

In many ways, enterprises and hyperscalers have it easy. Very quickly in the wake of its announcement more than two decades ago, the Java programming language, a kind of virtualized C++, became the de facto standard for coding enterprise applications that run the business. And a slew of innovative storage and data analytics applications that have transformed computing were created by hyperscalers in Java and often open sourced so enterprises could use them.
The HPC community – and it is probably more accurate to say the many HPC communities – has it a bit tougher because they use a variety of C, C++, and Fortran applications across an increasingly diverse set of compute elements, including several kinds of manycore processors and various accelerators that are based on GPUs, FPGAs, and DSPs. One tool does not yet span all of these different options, and perhaps it never will. But the OpenACC community, which was founded by Cray, PGI, Nvidia, and CAPS back in November 2011 to deliver a common way to put parallelization directives into code for compilers, has made great progress along with other organizations with a vested interest in HPC code portability and acceleration on various processors and coprocessors, to realize this goal. At the upcoming SC16 supercomputing conference, which occurs next week, the OpenACC community will be talking about its progress and also hosting meetings to try to get the OpenMP and OpenACC community members together to talk about how they can work together despite the very different ways in which their approaches express parallelism in code.
To get a head start on SC16, Michael Wolfe, technical chair for OpenACC and the technology lead at compiler maker The Portland Group, which graphics chip maker Nvidia acquired in July 2013, and Duncan Poole, president of OpenACC and partner alliances lead at Nvidia, sat down with The Next Platform to give us a sense of the progress that has been made in helping to make parallel code easier and more portable.
Poole says that a number of big production applications in the HPC space have tapped OpenACC compilers so they can run in a hybrid CPU-GPU environment, and he adds that frankly sometimes the OpenACC community does not know that such work is being done until the code change is imminent or has already been done. One of the big ones being announced at the SC16 conference are Gaussian, which is using OpenACC to port the future G16 release of its quantum chemistry application to ceepie-geepie machines. Poole says that Gaussian is probably the most popular computational chemistry application in use today, but the Fluent computational fluid dynamics application is also very popular. (The do different things in a broad chemical field.) The good news is that Fluent has supported offloads to GPUs for years (since R15 and is at R17.2 now) and is now going to employ OpenACC to improve the performance of CPU-GPU hybrids with its future R18 release. Gaussian and Fluent are used by all kinds of industries as well as by academic researchers and government HPC centers. This is not a science project, but actual science and engineering.

In addition, Oak Ridge National Laboratory, which helped form the OpenACC community five years ago specifically because it wanted to have a consistent approach to programming on multicore processors and CPU-GPU combinations, will announce that five of the thirteen applications available under its Center for Accelerated Application Readiness (CAAR) program will be redesigned, ported and optimized using OpenACC on the future “Summit” system being commissioned by the US Department of Energy that is expected to be installed at Oak Ridge about a year from now. Considering that the machine will be based on hybrid IBM Power9 and Nvidia “Volta” Tesla compute elements, this does not really come as much of a surprise.
It will perhaps be surprising to some that the Sunway TaihuLight supercomputer built by the Chinese government for the National Supercomputing Center in Wuxi has joined the OpenACC effort. The TaihuLight supercomputer is based on custom ShenWei 26010 processors, which have 256 skinny cores, called Compute Processing Elements (CPEs), and four beefy ones, called Management Processing Elements (MPEs), and this presents a kind of on-chip offload model challenge for application developers. So researchers in Wuxi, who have had a production machine running since the summer, are working with OpenACC to not only use its offload model, but to drive changes in the standard that allows it to work better on its system.
“The TaihuLight system uses a highly parallel node, and a lot of nodes,” explains Wolfe. “They have support for OpenMP, but they wanted to do OpenACC because there is a lot less legacy overhead. OpenMP has a lot of synchronization constructs, which is very flexible for the programmer but when they use those, it is slowing down the highly parallel applications. When they run a parallel loop, they launch on the CPEs, but they wanted the MPEs to participate in that and the OpenMP offload model did not allow for that, whereas OpenACC was more flexible. They have a mesh interconnect and they have memory bandwidth issues that they have to deal with as well, which is a big part of their optimization.”
PGI has been working on OpenACC support for Power8 processors operating in standalone mode as well as in hybrid CPU-GPU mode for some time, and is announcing that this work is done. The PGI 16.10 releases have the Power8 support, and set the stage for next year’s Power9 chips. PGI expects to have support for Intel’s “Knights Landing” Xeon Phi processors with its compilers sometime in 2017. PGI does not plan to back support earlier “Knights Ferry” and “Knights Corner” Xeon Phi chips, by the way.
Last year, PathScale tweaked its compilers to speak OpenACC for multicore ARM processors, and ARM Holdings itself worked with Numerical Algorithms Group for two years to port the latter company’s Fortran compiler and related Numerical Library to the 64-bit ARMv8-A architecture, and at last year’s SC16 conference announced that it was licensing this software from NAG to give to HPC developers. PGI knows that it has to eventually support many core ARM processors as well as ARM-GPU hybrids for its compilers, and there are plans to do this but it has not been staffed as yet, Wolfe says.
But that’s not all. The GCC community will be showing off the work that has been done to support the OpenACC framework in the GCC 6 compilers, and is also expected to talk a bit about what is likely to be introduced in the GCC 7 compiler suite. “Every generation of the GCC compilers is evolving the performance, and I think that is starting to get interesting,” says Poole.
“We often get accused of being an Nvidia organization, but the reality is that there are compilers coming from PathScale, Cray, PGI, the open source GCC community, and now Sunway,” Poole adds. “And there are a bunch of research compilers that are exploring what it means to do offload and using different memory models.” This includes the Omni compiler project at the University of Tsukuba in Japan, the OpenUH compiler at the University of Houston, the OpenARC compilers at Oak Ridge, and the RoseACC compilers at the University of Delaware and Lawrence Livermore National Laboratory.
Allinea, Nvidia, and RogueWave Software all have debuggers and profilers available that know how to speak OpenACC, too.
How Much Dark HPC Code Is There?
The desire to have GPU acceleration across different types of CPUs is driving all of this, and it is no surprise that key HPC applications are supporting the CPU-GPU model using OpenACC. Here is a list of the applications, by field, that have made the move to OpenACC in the past year:

