

The Zettabyte File System (ZFS), as a back-end file system to Lustre, has had support in Lustre for a long time. But in the last few years it has gained greater importance, likely due to Lustre’s push into enterprise and the increasing demands by both enterprise and non-enterprise IT to add more reliability and flexibility features to Lustre. So, ZFS has had significant traction in recent Lustre deployments.
However, over the last 18 months, a few challenges have been the focus of several open source projects in the Lustre developer community to improve performance, align the enterprise-grade features in ZFS with Lustre, and enhance functionality that eases Lustre deployments on ZFS. These features are being added to open source Lustre (Intel Foundation Edition for Lustre* software) and the Intel Enterprise Edition for Lustre software (Intel EE for Lustre software).
ZFS has capabilities of a back-end file system to Lustre that are sought after by IT architects. Enterprise IT is especially interested for the file system’s many features of reliability and availability, such as end-to-end checksum and on-block data corruption protection. As hard drives continue to increase in size, data protection becomes more critical to data center architects building Lustre clusters. ZFS also provides effective snapshotting, compression, and scrubbing and silvering without taking the system offline, which keeps the data available to clients 24/7 while providing high reliability. For system integrators, ZFS, with its own RAID feature called RAIDZ, allows them to build JBOD-based storage solutions instead of more expensive hardware-based RAID arrays. With this rich pool of features that more organizations look for in a high-performance parallel file system, over the last year and a half the Lustre open source community has continued to work on enhancing ZFS for Lustre deployments. The most recent work includes:
- Improving RAIDZ performance
- Enabling snapshots directly from Lustre
- Boosting Metadata performance
- Improving streaming I/O performance
- Enhancing high availability using Pacemaker and Corosync
80X Faster RAIDZ3 Reconstruction
Gvozden Nešković, working with the Gesellschaft fuer Schwerionenforschung (GSI) and Facility for Antiproton and Ion Research (FAIR), committed a patch to the ZFS master branch that boosts performance of RAIDZ parity generation and reconstruction for its various levels of data protection called RAIDZ1, RAIDZ2, and RAIDZ3. These levels cover the number of possible ZFS pool hard drive failures that can occur (one, two, or three drives) and still recover the data in the pool. The calculations for parity generation and reconstruction use Galois field equations and vary in complexity from simple carryless addition to complex, complex, finite field algebra constructs. “Modern multi-core CPUs do not have built-in instructions to perform these operations,” said Mr. Nešković, “so I had to revise and optimize the operations to take advantage of the vector instruction sets in today’s CPUs.” Running his new codes on benchmarks returned over 80X speedup on RAIDZ3 reconstruction of three hard drives using the Intel AVX2 instruction set on Intel processors, such as Intel Xeon processors E5 family.
