
Computing, which always includes storage and networking, evolves. Just like everything else on Earth. Anything with a benefit in efficiency will always find its niche, and it will change to plug into new niches as they arise and make use of ever-cheaper technologies as they advance from the edges.
It is with this in mind that we ponder the datacenter. As in the center of data, which has been expanding and thinning for a very long time now, and which is pushing itself – and us – to the edge. What, we wonder, is a datacenter that doesn’t have a center? Or where is its center of gravity – meaning the totality of its compute and storage – if it is not in one or a few bit barns, but rather scattered across a hierarchy of devices, all doing server-style computing with local and remote storage, hooked in such a manner that it is hard to say which layer is in charge and which ones are not?
We have said this many times, and we will say it again. History doesn’t repeat itself, moving in circles, but rather, it moves in a spiral, coming back along a similar curve but ending up somewhere unique and yet similar, and kind of fractal pattern moving outwards along a bend from the center, returning again and again and again, and yet still different.
Historically, we have tending to think of the advance of technologies as moving up from below, but this is not accurate. It is more like a solar system.
The proprietary minicomputer did not attack the mainframe from below, but from the edges. That great-great-grandaddy of computing, which was epitomized by the System/360 mainframe launched in April 1964, was the first electronic inhabitant of the datacenter – back when it was colloquially called the glass house because of the vaunted place that these very expensive pieces of machinery held in the businesses of the very few companies that were rich enough to afford.

The mainframe displaced electromechanical punch card and tabulating equipment, which was invented by Herman Hollerith, a former US government employee for the Census Bureau who wanted to speed up the 1890 census and won the contract to do so, thus laying the foundation for International Business Machines and therefore the rest of the computing industry as we know it. By the way, the 1890 census finished far ahead of schedule and vastly under budget because of the automation of the tallying, setting a very high bar that very few IT projects have vaulted since.
By the late 1960s and early 1970s, the benefits of back office computing – meaning, doing the accounting gruntwork of sending out bills and collecting payments – had been so aptly demonstrated that other, cheaper kinds of computing were invented to make it more broadly available. This is when Digital PDPs and VAXen, IBM System/3 through System/38, and HP 9000 iron came into being, and they were not only the mainframes for the forward thinking small and medium businesses, but often were used as adjunct processors for mainframes for specific kinds of work (often process control in manufacturing or distribution operations).
In the 1980s, along came personal computers, and another ring of compute was wrapped around these mainframe and minicomputer centric systems. At first, all they did with regards to the datacenter was emulate mainframe and minicomputer terminals, giving remote users access to the same old applications on these legacy systems. It was not too long before companies started using this local compute layer, pushed out to the periphery, to actually do some of the processing – the so-called client/server computing revolution. In the middle of the 1980s, RISC-based processors came into vogue along with Unix operating systems for scientists and engineers, and by the end of the decade both the PC and the Unix workstations were tipped on their sides to become servers. In the 1990s, as density of compute became an issue thanks to the commercialization of the Internet and its Web technologies, both PC and Unix servers were refactored into the pizza-box, rack-mounted shapes we think of as normal today. In many cases, these Unix and PC machines replaced the mainframes and the minicomputers, in others they just wrapped another layer around them.
Some people want to consider the cloud another infrastructure ring, but it is more like making use of someone else’s solar system, developed on a more modern software stack, on a time share basis, thus forming a kind of rudimentary galaxy.

That brings us to the edge. Or rather, the new edge, because computing has always had an edge. Up until now, people sitting at terminals or PCs or even their smartphones and tablets were the ultimate outside edge. But now, the datacenter doesn’t serve just people. Increasingly, it is serving other machines, and that is not only changing the nature of the datacenter, it is calling into question the very idea of a data center. We have been contending that we should be talking about data processing along a spectrum of interconnected devices for some time, and history bears this out and the current situation brings it home, with technologies like machine learning smashing through the glass house windows.
It is hard to say for sure how much telemetry is being generated by devices at the edge, but it ranges from very tiny devices with sensors that might be used in medicine or agriculture to sophisticated networks of devices gathering all kinds of information in a smart city. The growth in the number of these devices is enormous, with about 2 billion so-called smart devices on networks in 2006 rising to 15 billion devices in 2015 and expected to hit 200 billion devices by 2020. With more than an order of magnitude of growth in the number of connected devices within five year, it would be easy to extrapolate that the number of servers that back-end all of these devices will also have to grow by an order of magnitude. This might happen, but it won’t all be located in the datacenter as we know it. And for a lot of different reasons.
While no one can deny the economies of scale and scope that come from being a hyperscaler, there are tremendous pressures at work that are pulling compute out of the datacenter and towards the edge. As the old saying goes, compute is cheap, storage is cheaper, but data movement is very expensive, and this holds true with modern distributed applications. But it is more than this.
