

One of the reasons why Nvidia has been able to quadruple revenues for its Tesla accelerators in recent quarters is that it doesn’t just sell raw accelerators as well as PCI-Express cards, but has become a system vendor in its own right through its DGX-1 server line. The company has also engineered new adapter cards specifically aimed at hyperscalers who want to crank up the performance on their machine learning inference workloads with a cheaper and cooler Volts GPU.
Nvidia does not break out revenues for the DGX-1 line separately from other Tesla and GRID accelerator product sales, but we think that a significant portion of the company’s $409 million in Datacenter group sales came from these DGX-1 server sales, which Nvidia undertook because it wanted to see the machine learning research and development market ahead of broader adoption of its “Pascal” and now “Volta” GPU coprocessors.
Making its own servers is a smart move in many ways, even if it probably does annoy server OEMs and ODMs working for hyperscalers who want to be at the front of the line in receiving these parts as they come off the Nvidia production line. GPU accelerators are the hottest items in the server racket these days, and arguably among the most profitable items, too. And you can bet that Hewlett Packard Enterprise, Dell, IBM, Lenovo, Fujitsu, Inspur, Sugon, and others wish they were at the front of the line rather than behind Nvidia, and ditto for Microsoft and Facebook and the rest of the Open Compute crowd. But the reality is that any hot new technology has a waiting line, and a red rope at the front. Back in heyday of the mainframe, when IBM introduced its first air-cooled mainframes, companies were lined up like customers at a bakery and assigned a numerical position in the line, and some companies were so desperate for the new iron that they bought positions higher up in the line.
IT has always been fun on the cutting edge, no matter what kind of metal was being deployed.

We don’t think Nvidia is explicitly assigning positions in the Pascal and Volta lines to specific customers, but by making and selling the DGX-1 systems and, now, a DGX Station workstation for more modest workloads, the company is able to get all the juicy public relations as the new technology rolls out for itself as Nvidia cofounder and CEO Jen-Hsun Huang makes the rounds and gets the photo-ops. But it is more than that. Nvidia gets to book the revenues, and even if it just breaks even on these sales, that is incremental revenue for its Datacenter group that would have gone to some other company. The addition of servers and now workstations to the Datacenter group will keep the gravy train accelerating for Nvidia. The DGX-1 system was announced at the GPU Technical Conference in April 2016, and we don’t think it is a coincidence that in the following quarter the Datacenter group sales, and Tesla sales in particular, took off. At $129,000 for a two-socket Xeon E5 server with eight Pascal Tesla P100 accelerators, it doesn’t take very many to add up to significant revenues. Just 200 DGX-1 systems would add up to $25.8 million in revenues at list price, and in that first quarter when they were available, we estimate that $128 million of the $151 million in Datacenter Group sales came from Tesla rather than GRID products. So the DGX-1 machines could represent somewhere between 10 percent or 20 percent of Tesla product sales in that initial quarter, and that share could be more or less constant as Nvidia sells the systems to the hundreds of academic, government, and private research centers that are interested in machine learning and that are jockeying to get such iron.
Equally importantly, the DGX-1 gave Nvidia a recurring, annual software subscription revenue stream from the AI frameworks it packages and supports on the DGX-1 systems. We estimate that $30,000 of the $129,000 sticker price on the DGX-1 was for this software support, so it is a non-trivial amount and it just keeps coming in once the sale is done.
Finally, even if the server OEMs and ODMs make a fuss, what can they do about it if Nvidia is also selling systems? Customers want Nvidia Teslas to accelerate HPC simulations, machine learning training, and now databases, and that is that. Until AMD gets its “Naples” Epyc X86 processors and their sibling “Vega” Radeon Instinct GPU accelerators into the field and gives Nvidia some competition (along with Intel), Nvidia is pretty much the only game in town for GPU acceleration. But, as we have pointed out before, with the ROCm platform being able to run CUDA applications atop AMD GPUs, this situation is changing.
We know one thing for sure. After its SeaMicro experience of selling iron against its server chip partners, which was plenty annoying to HPE, Dell, and others, AMD is very unlikely to create an analog of the DGX-1 that it sells directly.
The new DGX-1 system based on the Volta V100 GPUs announced at GTC 2017 bears a strong resemblance to the prior machines that Nvidia started selling a year ago, and that is by design. The DGX machines have the Xeon server components in a 1U chassis, and the eight GPUs that come in the SMX2 “credit card” form factor are soldered onto a carrier board that plugs into X86 compute complex by a pair of PCI-Express switches. To upgrade the DGX-1 from the Pascal to the Volta cards, all you do is slide out the GPU carrier board and replace it with one based on Voltas instead of Pascals.
The Pascal chips have four NVLink 1.0 ports running at 20 Gb/sec in both directions, and the Voltas have six NVLink 2.0 ports running at 25 Gb/sec bi-directionally, and we have been told that the complex of eight GPUs in the Volta variant of the system makes use of these extra NVLinks to more tightly couple the GPUs together, and the hybrid cube mesh topology implemented in the GPU carrier board does this automagically. With seven ports, all eight GPUs could have been linked directly to each other, and with eight, there would have been spares to hook out to NVLink ports on processors. But Intel and AMD are not going to put NVLink ports on their processors, and IBM only needs to support four GPUs per node in the future “Summit” and ‘Sierra” supercomputers that are being built for the US Department of Energy. It is a wonder why this was not pushed up to eight ports so the Summit and Sierra machines could have more GPUs per node, but these NVLink ports do take chip real estate and power and the plans for the Pascal and Volta accelerators and the Power8+ (IBM refused to call it this) and the Power9 processors were formed many years ago.

