a critical side of its business to graph analytics and large-scale data processing.
In addition to the data-driven capabilities cooked into its XC line of supercomputers, and now with their DataWarp burst buffer adding to the I/O bottom line on supercomputers including Cori, among others, Cray has managed to take supercomputing to the enterprise big data set by blending high performance hardware with tuned software packages. At the core of the company’s enterprise data analysis offerings is the Urika line, which launched a few years ago and just today had a public refresh with the announcement of the Urika GX. The new system builds on top of the capabilities of the previous generation, the Urika GD, which has been used in a diverse array of settings from research to big government to Major League Baseball—all areas that can benefit from its engineered systems approach to graph analytics.
Going back to the historical (and current) fact that Cray is a supercomputer engineering company, recall that one key differentiator of their systems is the Aries interconnect with its ultra-high bi-section bandwidth and minimal number of hops between nodes. This is important for large-scale supercomputers, and as one might imagine given the nature of graph traversals, also critical for graph analytics workloads. Aries further makes it easier to extend a cluster without rerouting the entire topology of the cluster physically, which means putting together an ever-larger graph analytics beast is potentially easier without big sacrifices to performance.

The partitioned globally addressable memory system that is part of the XC line is also the foundation for the Cray graph engine. This takes advantage of the Aries interconnect and its ability to provide one big addressable memory space, which is at the root of how the graphs are partitioned and distributed across many nodes, which allows for some of the most complex queries to fit.
While it “only” scales to 48 nodes and isn’t using the full scalability of Aries, it is a single rack configuration that is more sufficient than the size of the larger problems that are out there. It is possible for graph analytics workloads to run on something like an XC40 supercomputer for better price performance (at least according to Waite) there are a few issues with this for customers who are tackling some of the world’s largest and most challenging graph-based problems. One is, quite simply, packaging. Customers in the enterprise space want standard 19-inch racks and server sleds, which are not used with the XC40 and further, they want to get up and go with such a machine without worrying about the various dependencies in software. In short, they want massive scale, out of the box graph analytics—something its customers in government, research, and industry are looking to push with their upgrades from the Urika GD—and that Cray hopes will find favor with new customers in some of the hottest areas they see, most notably, cybersecurity.

One can argue that the first push for the Urika graph analytics appliance was simply showing how and where high performance graph analysis could be useful. For this new generation of Urika appliances, which Cray says offers a 3X improvement over the Urika GD, the case is clearer, but the way graph analysis has been handled at many shops; from those in the life sciences, to network intrusion detection, and intelligence, has created a “Frankencluster” problem, according to Ryan Waite, Cray’s product manager for the Urika line.
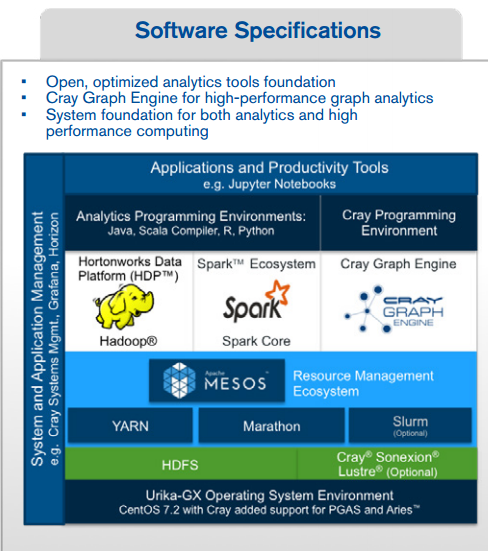
Of related interest is the fact that Waite has seen firsthand the problem of multiple clusters juggling many different workloads when a single platform would have been the most efficient solution. Prior to joining Cray, he managed the Data Services group at Amazon Web Services, where he built the Kinesis streaming data service (useful for IoT workloads), operated the data warehouse with its billion records per day, and managed other services that relied on separate buckets for individual workloads. Further, he says, even for users who can manage to push all of the ETL and other platforms onto a singular system, getting it up and running with all the OS, system management, and other platform-related tools can be a bigger challenge than one might expect, especially with potential version and other conflicts inherent to such a task.
This is the real value proposition of the newest Urika system—and it’s a message existing Urika GD users are taking to heart as Waite says many buyers for this system might have already had the previous system, have grown to love its capabilities, but need more capacity, capability, and a single platform focus.
“With the Cray Urika-GX, we had quality score recalibration results from our Genome Analysis Toolkit (GATK4) Apache Spark pipeline in nine minutes instead of forty minutes,” said Adam Kiezun, GATK4 Project Lead at the Broad Institute. “This highlights the potential to accelerate delivery of genomic insights to researchers who are making breakthroughs in the fight against disease.”