Given our mission of covering the technologies that underpin the next platform – one that has in fact spanned decades of our careers – we will be expanding beyond that core datacenter that we are all familiar with and to the edge devices that will be taking a new twist on compute and storage. There are a whole slew of upcoming companies that are bringing new technologies to bear – as well as incumbents expanding into adjacent markets – and these will alter the nature of data processing in the years to come.
In some cases, there is no way to have a constant connection back to the datacenter, and the latencies between the machine running in the field and that datacenter are so great that something bad could happen while the machine was waiting to be told what to do. Something closer to the ground has to be available to crunch data, whether it is embedded in the device itself or close to it. A self-driving vehicle (whether it is a small car moving people or a large 18-wheeler moving goods) has to have an enormous amount of compute in it to drive and to perhaps make new inferences in its machine learning algorithms on the fly, but it also has to be cheap to keep the cost of the car down. In other areas, such as for online applications that run on service provider networks, providing an adequate level of service – meaning reducing latency – might mean embedding servers and storage in 5G base stations. In other cases, data sovereignty and data locality issues will come into play, and data will have to be stored close to the edge.
Here is how Intel, which pretty much owns datacenter compute at this point, sees the 5G wireless edge:
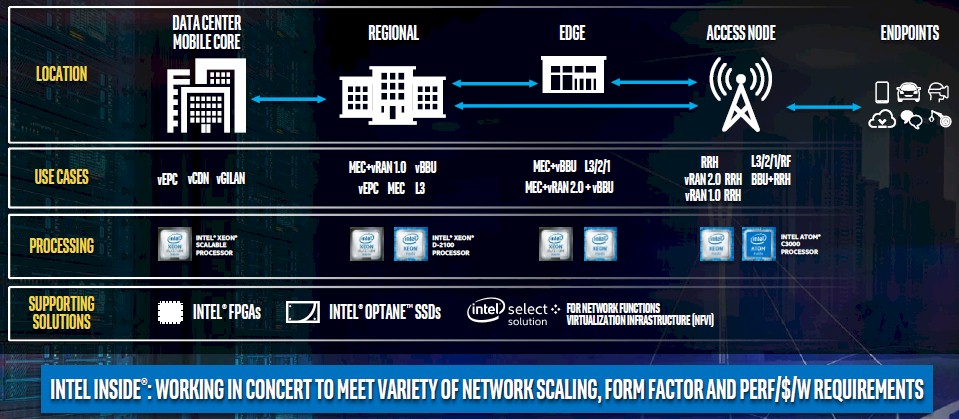
And here is how it thinks the edge scenario looks for cloud service providers:
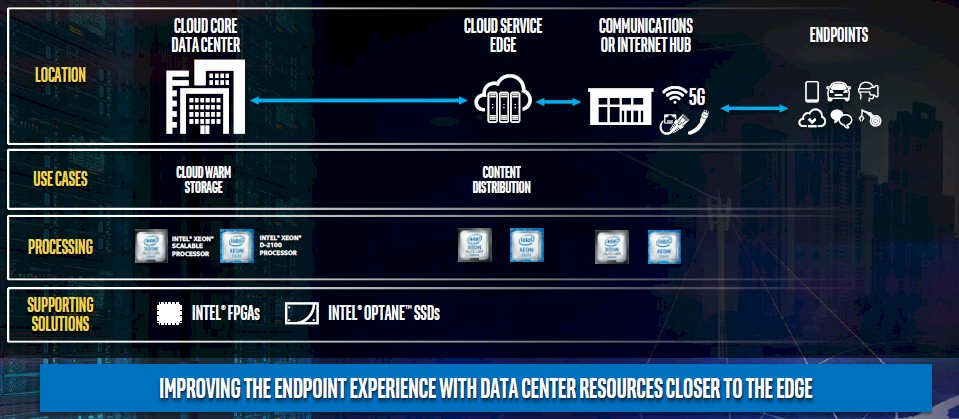
The question is how much compute and how much storage will be pushed to the edge; the network is easy, in that it will follow the demands of compute and storage. Right now, there are maybe 40 million servers in the world, and they have two sockets for the most part and they probably have an average of around 12 cores to 16 cores. Call it 1.1 billion cores. There is no way that we believe that the datacenter as we know it will consume more than 10X more servers in five years, and even if the core counts increased over that time, the average core count would probably only double so you would still need 5X as many physical devices. We do not think that companies will increase their server budgets by a factor of 5X. They never have, and they never will. They will look for cheaper ways to do the processing, and that means also choosing smaller, cheaper devices.