The processing complex in the DGX-1 system with Volta V100 accelerators is similar, but more powerful. The underlying X86 system in the Pascal DGX-1 had two “Haswell” Xeon E5-2698 v3 processors, which had 16 cores each and which ran at 2.3 GHz. The Volta variant has two 20-core “Broadwell” Xeon E5-2698 v4 processors running at 2.2 GHz, which yields a bit more throughput. (Our guess is about 25 percent more, based on relative performance metrics we cooked up here.) Both generations of DGX-1 machines are configured with 128 GB of DDR4 memory running at 2.133 GHz and is expandable up to 512 GB. The base machine comes with two 10 Gb/sec Ethernet ports to the outside world (which come off the integrated Ethernet ports on the Xeon chips), and this can be upgraded to four ports (across two adapters) of EDR InfiniBand running at 100 Gb/sec. The systems have four 1.82 TB flash drives for local storage, and both generations of DGX-1 machines use Canonical’s Ubuntu Server Linux distribution that seems to be preferred by researchers in the machine learning field.
Last April, we took a stab at trying to figure out what the Pascal Tesla P100 adapters cost based on the $129,000 price tag of the original DGX-1, and we still think we have it pretty close and will use the same method to try to figure out what the Volta Tesla V100 accelerators cost.
With the original DGX-1 based on Pascal – why not call this the DGX-1P? – we assumed that underlying server and the unified CPU-GPU enclosure was worth about $25,000. We also reckoned that the Nvidia-supported software stack cost about $20,000 a year, leaving $84,000 to cover the cost of the eight Tesla P100 accelerators. So that worked out to $10,500 per Tesla P100.
With the new DGX-1 machine based on Volta – why not call this one the DGX-1V? – the price tag has gone up to $149,000. The two different Xeon E5 processors cost the same, and so does the rest of the underlying X86 system; we presume that the software stack costs the same, too. So that is $104,000 across eight of the Tesla V100 accelerators, or $13,000 a pop. (We are working on a more comprehensive deep dive comparing all of the generations of GPU accelerators from Fermi to Volta. So stay tuned.)
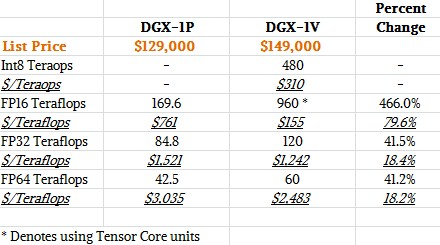
The bang for the buck on the DGX-1P compared to the DGX-1V is pretty impressive, and particularly so when you take into consideration the Tensor Core accelerators that are new with the Volta GPUs and that are used for both machine learning inference and training.
The DGX-1P had a total of 85 teraflops of floating point oomph at 32-bit single precision and 42.5 teraflops at 64-bit double precision, and the DGX-1V delivers 41.2 percent more oomph, or 120 teraflops at single precision and 60 teraflops double precision, for that incremental 15.5 percent higher price tag. That works out to an 18.2 percent improvement in bang for the buck, which isn’t bad for a year’s time and which is akin to what you would expect from generational CPU improvements. (These numbers all assume GPU Boost is on and the clocks on the cores are cranked.)
The big jump comes from workloads that can make use of the 16-bit Tensor Core units on the Volta chip. The Pascal P40 chips, which are distinct from the P100 and which were announced in September 2016, had 8-bit integer instructions added to the CUDA cores and stripped out 64-bit floating point units to make room for these, and the idea was to make a chip that was great at machine learning inference. FP16 half precision was not supported on the P40 or its sibling, the P4 accelerator. But this thing could handle 47 teraops on inference workloads using the INT8 instructions.
The Volta chips have new Tensor Cores, which are designed to do the kind of matrix math (multiplication and accumulation) that machine learning algorithms run well on and at the 16-bit level and using floating point math rather than integer. The Volta chip also has separate cores that just do INT8 instructions. The neat thing is that the Tensor Cores have much higher throughput than the quad-pumped 32-bit integer units, as far as we can tell.
The net result of the Tensor Cores is that the DGX-1V can deliver 960 teraflops of FP16 half precision performance, which is twice the throughput of the INT8 units on the chip, and more importantly, if offers nearly five times the FP16 performance as the DGX-1P and that delivers nearly an 80 percent improvement in price/performance for machine learning inference workloads using FP16. This is a radical increase in value, and is it something that the hyperscalers and AI researchers wanted badly.
For those who are looking for something on a slightly smaller scale, Nvidia is now selling a DGX Station workstation, which it calls a personal AI supercomputer and which packs four Volta V100 accelerators into a two-socket server using 20-core “Broadwell” Xeon E5-2698 v4 processors running at 2.2 GHz. The system comes with 64 GB of main memory, expandable to 256 GB, plus three 1.92 TB flash drives (one for the Ubuntu Desktop operating system). It also has two 10 Gb/sec Ethernet ports and can drive three 4K displays. The whole shebang has an internal liquid cooling system and costs $69,000.
The DGX Station will be delivered in the third quarter, and OEMs will be getting their hands on Tesla V100 accelerators in the fourth quarter. Customers who buy a DGX-1 with Pascal accelerators today can upgrade to the Voltas for free, according to Nvidia. It is not clear when Nvidia will start selling DGX-1, but presumably before the OEMs and ODMs get their hands on Volta.
Volta For Hyperscalers
Not everyone is going to use a DGX-1, and particularly not companies that want to have super-dense server clusters for running machine learning inference at scale. These customers don’t want a system that has maximum performance, but rather that maximizes the compute performance in a rack while also taking into account value per dollar and thermals.