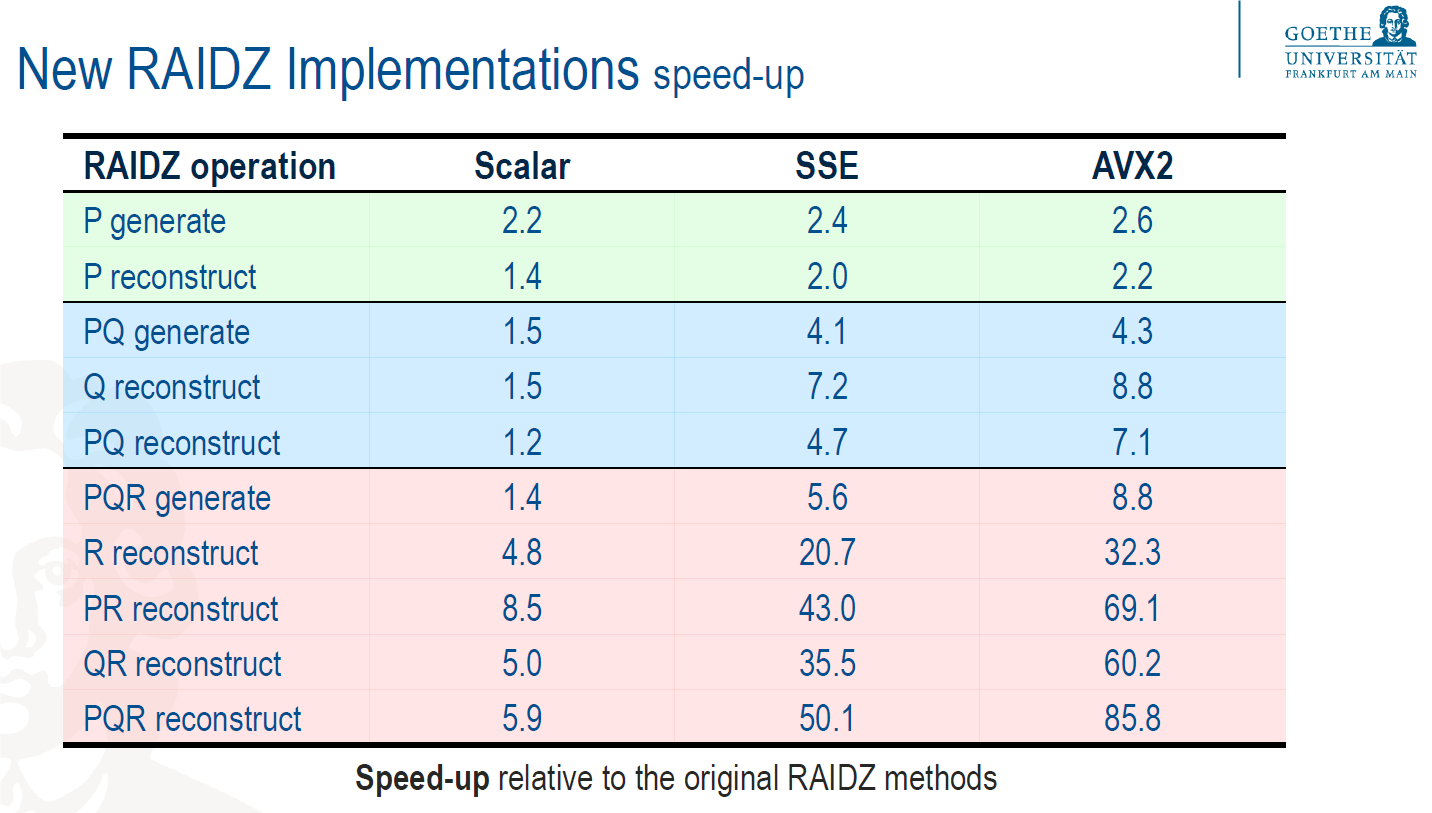
“Codes are based on the vector extensions of the binary Galois field,” stated Nešković. “This is finite field mathematics with 256 elements.” Erasure code is specified by three basic equations for the parity, called P, Q, and R. Regeneration has the most processing demand, depending on the failure mode of RAIDZ level and number of involved hard drives. RAIDZ3 with three drive failures requires solving all three equations in seven different ways to regenerate all data blocks.
Mr. Nešković’s work covered both optimizing all the equations and implementing new constructs. The table shows speedup results compared to the original, unoptimized code running his optimized versions of the original code on a scalar processor and running vectorized operations on SSE and Intel AVX2-enabled processors. “I built new optimized code on top of an optimized RAIDZ framework.. My work focused on x86 processors, but the framework can be extended to other architectures. Others in the community are already working on extending it,” he commented.
“What this means to GSI is that we can dedicate fewer cores to parity and reconstruction processing, and that saves costs building and running of Lustre clusters with a ZFS back end file system using RAIDZ for high availability and reliability,” added Nešković. His presentation on his work at the Luster User Group (LUG) can be found here; the video of it is here.
