
While AMD voluntarily exited the server processor arena in the wake of Intel’s onslaught with the “Nehalem” Xeon processors during the Great Recession, it never stopped innovating with its graphics processors and it kept enough of a hand in smaller processors used in consumer and selected embedded devices to start making money again in PCs and to take the game console business away from IBM’s Power chip division.
Now, after five long years of investing, AMD is poised to get its act together and to storm the glass house with a new line of server processors based on its Zen core, code-named “Naples” and now known by the Epyc brand, and a revitalized discrete GPU accelerator line based on its “Vega” generation of motors and sold under the Radeon Instinct brand. The change is an admission that modern workloads running on clouds, in hyperscale datacenters, and at HPC centers are as much focused on throughput as they are energy efficiency and that the accelerated processing unit (APU) CPU-GPU hybrids that AMD had been trying to get traction with in systems just didn’t have the necessary oomph to win deals. With APUs, AMD was telling customers to use many small sockets that, in the aggregate, provided great throughput at an affordable price and very good energy efficiency. But the market didn’t care. So now, with Naples, AMD is building a brawnier X86 socket (ironically from a multichip module derived from its Ryzen desktop chips) with a huge amount of memory and I/O bandwidth and for HPC and machine learning workloads the ability to directly them through PCI links to its own GPU accelerators, all running a clone CUDA environment and using a highly tuned compiler based on the LLVM stack.
This is story that better reflects the current computing market and that will probably resonate better. It had better, or the entire world will be calling this an Epyc Fail.
AMD has been very careful about revealing too much about the Naples Epyc and Vega Radeon Instinct compute engines, but ahead of the Naples launch scheduled for this week, the company has provided some strong hints about how it will try to take share away from Intel CPUs and Nvidia GPUs, which dominate their respective compute and accelerator portions of the datacenter.
Naples X86 server chips are set to debut this week at an event in Austin, Texas and we will be covering that launch as well as the happenings at the International Supercomputing Conference in Frankfurt, Germany. AMD lifted the veil a bit more on the Naples chips at its Financial Analyst Day last month, showing how its 32-core, 64-thread Epyc processors could best the current “Broadwell” Xeon E5 v4 processors from Intel and take on the impending Skylake Xeons, which are expected to launch sometime in July if the rumors are right. AMD is concentrating on the core two-socket segment of the market, and is convinced that given the performance of its single socket Epyc server chip and its ability to hang four or six Radeon Instinct coprocessors on the 128 lanes of PCI-Express 3.0 I/O bandwidth on a single socket that is can beat Intel in price and maybe on performance against a two-socket Xeon box that has GPU accelerators that require NVLink interconnects and PCI-Express switching hierarchy to attach to the Xeon compute complex.
We look forward into seeing how these various machines are priced and configured, and how they perform on a wide variety of simulation, modeling, machine learning, and database acceleration workloads. It is hard to judge without a lot more data, but at least AMD is in the game, competing again, and bringing to market the kinds of components that companies are familiar with and already buying from the likes of Intel and Nvidia.
Getting IT organizations to trust AMD again, as they did back in the middle 2000s, will be a bit of a challenge. And to help build confidence, the company has been talking a little more openly about its CPU and GPU roadmaps, and presumably is putting these out there and will not, as in days gone by, change them when the going gets tough. The company’s top brass talked about the impending CPUs and GPUs and put stakes in the ground for the following two generations. The details, mind you, are a little thin.