Cray has tested the new appliance using several benchmarks to come up with 3X improvement number over the Urika GD, which is no surprise given the fact that the Aries interconnect, albeit in stripped-down version, is featured on this machine. In details shared with The Next Platform, they also ran PageRank on the new system, although compared it to an indeterminate number of cloud-based HPC instances, which by its very nature incurs some latency hits. It will be interesting to see how future customers’ own workload hum on this system versus their previous Urika GD appliances–and even more interesting to hear what new problems, which were too big to fit inside standard database approaches to analytics or other graph approaches, might be solved.
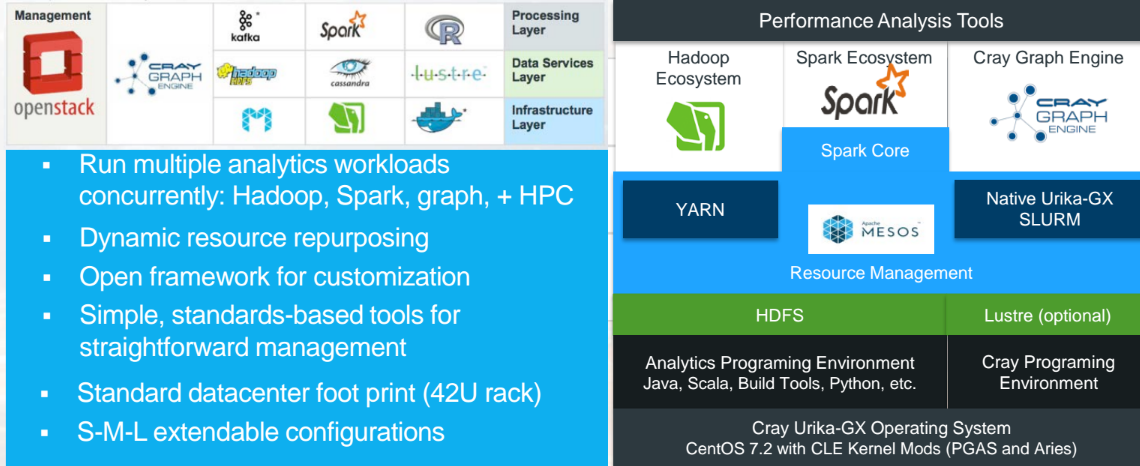
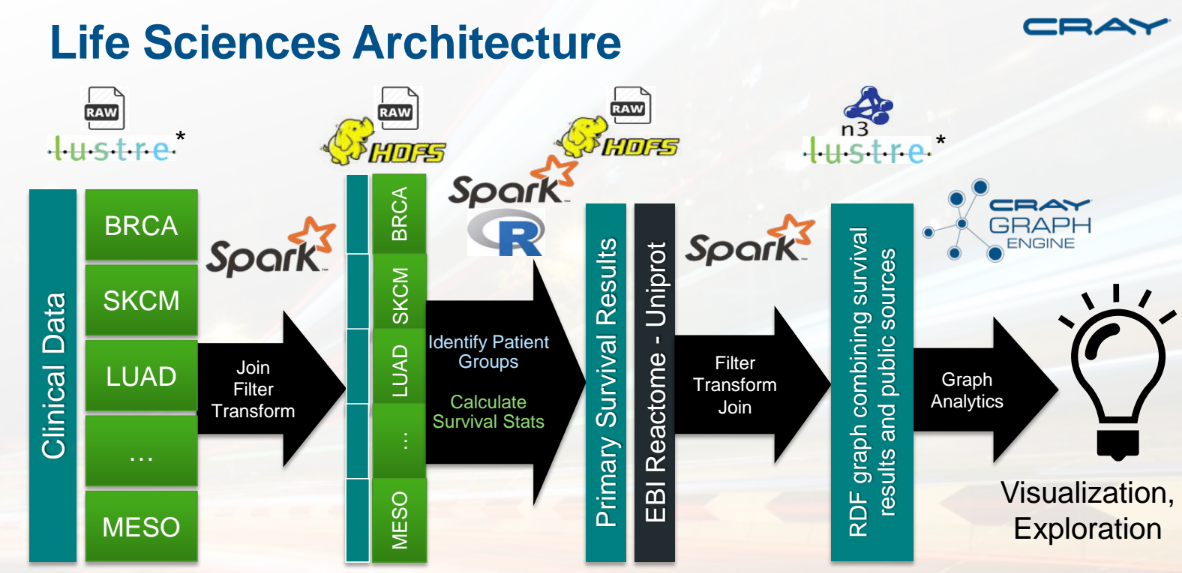
Match the above with the real-world use case from one of the company’s life sciences customers, which formerly had many clusters for many jobs. The entire workflow below can now be seamlessly managed on a single machine—something that Waite says adds to overall utilization and lower costs ultimately.
The machine will be available in the third quarter of 2016. While pricing specifics have not been shared, one can expect the Aries interconnect (even in a stripped-down version) and extra software footwork to add to the bottom line.