

Spark has grown rapidly over the past several years to become a significant tool in the big data world. Since emerging from the AMPLab at the University of California at Berkeley, Spark adoption has increased quickly as the open-source in-memory processing platform has become a key framework for handling workloads for machine learning, graph processing and other emerging technologies.
Developers continue to add more capabilities to Spark, including a SQL front-end for SQL processing and APIs for relational query optimization to build upon the basic Spark RDD API. The addition of the Spark SQL module promises greater performance and opens up the framework to a greater range of workloads.
However, while the addition of a SQL front-end was a significant step forward for the big data platform in terms of performance and workloads, it still lags behind such top relational query engines like HyPer, though Spark does better in terms of expressiveness, according to researchers at Stanford University and Purdue University. What’s needed is a technology that can bring Spark closer in terms of performance to HyPer and other best-of-breed query engines while retaining the qualities – such as expressiveness – that have made Spark one of the fastest-growing open-source projects in history.
In a recent paper, researchers introduced Flare, a back-end for Spark that improves the framework’s performance closer to that of the top SQL query engines for relational and machine learning workloads and strengthens Spark’s standing as a key unified and efficient big data platform in both scale-out and scale-up environments.
“Modern data analytics need to combine multiple programming models and make efficient use of modern hardware with large memory, many cores, and accelerators such as GPUs,” the researchers explain. They added that while Flare brings Spark’s performance closer to that of the top SQL engines and enables highly optimized heterogeneous workloads, “all of this comes without giving up the expressiveness of Spark’s high-level APIs. Multi-stage APIs, in the spirit of DataFrames, and compiler systems like Flare and Delite, will play an increasingly important role in the future to satisfy the increasing demand for flexible and unified analytics with high efficiency.”
Spark has become a fixture in the data analytics world and is now the most widely-used big data framework. At its core are the RDD (Resilient Distributed Dataset) APIs that also manage fault-tolerance, but the performance is hindered by limited visibility for analysis and optimizations and what the authors call “interpretive overhead” – function calls for each processed tuple. The Spark SQL module was introduced to reduce those limitations, and while the addition of SQL capabilities expanded what Spark can do, the performance still came up short by “an order of magnitude” when compared with the top SQL relational query engines, which have the advantage of being able to aggressively optimize every query plan on the relational operator level and to compile queries into native code, the researchers wrote. By comparison, Spark’s current techniques are based on Java.
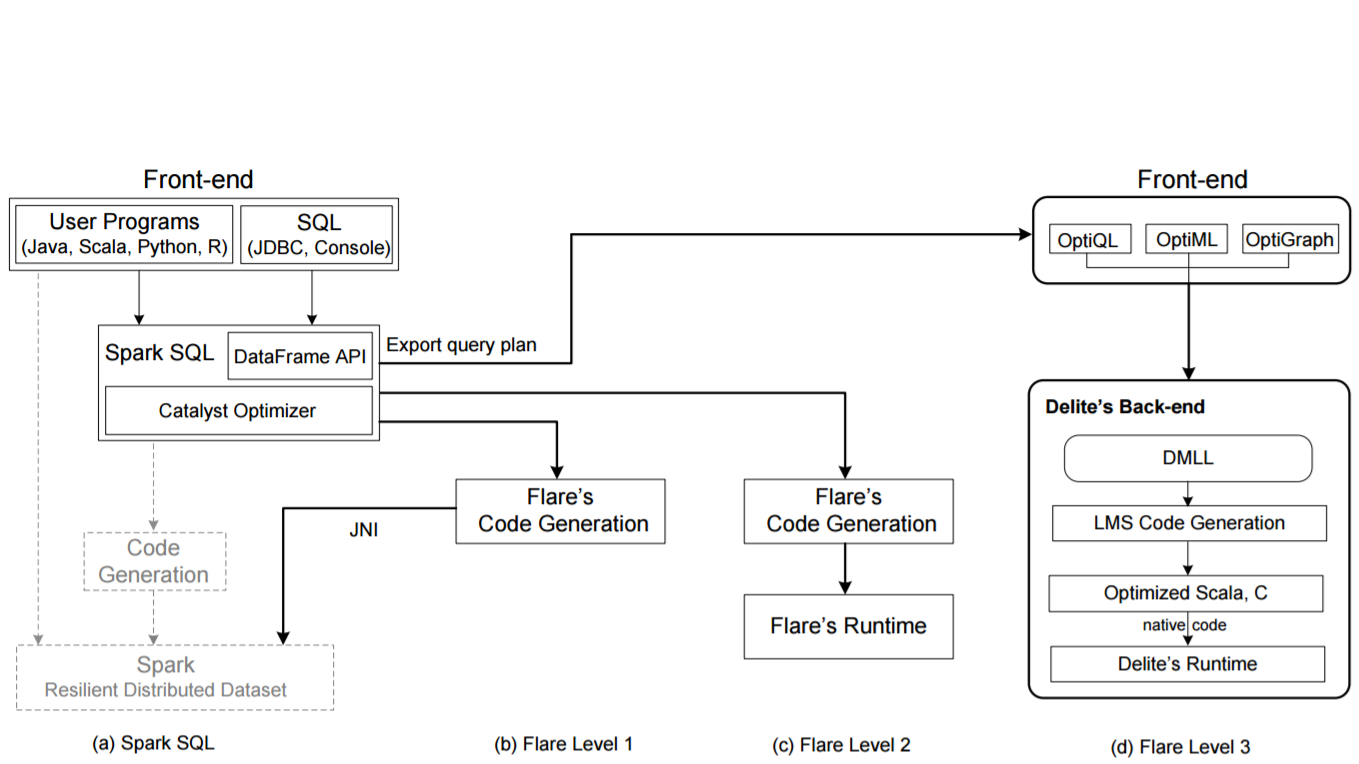
Flare is designed to compile Spark SQL queries into native code, reduce internal overhead and improve Spark’s performance closer. In Level 1, native compilation is done in Tungsten, an execution back-end that will improve Spark’s performance by reducing the number of objects allocated on the Java Virtual Machine (JVM) and generating Java code that is compiled to JVM bytecode at runtime. The aim is to improve the performance of Spark SQL libraries and DataFrame operations. Level 2 compiles whole queries rather than simply query stages, an optimization that enables such operations like hash joins in shared-memory environments to essentially bypass Spark’s RDD inefficient abstraction layer and runtime system. “Finally, Level 3 goes beyond purely relational workloads by adding another intermediate layer between query plans and generated code,” the authors wrote. “Flare Level 3 employs the Delite compiler framework to efficiently compile query pipelines with heterogeneous workloads consisting of user-defined code in multiple DSLs.”