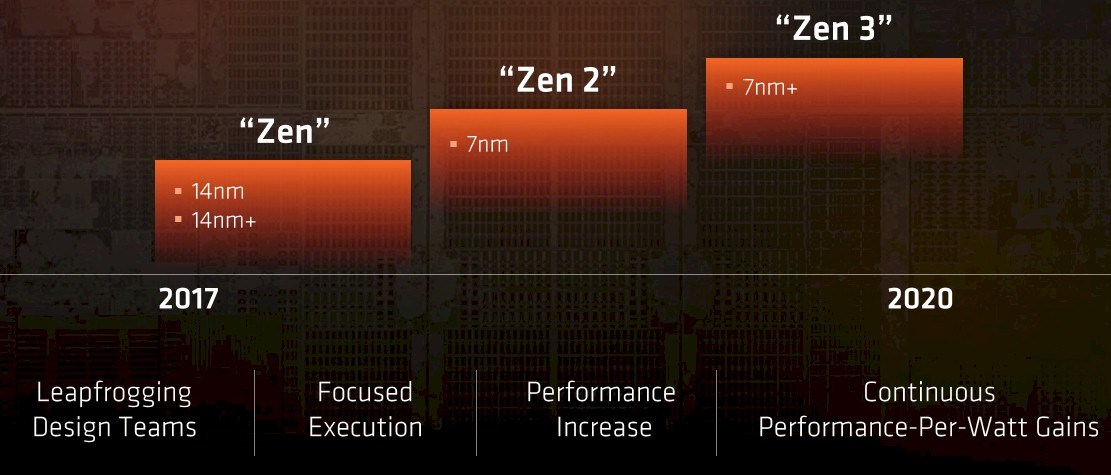
On the CPU front, AMD chief technology officer Mark Papermaster told the Wall Street crowd a month ago that the Zen 2 core has been in development for more than a year and that a Zen 3 core was in the works now that the original Zen core was coming to market. The current Zen cores are implemented in the 14 nanometer processes from foundry partner (and former AMD business) Globalfoundries, and a follow-on 14+ nanometer rev on this process will be used to goose the performance and yields on the Zen designs embodied in the Ryzen and Epyc processors. The Zen 2 cores, as the roadmap above shows, will be etched in a 7 nanometer process that Globalfoundries has started to talk about publicly (we are doing a deep dive on that now) and the Zen 3 chips will be created using a 7+ nanometer kicker technology and will not involve a process shrink to 5 nanometers or smaller. (IBM, which is a foundry partner with AMD and Samsung, has just demonstrated that it can do 5 nanometers in the labs and this tech, if perfected, can be adopted by Globalfoundries for future chips.) The three Zen cores will span a period from 2017 through 2020 inclusive, which is three core generations across four years, and that works out to an average of 14.5 months between generations if Zen 3 chips have an end of life in December 2020. That is a fairly brisk cadence, and we concede that the charts may not reflect planned, much less attained, timing for Zen core design rollouts.
As for the Epyc family of processors, the roadmap has a similar cadence, as you might expect.

The first generation of “Naples” Epyc server chips will use the plain vanilla 14 nanometer processes from Globalfoundries, and it looks like the kicker 14+ nanometer technique is not going to be used in the next chip in the Epyc line, which is code-named “Rome,” or a follow-on Naples kicker. This Rome chip will use the Zen 2 cores and will be manufactured using the 7 nanometer processes at Globalfoundries, and the “Milan” third generation Epyc server chips will employ the 7+ nanometer techniques to make the Zen 3 cores and their adjunct components on the die.
AMD is not being specific about what it will do as it etches these follow-on Rome and Milan chips, but if the four-way multichip module design used for the Naples chips experiences latency and bandwidth issues on certain workloads (as we suspect it might), then AMD might be flush enough with cash to do a true monolithic design to get around these issues. That might radically increase the cost of making Epyc chips while only improving performance modestly, so we reckon that if AMD went with the chiplet approach to begin with, it might be hesitant to change strategy. It might make sense to create a special part if the performance of the Infinity fabric within the Epyc chip package creates a barrier to adoption for certain workloads. The point is, AMD could not do this on the first go around with Epyc, but if it starts making money with system chips, its options widen out and it can architect chips to take bigger slices away from Intel and possibly reach its natural 10 percent to 15 percent market share.
On the GPU front, AMD has been pretty tight lipped about the Vega GPU and the features it has for datacenter compute, but at the Financial Analysts Day, Raja Koruri, senior vice president and chief technology officer in charge of the newly composed Radeon Technologies Group at AMD, gave some details along with Papermaster.

The plan and the processes are much the same as with the GPUs as with the CPUs. The “Vega” GPUs will start to roll out this month with a special Frontier Edition aimed at early adopters and enthusiasts, and these are made using the same 14 nanometer processes as the CPUs. There is a kicker 14+ nanometer process bump for the Vega GPUs, and then the “Navi” GPUs roll out in what looks like early 2018 from the roadmaps using 7 nanometer processes. The “Next Gen” GPUs that follow Navi don’t have a real code name yet, but they will use the 7+ nanometer node from Globalfoundries, and there are leapfrogging design teams to keep the innovation moving ahead.

