
An increasing amount of the world’s data is encapsulated in images and video and by its very nature it is difficult and extremely compute intensive to do any kind of index and search against this data compared to the relative ease with which we can do so with the textual information that heretofore has dominated both our corporate and consumer lives.
Initially, we had to index images by hand and it is with these datasets that the hyperscalers pushed the envelope with their image recognition algorithms, evolving neural network software on CPUs and radically improving it with a jump to massively parallel GPUs. Once these neural networks are trained in image and video recognition, they can be fed new data and increase the pool of indexed data, feeding back and improving the algorithms. But recognizing what is in images and video is not sufficient. We want to be able correlate this data, to find things that are similar to one degree or another, and this is a particularly complex and compute-intensive task, which is made more difficult by the fact that it is tough to get anywhere near peak theoretical performance out of banks of GPU-accelerated servers when doing such similarity searches against this kind of data.
But the researchers at Facebook, which has long since put a stake in the ground about hosting such data as a means of keeping the social network growing and users spending more time on it, and thus generating more revenue and profits for itself, have taken a crack at pushing similarity search up into the billion-vector scale with graph analytics. It makes perfect sense that Facebook, with all of this GPU iron laying around for training the neural networks that drive its text, speech, image, and video recognition systems, would turnaround and try to use the same iron to build graphs – essentially databases of vectors expressing relationships between objects – and discover similarities and connections between elements of a dataset.
The interesting bit that will no doubt be applicable to other algorithms is how Facebook made use of the register memory and other features of various Nvidia GPUs (including its Titan X and M40, but no doubt applicable to more modern “Pascal” accelerators) to goose the performance of similarity search algorithms. The programing tricks are likely portable to other massively parallel GPU workloads, and luckily Facebook has open sourced the FAISS library it used in its tests so others can learn from its experience and verify the results it has obtained.
The methodology that the Facebook Artificial Intelligence Research team came up with is detailed in a just-published paper, called Billion-Scale Similarity Search With GPUs. Jeff Johnson, Matthijs Douze, and Herv´e J´egou, explain that the representations describing text, image, and video objects can have vectors with anywhere from 50 to more than 1,000 vectors, and that in many cases only a highly parallel GPU can produce and manipulate them because of the intense computational and memory bandwidth demands and cannot be partitioned easily to run across CPU clusters because of latency issues. One of the key parts of a similarity search on image or video data is to do a k-NN graph, which is short for a nearest neighbor graph, where a node in a network is connected to a variable number of neighbors denoted by k.
“This is our flagship application. Note, state of the art methods like NN-Descent have a large memory overhead on top of the dataset itself and cannot readily scale to the billion-sized databases we consider,” the researchers write. “Such applications must deal with the curse of dimensionality, rendering both exhaustive search or exact indexing for non-exhaustive search impractical on billion-scale databases. This is why there is a large body of work on approximate search and/or graph construction. To handle huge datasets that do not fit in RAM, several approaches employ an internal compressed representation of the vectors using an encoding. This is especially convenient for memory-limited devices like GPUs. It turns out that accepting a minimal accuracy loss results in orders of magnitude of compression.”
While there are many implementations of similarity search running on GPUs, according to Facebook, these are limited to small datasets, exhaustive search methods, or binary codes, and only one set of algorithms, also recently published by researchers from the Max Planck Institute at the University of Tubingen, Adobe Systems, and Disney Research, approached the billion-scale datasets like those that Facebook must handle. (The paper on this work, also recently published, is called Efficient Large-scale Approximate Nearest Neighbor Search On The GPU.) The method that Facebook cooked up has what it calls “a near-optimal layout for exact and approximate k-nearest neighbor search on GPUs,” and on the k-selection part of the algorithm it was able to drive the GPUs at 55 percent of their peak theoretical performance, which Facebook says is a factor of 8.5X better than the state of the art.
The code that Facebook has created was tested on the YFCC100M image dataset and built a k-NN graph on 95 million images in that dataset in 35 minutes. Just for fun, here is a path through the image database that shows how two flowers – the one in the upper left and the other in the lower right – are visually connected to each other through that image database.

Obviously, there are a lot of flower images in the YCC100M image database for it to have connected those shape and color dots so wonderfully.
Facebook also built a graph connecting 1 billion vectors in under 12 hours the Deep1B test developed by researchers at Russian search engine Yandex, Moscow Institute of Physics and Technology, and Skolkovo Institute of Science and Technology last year. The Facebook tests done on a server with four of Nvidia’s Titax X GPUs, and then followed up with a machine with eight Tesla M40 accelerators. And here is what the graph build times, with a tradeoff between time to build the graph and the accuracy of that graph plotted, look like for the YCC100M and Deep1B tests:
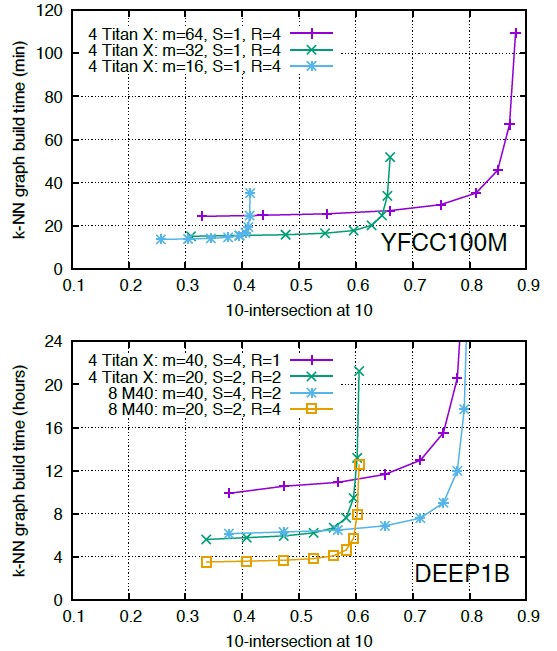
The upshot is that with its new algorithms, Facebook is able to do exact k-means clustering or compute the exact k-NN graph on a very large dataset with a brute force approach and do it is less time than it will take a CPU – or even a bunch of them –to do an approximate k-NN graph. There’s a whole bunch of CPUs that will not be sold and a whole lot of GPUs that are going to be running similarity searches on image, video, text, and speech data a whole lot more efficiently.

Surfing On The Ethernet Bandwidth Waves, Avoiding The Rocks
Any company making any kind of box – a server, a switch, a storage array – has three battles they need to fight here in 2022, one of which they did not have to worry about very much before the coronavirus pandemic and which is of prime importance these days. …

Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …

Giving Cloud Data Warehouses A Relational Knowledge Graph Overlay
The cloud has been a boon for enterprises trying to manage the massive amounts of data they collect every year. Cloud providers don’t have the same scaling issues that dog on-premises environments. But storing the data is only part of the problem. Pulling valuable business information from data housed in …
Be the first to comment