Creating Lustre Snapshots
Fan Yong of Intel’s High Performance Data Division (Intel HPDD) is adding ZFS snapshot capability using command lines to Lustre with ZFS back end file systems. Lustre snapshots create a mountable view of the entire Lustre filesystem captured at a moment in time. Snapshots are useful for a number of reasons, from recovering files to creating backups to enabling users to see differences across the data over time, and more.
The process of creating the snapshot is very fast, because it takes advantage of a copy-on-write file system, rather than copying the entire file system’s data. The snapshot is given its own unique fsname, which can be mounted as a read-only file system. “Creating the snapshot is fast,” stated Fan Yong. “Setting up the system to do that is time consuming, because we have to create a global write barrier across the pool.” The barrier freezes the file system by preventing transactions on the Metadata Targets (MDTs), inhibiting any changes to Metadata during the snapshot. “In theory, this sounds simple,” stated Yong. “Efficiently implementing it is not.”
Yong’s research and benchmarks show that while the write barrier can take several seconds to complete, it is highly scalable across their test system with little change as the number of MDTs are added. And the impact on MDT IO performance is minimal, making the wait for the snapshot very worth the value of having a complete picture of the file system at a given moment in time.

The snapshot capability is being added as command line routines to Lustre that in turn execute commands on both the Lustre and ZFS environments.
Yong’s work is multi-phasic and ongoing. Phase 1 with snapshotting capability is expected to land in the community release of Lustre 2.10 and in the Intel Enterprise Edition for Lustre software version 3.0. Future work will integrate additional capabilities, such as auto-mounting the snapshot, and other features. Yong’s presentation at LUG 2016 can be found here, and the vide of it is here.
Making Metadata Performance Scalable and Fast
Alexey Zhuravlev of Intel HPDD has contributed valuable improvements to Metadata performance on ZFS. Lustre’s ldiskfs has been an order of magnitude faster than ZFS, much of it due to the Metadata server performance, which on ZFS is both much slower than ldiskfs and not scalable. Thus, to enable ZFS deployments, some integrators mix back end file systems with Metadata servers based on ldiskfs and object servers based on ZFS. Mr. Zhuravlev’s work so far has shown Metadata performance increases as much as 2x on ZFS 0.6.5.7, which is good news for ZFS installations.
“There are several areas where bottlenecks occur,” stated Zhuravlev. “Some are due to Lustre code and some due to ZFS.” Declaration time is a significant one, where ldiskfs is a mere fraction of time compared to ZFS for all declaration operations. “The more specific the declaration, the more expensive it is on ZFS,” added Zhuravlev. And Lustre declarations are very specific, which, it turns out, are not required. Lustre patch LU-7898, which landed in Lustre 2.9, brings ZFS declaration times in line with ldiskfs.
ZFS dnodes also presented a performance challenge to Lustre. ZFS 0.6.5 dnodes are 512 bytes, which are not nearly large enough to accommodate Lustre’s extended attributes. ZFS’ two extra 4k blocks include a spill block for additional data, but accessing the spill block results in an extra disk seek. “It took more than eight gigabytes of raw writes to create one million files,” commented Zhuravlev. A patch for a variable dnode will be landed in the ZFS master 0.7 release that will allow dnodes to be sized from 512 bytes to a few kBs, eliminating the need to look at the spill block, which is expected to reduce the disk seeks by half. “With large dnode support in ZFS and Lustre, 1 million files now take only one gigabyte of raw writes,” added Zhuravlev. Additionally, ZFS didn’t support dnode accounting, and Lustre implements its own primitive support for file quotas, which is very expensive and doesn’t scale well. Patch LU-2435, which is nearly ready for landing, will add native dnode accounting to ZFS. “We estimate performance on dnode accounting will be both highly scalable and higher performance,” stated Zhuravlev.