To give a sense of the potential performance of the Vega-based Radeon Instinct coprocessors, AMD grabbed the DeepBench neural network training benchmark developed by Chinese hyperscaler Baidu and ran it on a system configured with a single card. This machine was able to train a particular machine learning model in 88 milliseconds. A single “Knights Landing” Xeon Phi 7250 accelerator (or host) was able to do the task in 569 milliseconds, by comparison, and a Tesla M40 accelerator based on Nvidia’s Maxwell GPUs did it in 288 seconds and a more recent Tesla P100 based on the Pascal GPU did it in 122 seconds. The Volta GPUs could offer substantially higher performance than the impending Radeon Instinct, but these tests show that AMD is in the ballpark and playing ball instead of being stuck in traffic a few miles from the stadium as it has been for many years in datacenter compute.
The Vega chip has 4,096 stream processors organized into 64 compute units, and is expected to deliver 483 GB/sec of bandwidth into and out of the double-stacked HBM2 memory; it comes in 300 watt air-cooled and 375 watt water-cooled. The Vega GPUs will have 16 GB of HBM2 memory on the interposer, and interestingly, have dedicated NVM-Express ports that will allow for 2 TB of flash capacity to be directly attached to the GPU accelerator to extend that memory size; think of it as a fast cache for the GPU memory. That HBM2 memory is four times as much as was crammed onto the prior Radeon Fury X GPU accelerators based on the “Polaris” GPUs, and with the support for half-precision FP16 floating point math, the devices will deliver around 26.2 teraflops of performance suitable for many machine learning training workloads. AMD is telling customers to expect around 13.1 teraflops of performance at single precision for floating point, and it has not talked about double precision performance. It is not necessarily going to be the case that double precision will be half of single precision (this happened with Nvidia’s “Maxwell” GPUs), and in fact with the first iteration of Vega chips, the scuttlebutt is that they will only offer double precision at 1/16th the rate of single precision. So that leaves the Vega accelerator at only 819 gigaflops at double precision.
The word on the street is that the kicker Navi GPU (which used to be called the Vega 20 in some roadmaps) will offer double precision at half the single precision rate when it comes to market in 2018. That shrink to 7 nanometer processes, using the same 4,096 streaming processors and 64 compute units, will increase performance by around 20 percent or so, which means single precision will be around 15.7 teraflops and double precision will be around 7.9 teraflops. AMD could shift to four stacks of HBM2 memory for a total capacity of 32 GB, and bandwidth could double or more, depending on a lot of issues with regard to memory speed, power draw, and heat dissipation.
For the sake of comparison, the “Volta” GPU accelerator from Nvidia that was just launched in May and that will be shipping in volume early next year, delivers 15 teraflops at single precision and 7.5 teraflops at double precision, and has special and additional 16-bit Tensor Core tensor processing units that can deliver 120 teraops of performance on machine learning training algorithms. AMD’s Vega GPUs do not have anything like the Tensor Cores, and from what we can tell, they do not have anywhere near the 900 GB/sec of HBM2 memory bandwidth across that 16 GB of memory like Nvidia does, either. There is also not anything like NVLink interconnects, but given AMD’s vast experience with APUs, we do expect coherency of memory across the GPUs and the CPUs, and if this does not happen, then AMD should know better.
Here is the point, however. We expect that AMD will be very aggressive on price with the Naples Epyc processors compared to Intel’s Skylake Xeons, and competitive with the Broadwell Xeons that Intel will use as a firewall for companies that don’t want to pay the Skylake premium that we think Intel will try to extract from the market while it can. The same tactics will play out with the GPUs. Nvidia list price was around $10,500 for a Tesla P100 Pascal-class accelerator, and let’s say for fun that the Tesla V100 accelerators cost $13,000 because the same math works backwards from the DGX-1 update. At those prices, even without a Tensor Core unit and even without decent double precision performance, AMD can take some share away from Nvidia where FP16 and FP32 dominate the workloads.
It can also make a less complex and less expensive CPU-GPU node, as the following chart illustrates:

With a current system like Nvidia’s DGX-1, a cluster of GPU accelerators are linked to each other using NVLink, which provides memory concurrency across those GPUs. But because Intel does not support NVLink ports on its Xeons or their chipsets, it takes a pair of PCI-Express switches to link a pair of clusters of GPUs to a pair of CPUs and to the outside world with a pair of Ethernet or InfiniBand controllers. In the DGX-1, there are eight GPUs, not six shown in the diagram above, and with Volta they can all be cross-connected with NVLink; with Pascal Teslas, which has one fewer NVLink port, you have to use a mix of PCI-Express and NVLink to hook them all together. You also need a storage controller if you want to link flash SSDs to the compute complex, or burn PCI-Express slots using NVM-Express (which is not shown in the chart above). Because of the limited PCI-Express 3.0 lanes on each Xeon processor socket and the main memory cap per socket, you need a two-socket server to get the right mix of I/O and memory bandwidth and memory capacity.
