

In 2021, the Argonne Leadership Computing Facility (ALCF) is planning to deploy Aurora A21, a new Intel-Cray system, slated to be the first exascale supercomputer in the United States. Aurora will be equipped with advanced capabilities for modeling and simulation, data science, and machine learning, which will allow scientists to tackle much larger and more complex problems than are possible today.
To prepare for the exascale era, Argonne researchers are exploring new services and frameworks that will improve collaboration across scientific communities, eliminate barriers to productively using next-generation systems like Aurora, and integrate with user workflows to produce seamless, user-friendly environments.
One area of focus is the development of a service that will help researchers make sense of the increasingly massive datasets produced by large-scale simulations and experiments.
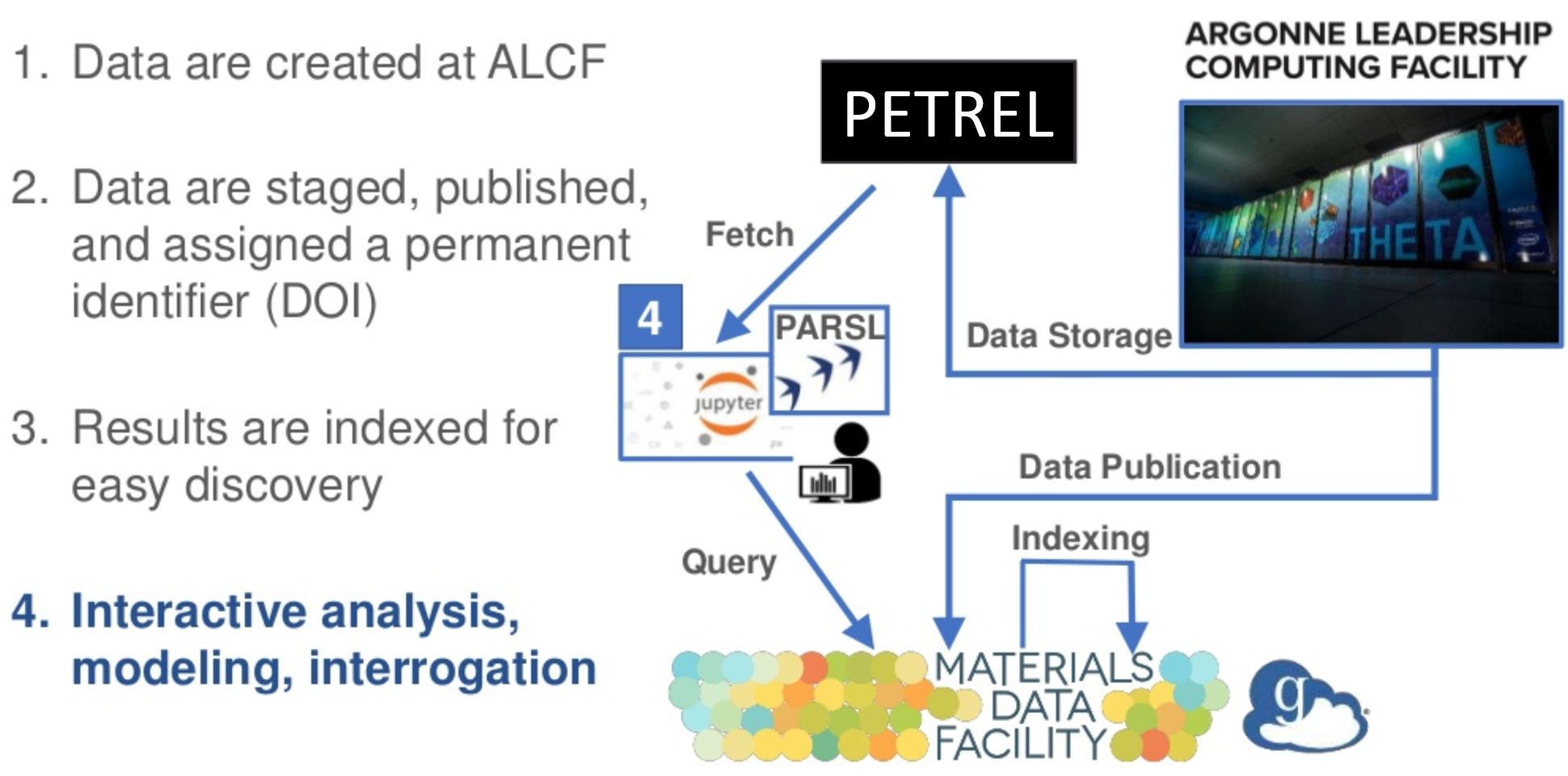
Ian Foster, director of Argonne’s Data Science and Learning Division, is leading a team of researchers from Argonne and Globus to develop a pilot of a lab-wide service that will make it easier to access, share, analyze, and reuse large-scale datasets. The service leverages Globus, which is a research data management platform from the University of Chicago, Argonne’s Petrel system, which is a storage resource that allows researchers to easily store and share large-scale datasets with collaborators, and Jupyter Notebooks, which is an open source web application that allows researchers to create and share documents that contain live code, equations, and visualizations.
Ultimately, the service is aimed at enabling more effective capture and organization of data; discovery and interrogation of relevant data; and association of machine learning models with data collections for improved reproducibility and simpler deployment at scale.
“Our motivation,” Foster explains, “is to create rich, scalable data services so people don’t just come to the ALCF for simulation but for simulation and data-centric activities.”

