

When we cover the bi-annual listing of the world’s most powerful supercomputers, the metric at the heart of those results, the high performance Linpack benchmark, the gold standard for over two decades, is the basis. However, many have argued the benchmark is getting long in tooth with its myopic focus on sheer floating point performance over other important factors that determine a supercomputer’s value for real-world applications.
This shift in value stands to reason, since larger machines mean more data coursing through the system, thus an increased reliance on memory and the I/O subsystem, among other factors. While raw floating point peak performance is a competitive fuel, for those engaged in scientific computing at scale, determining what makes a machine valuable is far more nuanced.
To answer demands from supercomputing sites that a metric be developed that emphasizes data movement over sheer number crunching peak potential, Dr. Jack Dongarra (one of the original founders of the Linpack benchmark and Top 500 list of supercomputers) and Sandia National Lab’s Michael Heroux developed the High Performance Conjugate Gradient (HPCG) benchmark, a companion metric to balance perspectives on performance that is a growing companion to the more widely-known Linpack results.
If there was ever a time when the value of such a benchmark could be clearly seen it was with today’s announcement of the latest Linpack Top 500 results that put the apparently spectacular performance of the new Sunway TaihuLight supercomputer into clearer focus. This system made world headlines this week with its dramatically superior performance that shatters the performance record for supercomputing by a long shot. Performance and architectural details on that machine can be found here, but most of that discussion is based on its performance on the Linpack benchmark. As it turns out, HPCG and its focus on real application patterns, tells another story.
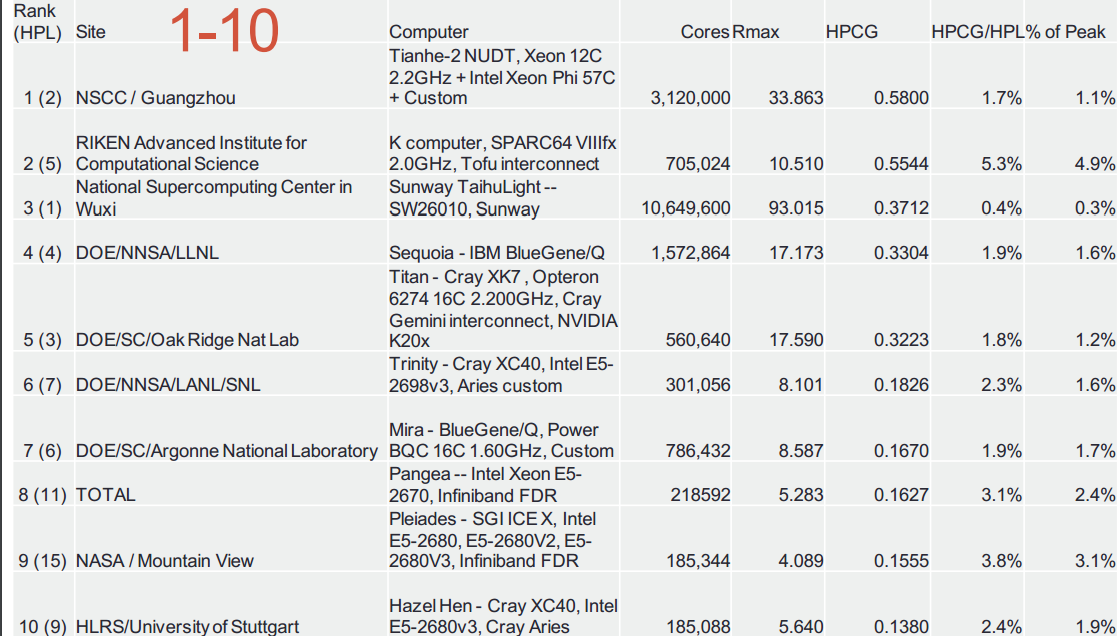
While the TaihuLight supercomputer rocked the Top 500 supercomputer list, its performance on HPCG showed that it is getting just .3% system utilization based on the theoretical peak. That does not sound good, but remember that even the other systems on the list are getting between 2-3% percent at the top, with Japan’s K Computer showing the highest percent of that theoretical peak potential’s actual utilization at 4.9%.
To preface the HPCG results as they relate to the new Chinese top supercomputer, however, we should note that even though TaihuLight shows rather abysmal performance on HPCG, this does not necessarily mean it is a stunt system (as some thought the former top Chinese supercomputer, Tianhe-2 was, to some extent). While the metrics from HPCG are not great, the system’s value has been demonstrated in other real-world application contexts, most notably because the system is used for three Gordon Bell prize finalists. That award goes to teams who can use as much of a supercomputer’s cores as possible for actual scientific applications. And in high performance computing, an award like this takes serious scrutiny for both the scientific value, the application’s scalability and complexity, and of course, the validation that the science being done at scale is doing so on a machine that was designed for real HPC versus toppling the Top 500 charts.
The top ten listing for HPCG seen above makes handy reference to the peak Linpack performance for balance. Of the 500 supercomputers that make the Linpack-based Top 500 list, the newer HPCG benchmark had over 80 participants, a number that Heroux tells The Next Platform will continue to grow. Not only will there be more submissions, but with the arrival of new processors on an increasing number of systems, most notably Knights Landing (which will be on the Trinity machine at Los Alamos National Lab in time for SC16—not to mention on several other top 50 supercomputers), it will also offer a richer set of results to understand potential application performance potential—blended with Linpack results, of course.