Contrast this with a single-socket hybrid Epyc-Radeon Instinct system. The single socket machine has enough PCI-Express (Infinity Fabric) bandwidth to hang 16 flash drives and 16 memory sticks off a single socket plus six Radeon Instinct GPUs. That is the same memory capacity as an HPC-configured, two-socket Xeon server. The 32 cores on the Epyc die are probably enough to drive six GPUs, just as 32 cores would be on a two-socket Xeon server using a pair of 16-core chips. But there are only enough lanes in the Epyc system to drive eight GPUs total – and that is if there is no other networking or peripherals attached. It is not clear why each GPU does not have its own directly attached flash SSD as is possible with the Radeon Instinct accelerators, and in a balanced setup, some flash drives might be dedicated to the CPU and others to the GPUs.
With the lower cost AMD CPU and GPUs, plus the integrated chipsets and the fact that there are fewer sockets, it is hard to imagine the AMD box not having the same or better bang for the buck. (We think that it will be a lot lower, especially if Intel jacks up prices on Skylake Xeons as we expect it to.) Even if hybrid AMD systems only deliver 75 percent of the performance, but do so at half the cost, the company can very likely sell the components in such machines at reasonably high margins and drive both its top line and bottom line. This, we think, is the AMD strategy, and it is one that is designed to get AMD market share over the longer haul.
The trick will be to sustain the gap and shoot through it, and that depends on what system makers, who don’t want to annoy Intel, do and when and how they do it.


How Long Before AI Servers Take Over The Market?
When hyperscalers and cloud builders think about their infrastructure, they talk about megawatts and they think about the mix of serving and storage and the total capacity that is delivered in a megawatt of power. And of course they also think in terms of budgets because money is, in fact, …

AMD’s Long And Winding Road To The Hybrid CPU-GPU Instinct MI300A
Back in 2012, when AMD was in the process of backing out of the datacenter CPU business and did not really have its datacenter GPU act together at all, the US Department of Energy exhibited the enlightened self-interest that is a strong foundation of both economics and politics and took …

HPC In 2020: Acquisitions And Mergers As The New Normal
After a decade of vendor consolidation that saw some of the world’s biggest IT firms acquire first-class HPC providers such as SGI, Cray, and Sun Microsystems, as well as smaller players like Penguin Computing, WhamCloud, Appro, and Isilon, it is natural to wonder who is next. Or maybe, more to …
Please, correct: FuryX had Fuji architecture, not Polaris
Earlier leaks may indicate Epyc Fail
http://ranker.sisoftware.net/show_run.php?q=c2ffcee889e8d5e3daeedde4d0f684b989afcaaf92a284f7caf2&l=en
2x Epyc gets 974.33Mpix/s
http://ranker.sisoftware.net/show_run.php?q=c2ffcee889e8d5e3d4e6d2e6d3f587ba8aacc9ac91a187f4c9f9&l=en
2x Broadwell E5-2699v4 gets 2540.77Mpix/s
http://ranker.sisoftware.net/show_run.php?q=c2ffcee889e8d5e3dbe3d1e0d6f082bf8fa9cca994a482f1ccfc&l=en
2x Xeon Platinum gets 5989.90Mpix/s
Reckoning day today, shall see how final Epyc performs
Latest leak, performance fixed
http://ranker.sisoftware.net/show_run.php?q=c2ffcee889e8d5e3daeed8e0d4f280bd8dabceab96a680f3cef6&l=en
2x AMD EPYC 7601 gets 2523.84Mpix/s with 64 cores
But still falls short of Broadwell and Skylake results posted earlier
“(ironically from a multichip module derived from its Ryzen desktop chips)” [No, No, and No]
No there is no connection to a “Ryzen chip”(Actually that Chip/die is called/codenamed the Zeppelin Die) being anything other than the Zeppelin modular die SERVER first design that was used to create/derive AMD’s Ryzen(Brand name for a line of consumer SKUs based on the Zeppelin die). AMD designed Zeppelin( 8 Zen micro-architecture based cores/4 cores to a CCX, at 2 CCXs per Zeppelin die) first and foremost for the server market and with AMD’s limited budget that Zeppelin modular die(and related per die Infinity Fabric, Memory controller/other IP) became the foundation for what AMD has used across its entire desktop/consumer(Ryzen), HEDT/consumer(Threadripper) , and Epyc(Server/Workstation/HPC) lines of CPU products.