Fixes to declaration times (Lustre 2.9), dnode size increase (ZFS 0.7), and dnode accounting (Lustre 2.10) are showing significant improvements to MDS performance on ZFS, delivering both high scalability and performance that is expected to pass ldiskfs. These features will appear in the upcoming release of Intel Enterprise Edition for Lustre software.
“We continue to work on MDS performance on ZFS,” added Zhuravlev. We are actively looking at other optimizations and working the upstream ZFS community.” He presented his work at the European Open File System’s (EOFS) 2016 Lustre Administrator and Developer Workshop. His presentation is here.
Large IO Streaming Improvements
Write performance of Lustre on ZFS runs near to its theoretical maximum, but block allocation is not file-aware, so it tends to scatter blocks around the disks, which means more disk seeks when he file is read back. This keeps read performance lagging Lustre’s write performance on ZFS as presented at LUG 2016 by Jinshan Xiong of Intel’s HPDD. A lot of patches have been landed during 2015 that has helped performance on ZFS, including Xiong’s vectorization for Intel AVX instructions of the Fletcher 4 algorithm used to compute checksums. Work continues to enhance IO performance.
IO performance work at Intel is being done and upstreamed to the ZFS on Linux project with expectations to be landed in Lustre 2.11. This work includes
- Increasing support on Lustre for a 16 MB block size—already supported by ZFS—which will increase the size of data blocks written to each disk. A larger block size will reduce disk seeks and boost read performance. This, in turn, will require supporting a dynamic OSD-ZFS block size to prevent an increase in read/modify/write operations.
- Implementing a dRAID mechanism instead of RAIDZ to boost performance when a drive fails. With RAIDZ, throughput of a disk group is limited by the spare disk’s bandwidth. dRAID will use a mechanism that distributes data to spare blocks among the remaining disks. Throughput is expected to improve even when the group is degraded because of a failed drive.
- Creating a separate Metadata allocation class to allow a dedicated high throughput VDEV for storing Metadata. Since ZFS Metadata is smaller, but fundamental, reading it faster will result in enhanced IO performance. The VDEV should be an SSD or NVRAM, and it can be mirrored for redundancy.
Mr. Xiong’s presentation from LUG 2016 can be seen here. The video of it is here.
New Resource Agents for Lustre
Additional to performance improvements for ZFS, Gabriele Paciucci, HPC Architect for Intel, released patches to the Lustre main branch for enabling the Linux Pacemaker* and Corosync* high availability framework for Lustre on ZFS. Previously, Lustre’s use of Pacemaker and Corosync* was only supported on ldiskfs. Paciucci’s work introduces three new resource agents released in the following patches:
- LU-8455 supports Pacemaker on a ZFS-based file system.
- LU-8457 increases monitoring capabilities for LNet.
- LU-8458 increases monitoring capabilities for Lustre services.
His work was presented at LAD 2016, and it can be viewed here.
With critical features enterprises and other modernized data centers need, ZFS as a back end file system for Lustre is already being used in many deployments. The Lustre community continues to enhance performance across Lustre and ZFS to close the gap between ldiskfs and ZFS.


A 35 Petabyte All-Flash Balancing Act
Last week, we introduced the Perlmutter supercomputer, the next-gen system at NERSC that will likely secure the #5 spot on the Top 500 list of the world’s most powerful machines. In that piece we kept the conversation about compute and capabilities but the real star of the show is in …

Will DeltaFS Become the File System of Exascale’s Future?
Many have tried, but few parallel file system upstarts have challenge the dominance of Lustre, and to a lesser extent these days, GPFS/Spectrum Scale. It does not seem to be just a matter of open source versus proprietary, but tradition and function. And while both most-used file systems in HPC …

Blazing The Trail For Exascale Storage
When it comes to advanced technologies at the high end of compute, networking, and storage, Lawrence Livermore National Laboratory is one of the world’s pathfinding testbeds. Trying new things at scale is a big part of the mandate for the lab, which among other things, is the US Department of …
Be the first to comment