The network is also pushing things to the edge, and increasingly on wireless networks that, ultimately, have to connect to datacenters through carriers or private networks that are on wired lines. While the wireless network protocols used on our cell phones have advanced — 3G networks ran at 2 Mb/sec and improved by an amazing 500X to get to 1 Gb/sec with 4G networks — the jump to 5G is only going to increase this by a factor of 10X to 10 Gb/sec. That is as much bandwidth coming out of a typical server port, so 5G will find uses where there is adequate cell coverage; there is debate about whether the combination of 5G plus a fair amount of compute inside a car will, for instance, be sufficient for a self-driving car to work properly. Drones and other kinds of devices might be restricted to the much more restricted ranges (around 100 feet) but higher bandwidths of WiFi networks that, again ultimately hook back into some kind of wired network that feeds into a datacenter. The 802.11n standard delivers 600 Mb/sec of peak bandwidth and usually around 100 Mb/sec in actual use, while the 802.11ac standard delivers 1.3 Gb/sec peak and somewhere around 200 Mb/sec in reality. The point is, the more data can you chew out on the device, the less you have to pass back over whatever networks connect the edge to the core.
The economics as well as the application demands are both going to push computing and storage to the edge.
We don’t know how much, and by the way, neither does anyone else.
Intel says that people with smartphones and PCs are using about 1.8 GB per day, that a drone generates 18 TB per day, that a self-driving car generates 4 TB per day, and a virtual reality experience burns 3 TB per minute. Some of this capacity is just shifting to richer media, of course; mainframes dealt with simple text data to process transactions, not with presenting our visual cortex with a fake reality. Networking giant Cisco Systems took a stab at it. The company’s prognosticators estimate that by 2021, more than 850 zettabytes (ZB, or 850,000 exabytes or 850 million petabytes) of data will be generated by people and machines globally in the world. They estimate further that about 90 percent of this data will be ephemeral in nature and not permanently stored, but it will, presumably have to be processed in some fashion. This useable data created per year is larger than the datacenter traffic each year by a factor of 3X in 2016 and will rise to be a factor or 4X by 2021. Take a look:
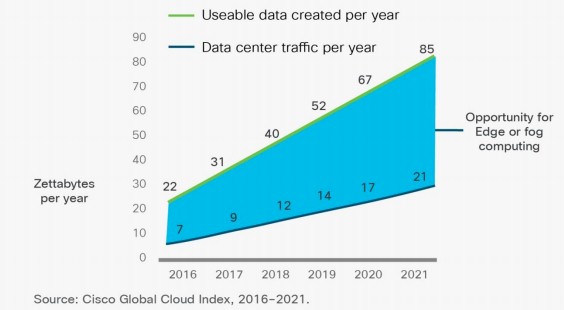
The only reason to have data is to compute against it, and we think that there will be an aggregate rise in compute and that a very big portion of it will be pushed to the edge. At first, the edge will be small, but the persistent high cost of data movement will force organizations to make the move whether they like it or not. And to be honest, whether we like it or not, because the next platform is going to have an extremely distributed nature that is largely done with machine-to-machine applications. There could be one or two orders of magnitude more server-style compute out in the edge, chewing on data locally and reacting to situations, than is back in the traditional datacenter. The data growth may not be quite as large, given the ephemeral nature of the storage for a lot of machine-to-machine data. But, then again, people have like to keep as much data as they can, and they often don’t know why, and so long as the cost of storing data is not egregious and the cost of local processing is not too high, then they will be compelled to do it.
There has been a lot of talk about whether or not public cloud computing (which allows organizations to run their own software or that which it buys from third parties) and hyperscale computing (which provides consumer facing applications and storage for free or for a modest fee) will take over the datacenter. Our observation is that the hyperscalers are smart enough to keep full control of their stacks, but their cloud divisions have the express purpose of trying to convince companies to let go of their own. This strikes us as folly, given that a company is really just the encapsulation of the software that it uses to run itself and provide its services. But here again, economics may prevail, Being able to run your own infrastructure in the future might be something only the rich can do.
The real value in the next platform, in fact, might be out on the edge, and companies could decide to own their own edges and outsource their datacenters to the clouds.
It will be interesting to see how complex and ornate this computing and storage galaxy grows. Given our mission of covering the technologies that underpin the next platform – one that has in fact spanned decades of our careers – we will be expanding beyond that core datacenter that we are all familiar with and to the edge devices that will be taking a new twist on compute and storage. There are a whole slew of upcoming companies that are bringing new technologies to bear – as well as incumbents expanding into adjacent markets – and these will alter the nature of data processing in the years to come.


Dell Ties Storage To Kubernetes, Sharpens Edge Strategy
Dell Technologies, since its founding 37 years ago, has been about infrastructure — from the servers, networking systems and storage appliances that populate enterprise datacenters to the corporate clients that are designed to make employees more productive. Infrastructure is what has driven Dell to become a multinational IT giant that …
Ethernet Switching Bucks The Server Recession Trend
You might be thinking that with all of the investment in AI systems these days that the boom in InfiniBand interconnect sales would be eating into sales of high-end Ethernet interconnects in the datacenter. This is not the case. According to the latest market research from IDC, there is enough …

The Edge Is The New Frontier For IT
The datacenter is becoming hyperdistributed and incorporating some multiple of capacity – 2X, 3X, 4X, or maybe 10X – outside of the traditional datacenter walls because applications and storage live increasingly at the edge. The edge is not just a new frontier for customers, who are being drawn out of …
Be the first to comment