To this end, Nvidia has launched the Tesla V100 for hyperscale inference, a full height, half length PCI-Express card that has a slower variant of the V100 accelerator in this regular form factor rather than in the SMX2 form factor that supports NVLink and that snaps down onto the motherboard. The feeds and speeds of this card were not divulged, but what we do know is that it is rated at 150 watts and that it is expected to have somewhere between 15X and 25X the inference performance versus Skylake. We are not sure if this metric is at the socket or system level, but we are trying to get an answer on this. It looks like it is at the server node level, pitting two future “Skylake” Xeon processors against a GPU accelerator enclosure with 18 of the PCI-Express variants of the Tesla V100.
Our guess is that this Tesla V100 for Hyperscale Inference – it needs a better name – manages to offer much more than half the performance of the 300 watt high-end Tesla V100 all tricked out for NVLink and such. This is hard to guess, but turning down the clocks lowers the heat a lot faster than it lowers performance. We will try to sort it out.


Accenture Melds Smarts And Wares With Nvidia For Agentic AI Push
Over the past two years, enterprises have tried to keep up with the staggering pace of the innovation with generative AI, mapping out ways to implement the emerging technology into their operations in hopes of saving time and money, increasing productivity, improving customer service and support, and driving efficiencies. However, …

HPC In 2020: AI Is No Longer An Experiment
If we could sum up the near-term future of high performance computing in a single phrase, it would be more of the same and then some. Although no “revolution” is in the horizon, the four major trends of the past decade – the expansion of artificial intelligence technology, processor diversification, …
The First AI Benchmarks Pitting AMD Against Nvidia
Rated horsepower for a compute engine is an interesting intellectual exercise, but it is where the rubber hits the road that really matters. We finally have the first benchmarks from MLCommons, the vendor-led testing organization that has put together the suite of MLPerf AI training and inference benchmarks, that pit …
Be the first to comment