Materials Science And Machine Learning
To demonstrate the capabilities of this interactive service, the Argonne-Globus team used a large dataset from the Materials Data Facility (MDF) generated by André Schleife, a professor at the University of Illinois at Urbana-Champaign. Schleife’s team produced the data as part of a project that used ALCF supercomputers to simulate electronic stopping power in various semiconductor materials.
The proof-of-concept study aimed to use machine learning techniques to build a model that can act as a surrogate to the computationally expensive time-dependent density functional theory (TD-DFT) method, which the Schleife team used to calculate stopping power in their original simulations.
To create the surrogate model, the researchers first collected raw data from the MDF. They then used Globus as part of the data assembly and staging process, moving the data from Petrel to Cooley, the ALCF’s data analysis and visualization cluster. Using Cooley and the Parsl scripting library, the researchers processed the raw data to define a training set. Finally, the team employed machine learning to build a surrogate model that could replace the TD-DFT computations and reduce the computational cost of calculating stopping power in subsequent simulations. For example, the surrogate model can be used to compute stopping power for particles arriving from directions different to those originally simulated. The whole process is encoded in a series of Jupyter Notebooks, allowing the methods to be rerun each time that new simulation data is produced, and to be easily shared and adapted for other purposes.

Foster states: “I see this as a general approach for how machine learning models will be used in the future. The Globus platform provides needed security and data sharing, movement, search, and automation capabilities. Services like Petrel leverage those capabilities to manage data and users. And Jupyter notebooks permit rapid building and sharing of models and interactive data exploration.”
Looking Ahead
Incorporating these projects into the Argonne lab-wide interactive data service allows researchers to organize and assemble large data collections, apply machine learning to those data to build predictive models, work with these data and models in an interactive Jupyter environment to guide future simulations, and then launch the new computations on ALCF resources. Ultimately, this enables interactive, scalable, reproducible data science, leveraging machine learning methods to reduce simulation costs and increase data quality and value for researchers.
The development of this novel approach also demonstrates Argonne’s efforts to democratize data services for all. The ability to search and analyze data easily using Jupyter notebooks (or associated text interfaces), in addition to the Petrel-Globus solution for simplified data storage and transport, means the combined service can provide an interactive, familiar, and natural computing environment for all ALCF users.
“These capabilities,” Foster explains, “are unique and demonstrate how Argonne is branching out to expand the utilization of ALCF resources for data and learning-based research. We are leveraging what we learn with the data service so that we and others can apply the lessons learned at Argonne to develop similar solutions elsewhere.”
Rob Farber is a global technology consultant and author with an extensive background in HPC and advanced computational technology that he applies at national labs and commercial organizations. Rob can be reached at info@techenablement.com


Intel Let The Chips Fall Where They Might
This day always comes. It is the nature of monopoly and hubris. It came for IBM. It came for Microsoft, and it is coming for Facebook. It will come for Google and, even though it is hard to believe, it will come for Amazon. And it is most assuredly coming …

The Roads To Zettascale And Quantum Computing Are Long And Winding
In the United States, the first step on the road to exascale HPC systems began with a series of workshops in 2007. It wasn’t until a decade and a half later that the 1,686 petaflops “Frontier” system at Oak Ridge National Laboratory went online. This year, Argonne National Laboratory is …
First Look At Oak Ridge’s “Frontier” Exascaler, Contrasted To Argonne’s “Aurora”
The fiscal year of the federal government in the United States ends on September 30, and whether we all knew it or not, the US Department of Energy had a revised goal of beginning the deployment of at least one exascale-class supercomputing system before fiscal 2021 ended and fiscal 2022 …
Be the first to comment