When we asked what kind of penetration OpenACC has across the entire spectrum of HPC applications, it is very difficult to come up with a number of the total number of applications out there and to also know how is using OpenACC tools to either modernize them or create them new from scratch.
“Some of the labs have code that we don’t know about for obvious reasons,” Wolfe says. “My guess is there is going to be a number of codes, particularly in the academic world, where they are experimenting. But the lifetime of a code like that is the lifetime of a grad student. They are going to hand that off to a professor, and a new student is going to come along and do something different. And if there is something that is really great, then it is going to end up in community code.”
“I would give a slightly different answer,” says Poole. “Grad students come in and they work on code that some professor wrote ten years earlier. And they may do something very similar to code that is created at another university. But they are used to working with this, and they keep going with their code, and if that user base is not particularly high, then it falls below the radar for tracking purposes. Domain by domain, this tendency is either larger or smaller. In molecular dynamics, there are a bunch of relatively well known codes that are the ones to go to. But with genomics, it is the algorithms that are known, not so much the codes, and these plug into frameworks.”
And, of course, it is the frameworks that need to support OpenACC if they want to run in hybrid mode.
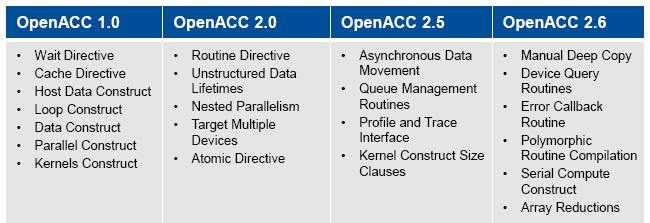
The current specification of OpenACC is at the 2.5 release, and different compiler stacks have different levels of compliance with the spec. (Wolfe says the PGI compilers are compliant with most of the OpenACC 2.5 specs.) The updates to OpenACC are entirely user driven, says Wolfe, and there are a dozen or so slated for the 2.6 update, which is expected to be done by the middle of next year, and it probably won’t be called OpenACC 3.0, as was the plan for the update that was slated for the end of this year and which we outlined back in March. This change in naming will probably confuse more than a few folks, but the important thing is that features such as deep copy, which have been in demand by users for quite some time, are coming to the OpenACC spec.


MGX: Nvidia Standardizes Multi-Generation Server Designs
Updated With More MGX Specs: Whenever a compute engine maker also does motherboards as well as system designs, those companies that make motherboards (there are dozens who do) and create system designs (the original design manufacturers and the original – get a little bit nervous as well as a bit …
Copper Wires Have Already Failed Clustered AI Systems
It has become a well known fact these days that the switches that are used to interconnect distributed systems are not the most expensive part of that network, but rather it is the optical transceivers and fiber optic cables that comprise the bulk of the cost. Because of this, and …

Using AI Chips To Design Better AI Chips
Chip design is as much of an art as it is an engineering feat. With all of the possible layouts of logic and memory blocks and the wires linking them, there are a seemingly infinite placement combinations and often, believe it or not, the best people at chip floorplans are …
Be the first to comment