The researchers ran multiple tests to determine the performance of Spark SQL with and without the acceleration from Flare. In on test, using Query 6 from the TPC-H benchmark running on a standard laptop – a MacBook Pro Retina with a 2.6GHz Intel Core i7 – they found that a handwritten C program ran 20 times faster than Spark 2.0. However, when running the same query, Spark with Flare delivered the same performance as the handwritten C program as well as best-of-breed SQL engines like HyPer. Other experiments involved such workloads as bare-metal relational queries in single-core and parallel computing environments, and heterogeneous workloads and user-defined functions (UDFs) on shared-memory NUMA systems and clusters with GPU accelerators. Throughout the experiments, Spark with the Flare back-end delivered improved performance at a level similar to that of SQL engines.
In the study, the authors spent time talking about scale-out and scale-up environments. They noted that such big data technologies as Spark, Hadoop and MapReduce all were developed with the idea of massively distributed datacenters like those run by Google in mind. In these environments, scaling computation is done by simply adding more machines, but it’s inefficient if some systems aren’t used to their full potential. Such inefficient use can result in not only higher datacenter cost, but on a larger scale, can also contribute to climate change. The researchers pointed out that scale-up systems – with the number of processing cores in the dozens and memory measured in terabytes, are available to buy for in-house use or available in public clouds. As examples, they used Dell’s built-to-order program that can offer as many as 96 cores, 192 hardware threads and 12TB of memory, instances in Amazon’s EC2 cloud with up to 64 cores, 128 threads and 2TB of main memory, and Nvidia’s DGX-1, a “supercomputer in a box” with eight GPUs that officials have said delivers the compute power of hundreds of traditional CPU-based servers.
“With such powerful machines becoming increasingly commonplace, large clusters are less and less frequently needed,” they wrote. “Many times, ‘big data’ is not that big, and often computation is the bottleneck. As such, a small cluster or even a single large machine is sufficient, if it is used to its full potential. With this scenario as the primary target – heterogeneous workloads and small clusters of powerful machines, potentially with accelerators such as GPUs – Flare prioritizes bare-metal performance on all levels of scaling, with the option of bypassing mechanisms such as fault-tolerance for shared-memory-only execution. Thus, Flare strengthens Spark’s role as a unified, efficient, big data platform, as opposed to a mere cluster computing fabric.”

Vast Data Intentionally Blurs The Line Between Storage And Database
Depending on how you look at it, a database is a kind of sophisticated storage system or storage is a kind of a reduction of a database. In the real world, where databases and storage are separate, there is a continuum of cooperation between the two, for sure. There is …
Meta’s Velox Means Database Performance Is Not Subject To Interpretation
A decade and a half ago, when Dennard scaling ran out of gas and many of us were starting to first think about what the end of Moore’s Law might look like should that day ever come, a bunch of us were kicking around what it might mean. People brought …
Databricks Is Going To Be The Next Platform For Many Enterprises
The hyperscalers, cloud builders, HPC centers control the design and manufacturing of own AI infrastructure. They have big bucks, and they can afford to get exactly what they want. For the rest of the world, and particularly large enterprises who cannot afford to start from scratch and who want to …
Be the first to comment