With Zeppelin think modular as that what Zeppelin was designed to be and with the Infinity Fabric it’s what the modular/scalable Zeppelin die can be made to scale up from currently 1 to 4 Zeppelin dies(all communicating coherently via that Infinity Fabric) and even across the motherboard to that second socket to via those re-tasked PCIe(64 per socket) lanes, and also to any Vega GPU based SKUs that also speak Infinity fabric. It’s Infinity Fabric across all of AMD’s product lines for the desktop and professional markets CPU’s, GPUs and whatever else AMD has in mind.
[The NextPlatform needs to get more info on any Vega based SKUs communicating with EPYC CPUs over the Infinity Fabric in a similar direct attatched GPU accelerator manner to Nvidia’s NVLink, AMD has already touted this ability for direct communication EPYC to Vega GPU accelerator via the Infinity fabric]
Please if you can make it your goal to query AMD about any EPYC to Vega direct attatched GPU accelerator usage via the Infinity Fabric(Not PCIe) and relevant/related IP ASAP. It was first discussed at a trade event where AMD first demonstrated it’s EPYC engineering sample and related seismic benchmarks(Videos where made of the demos).
“Ryzen(TM)” is a branding for a consumer line of AMD desktop CPU SKUs based on the Zen micro-architecture. (Ryzen 7, 5, 3, all make use of a single Zeppelin die with 8 full cores for the Ryzen 7 1700/1800/1700X/1800X SKUs and with Ryzen 5(6 and 4 core) and 3(4 core) SKUs made up of binned Zeppelin(8 core/2 CCX unit) dies, using bad and/or disabled cores/ harvested Zeppelin dies.
ThreadRipper(TM) is a consumer branding for an line of AMD HEDT(High End DeskTop) CPU SKUs Zen micro-architecture(2 Zeppelin dies on an MXM).
EPYC(TM), up to 4 Zeppelin dies on and MXM, is the professional branding for the server/workstation/HPC line of professional SKUs and actually is the intended usage for that Zeppelin(Codename) die with Ryzen/ThreadRipper actually being derived from that Zeppelin modular die, as a matter of economics on AMD’s part.
AMD made very good usage of its limited resources this time around while still managing to innovate and offer better platform features at a lower price point than Intel. That’s 128 PCIe lanes across all of AMD’s single and dual socket Epyc/motherboard SKUs and 64 PCIe lanes for the consumer ThreadRipper/Motherboard HEDT SKUs with no ThreadRipper SKUs stripped of PCIe lanes like Intel does with its HEDT SKUs(Intel’s premeditated product segmentation).
That would not be MXM that would be MCM(Multicore Module) and there are rumors of an Upcoming EPYC/ROME platform on 7nm that may just go with 6 ZEN cores per CCX unit with whatever Zeppelin(new code name)Die having 12 Zen cores per die, and EPYC/Rome will offer up to 48 Zen(version 2) cores per Epyc/Rome chip/socket. The Ryzen 8 core die is getting a revision shortly with a B2(rumor) stepping to fix any erratas that could not be fixed with Microcode updates and I’d expect that any of Epyc’s Zeppelin/whatever dies will probably have more tweaks and still have the usual teething problems that Ryzen had. I hope that once ThreadRipper is released that AMD will offer a deeper dive into its Infinity Fabric IP, along with some more information on its interposer based workstation APUs.
There is currently not much Info on any Epyc/Motherboard pricing or availability through the regular retail channels for any home system builders, but I’m looking at maybe a single socket 24 core purchase if the motherboard is not overly costly, the ECC DRAM will be costly enough for any system builders. Hopefully there will be some systems for independent benchmarking soon enough. It’s going to take time for the software/OS ecosystem to adjust to optimizing for Zen and that Modular Zeppelin die and derived Ryzen/Threadripper/EPYC SKUs so hopefully the benchmarking software issues can be quickly resolved and the independent testers can have the proper tools to get their jobs done.
AMD total lack of understanding of a software ego-system really frustrates me, the best hardware in the world will not be used if there are no API/software/tools that can easily plugged in and get some great performance. nVidia has realized that a decade ago. AMD still is catching up to the fact.
I like “software ego-system,” General. I may have to start using that.