What is most interesting is that if you take the Linpack results versus HPCG, some systems, like the Sunway machine, are far slower,” Heroux says. “We don’t have a lot of information about that system still, so it is hard to pinpoint why this is, but you can see other examples of this where there is a high Linpack ranking that is quite a bit different from what we see in HPCG.”
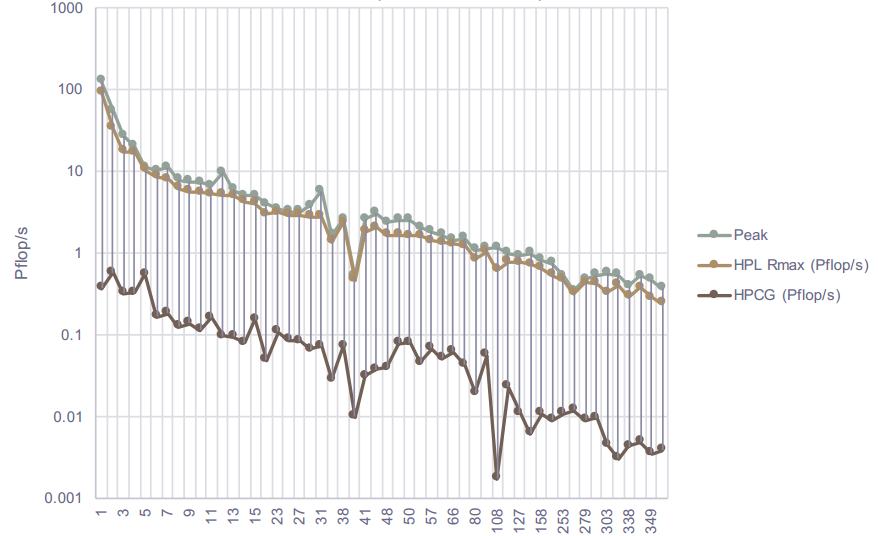
If you take a look at the chart, it shows clearly this disparity in theoretical peak performance versus the actual application-like benchmark approach of HPCG. This is why, as Heroux stressed, HPCG has great value for the supercomputing community as a “book-end” with Linpack showing the highest performance possible from a sheer number-crunching standpoint, and HPCG showing how that translates for a representative benchmark that measures against actual application patterns. It is dangerous to think that one or the other is more important as a standalone metric, Heroux stresses, because they measure different things and in some cases, machines are designed to do a few things very well versus serve a range of many different workloads.
Although the Sunway TaihuLight machine is apparently doing a few applications exceptionally well given its Gordon Bell submission status (with an unheard of 3 finalists for one system) it still lacks the comprehensive base of parallel applications based on X86 architectures (and to a lesser extent BlueGene, SPARC, and others). For now, the best real sense of how useful it might be for real scientific applications remains to be seen. However, given its ranking on HPCG, the Linpack results, which blew everything else far out of the water, should still be taken with a tiny grain of salt since those numbers are theoretical peak.
Another point to consider when looking at HPCG against the Linpack results is that some architectures seem far better suited for real application performance as measured by this metric. Most notable here is the Fujitsu Sparc64-based K Computer, but as we learned this week (and have a mightily in-depth piece in the works now about) that will soon be Sparc-like with the Tofu interconnect (key to the utilization results of note above) but using ARMv8 as the core processor. It will be interesting to see how such a shift alters both the Linpack and HPCG results, but there is plenty of time between now and that machine, set to appear in 2019, a date confirmed yesterday when The Next Platform sat down with Satoshi Matsuoka.
All eyes are on Linpack and the Top 500 benchmark this week with the summer listing of Top 500, at least as far as the mainstream press is concerned. But in our conversations here on the floor at ISC 16 this week, many more people are talking about that interesting mixed message of top Gordon Bell prize contenders from that Sunway machine and the HPCG results. Ultimately, this is all a very good thing for the HPCG benchmark group, which is at the front of many more conversations than ever before in terms of its value going forward.


Nvidia’s “Grace” Arm CPU Holds Its Own Against X86 For HPC
In many ways, the “Grace” CG100 server processor created by Nvidia – its first true server CPU and a very useful adjunct for extending the memory space of its “Hopper” GH100 GPU accelerators – was designed perfectly for HPC simulation and modeling workloads. And several major supercomputing labs are putting …

Real-World HPC Gets the Benchmark It Deserves
While nothing can beat the notoriety of the long-standing LINPACK benchmark, the metric by which supercomputer performance is gauged, there is ample room for a more practical measure. It might not garner the same mainstream headlines as the Top 500 list of the world’s largest systems, but a new benchmark …

The Nitty Gritty Of The Sunway Exascale System Network And Storage
We took a look recently at the compute engines at the heart of the future – and as yet unnanmed – Sunway exascale system that will be installed at the National Supercomputing Center in Wuxi, China. This exascale machine will be a follow-on to the current Sunway TaihuLight system, both …
Another very interesting benchmark is HPGMG : https://hpgmg.org/