Yes but AMD ROCm(Radeon Open Compute) will allow AMD and Others(academic/everybody and their dog) to develop and utilize AMD’s Vega/Older GCN generation GPU Compute/AI products without any proprietary/vendor lock-in that comes with any Nvidia GPU dependency. So one would expect AMD’s already improving Driver/Middleware situation to reach parity and then quickly go past many of the fully proprietary driven software/middleware/driver ecosystems.
The supercomputer/HPC world runs on the Linux Kernel and that does have a definite history of attracting many to a more standard and open software ecosystem where the software/middleware, and hopefully driver(GPU) ecosystems are open and standardized with everyone sharing in the development costs and paying things forward with open source code contributions becoming the coin of the realm. The academic community likes that openness and sharing among the academic community as that tends to save on funds required and those grants can fund more basic research rather than line the pockets of any single proprietary interest’s bank account.
Once AMD fully open sources its GPU drivers(Not there Yet) even more tweaking can be done across many development entities academic/others outside of any of the currently necessary NDA/driver Mafia sorts of arrangements with the current majority GPU market share holder, ditto for the current CPU market share holder also. If I were AMD and Server/HPC partners I would be gifting some Epyc server systems and sponsoring some academic computing cluster competitions and getting that mind-share and experience base created so there can be the ready and trained recruits as that EPYC market share begins to grow.
Also, I’d also like to know just how much of that SeaMicro IP that AMD is Licensing/Sharing with its Epyc Server Motherboard and Server/HPC systems partners in order for AMD get some mileage out of any of that SeaMicro IP that AMD still holds the rights to, in spite of AMD’s SeaMicro division being shuttered. SeaMicro(AMD) has some very good IP that should still have a shelf-life for some years to come. So how much SeaMicro DNA is there in any part of the Epyc platform ecosystem now and maybe in the future.
P.S. Also consider that currenty the Epyc(As well as consumer Ryzen/ThreadRipper) platforms all make use of that singular Zeppelin Modular Die, with AMD netting a rumored 80%+ wafer yield on any Zeppelin dies. And the next GPU generation after Vega, Navi, will also make use of a Modular GPU die probably on a silicon interposer. So that has and even greater BOM implication for ANY Navi GPU/wafer yield issues that currently are poor mostly due to the GPUs much larger currently utilized very large monolithic die sizes.
Even using the current very large monolithic GPU dies, if one looks at the current modular/repeated indipendent GPU functional units, one can easily see that GPU are already broken down logically on the large monolithic dies in such a way as to be composed of many indipendenty functioning units. and these units can be easily broken apart(Via some simple re-engineering) and physically and reassembled on a silicon interposer package with the silicon interopser hosting the inter-indipendent GPU functional unit connection fabric. So GPUs are ready made for being broken up into smaller dies and married up via a silicon interposer which can also host HBM2/newer die stacks and CPU core complexes.
AMD’s more open software/middleware ecosystem will allow AMD to keep it’s development cost(Software as well as Hardware) to a minimum and on that software/middleware side AMD’s ROCm will spread/amortize those costs beyond currently AMD’s more limited budget relative to the competition’s. AMD open software/middleware development will be an AMD/Community Partners supported environment that will become self supporting with very little full investment burden for AMD itself, and software development/software upkeep costs easily outstrip initial hardware costs in a very short time frame.
The problem is might be too late. Look at every ML/DL framework 100% of them support nVidia CUDA/CuDNN. And maybe you find one or two if you’re lucky that support AMD and often only badly.
So AMD has already lost the mindset. While nVidia is already on Version 8. There is even more Intel API-support now as they have realized earlier they need to do something to not be left behind.
I hate to say it but a lot of it has to do about perception. And the perception in the community is that nVidia is fully commited and serious while AMD doesn’t really matter it is not even on the radar of those people.
Non-vendor platform and stuff might be nice on paper, but in reality only very few people care the majority just want something that works and is easy to use and if I need to buy a certain piece of hardware that gets me there I do it as it is still cheaper than to spend 100s of hours getting it working on another piece of hardware that might be cheaper. And certainly hyperscalers don’t give much crap about if a solution is open source/platform or not.
So AMD should just ditch that mantra since honestly I don’t think it has provided them with any edge so far anyway. They should concentrate on something that is easy can be a plug-in replacer and provides maximum performance on their platform.
As obviously that strategy doesn’t seem to hurt either Intel nor nVidia having non-vendor-specific APIs and solutions.