



It doesn’t take a machine learning algorithm to predict that server makers are trying to cash in on the machine learning revolution at the major nexus points on the global Internet. Many server makers rose to satisfy the unique demands of the initial dot-com buildout back in the 1990s, and a new crop of vendors as well as some incumbents are trying to engineer some differentiation into their platforms to appeal to the machine learning crowd.
This is particularly true for servers that are used to train neural nets, which require lots of very beefy GPU accelerators, almost universally those from Nvidia, as well as a few hefty CPUs, lots of main memory and usually fast networking, too. Cramming this plus enough storage to be useful into a single node that is then clustered to scale out performance in a parallel fashion (like transitional HPC workloads) is a challenge. But the opportunity is large enough – and profitable enough – that after a bunch of customers started asking for a server that plugged into its Unified Computing System framework, could be managed by the UCS Manager stack, and integrate into the UCS network fabric. This means that UCS customers that want a single vendor and management scheme for their infrastructure don’t have to go outside of the UCS fold to do it.
They want one more thing, Todd Brannon, senior director of data center marketing at Cisco, tells The Next Platform, and that is to unify the platforms that are doing more traditional data analytics, based on tools such as Hadoop and Spark, with those that are doing machine learning training. This way, the iron can be used for multiple purposes while the data needed for both workloads is located on the same clusters. Moving data between a Hadoop cluster to a TensorFlow machine learning cluster is such a hassle that it makes economic as well as technical sense to put a lot of data storage on a machine learning node and have some of those GPUs go dark silicon some of the time. Machine learning algorithms work best with more and more data, so moving data between clusters becomes an inhibiting factor in trying to increase the accuracy of machine learning algorithms.
“The UCS installed base, particularly government agencies and enterprise customers getting started with machine learning, wants a UCS machine learning system,” says Brannon. “But there is more going on that that. Datacenters and data sources as increasingly distributed, even out to the edge, and data scientists are pushing the IT department to the bleeding edge. And making it even more complex, the predictability of applications is going away.”

Cisco doesn’t control its own big data or machine learning stacks, but it is relying on the tools from Cloudera and Hortonworks, which mash up the HDFS distributed file system from Hadoop with various machine learning frameworks. Cisco is also endorsing the Kubeflow containerized variant of Google’s TensorFlow machine learning framework, which as the name suggests packages up TensorFlow in Kubernetes containers for it to be deployed on clusters.
The UCS C480 ML rack server is like other C Series models in that it does not slide into the UCS blade enclosure but it does make use of network fabric extenders, which provides virtual networking to both B Series blades inside of the UCS enclosures and out to external C Series rack machines. For the machine learning workloads, Cisco is recommending that customers use 100 Gb/sec adapters that plug into regular PCI-Express 3.0 x16 slots, but legacy 40 Gb/sec fabric adapters are also available and, interestingly, for those customers who need InfiniBand for low latency and high bandwidth, Cisco is qualifying rival 100 Gb/sec ConnectX-5 adapters from Mellanox Technologies for those customers who want to use Switch-IB 2 InfiniBand switches. But for most customers, Cisco is recommending that they go with Nexus 3000 series switches that support RoCE v2 remote direct memory access and the GPUDirect protocol between the memories on the GPUs.
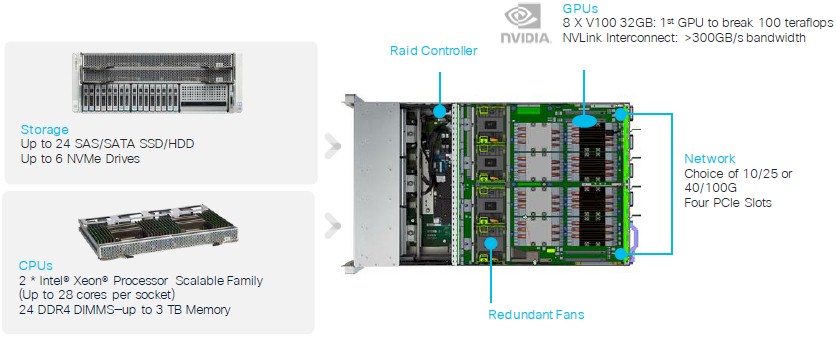
The Cisco machine learning system supports up to eight of Nvidia’s “Volta” V100 GPU accelerators, which are mounted in the SMX2 sockets. Brannon says that the GPUs are configured in such a way that the rear four GPUs have taller heat sinks so they can capture cold air flowing in from the front of the chassis, with the four in the front being shorter and now heating up the air in front of the back four. This simple change allows for the Volta GPUs to run at full speed, and in many cases, with other eight GPU server nodes, the Voltas have to be geared down to keep cool. These Volta GPUs are linked to each other through NVLink 2.0 ports and to the “Skylake” Xeon SP processors by PCI-Express switches integrated into the system board.
The C480 ML system has room for 24 flash drives, with a combined 182 TB of total raw capacity; six of these drives support the high bandwidth, low latency NVM-Express protocol. The Nvidia DGX-1 only has four drives for a total 7.68 TB of capacity – not enough for it to be used as a data lake node in a Hadoop or Spark cluster. (The DGX-2 has a base 30 TB of capacity across eight 3.84 TB NVM-Express drives, expandable to 60 TB, but that is still kinda skinny on the capacity.) The Skylake CPUs, by the way, are on a separate compute tray that can be upgraded separately from the rest of the system and that top out at 3 TB of main memory capacity.
A big differentiation between the UCS C480 ML and the Nvidia DGX machines is that they are not fixed configurations. The DGX-2 has Skylake Xeon SP processors and uses the NVSwitch interconnect created by Nvidia and launched back in March for shipments about now to connect sixteen of the Volta GPUs into a low latency cluster with memory semantics between the GPU memories. The DGX-1 costs $149,000 and is most like the Cisco C480 ML, while the much beefier DGX-2 costs $399,000. These are fixed setups, but Cisco is allowing for customers to mix and match the configurations, depending on their workloads. A fully loaded machine tops out at $500,000 – a lot of that is the flash memory and main memory on the CPUs – but Brannon says the typical configuration should cost around $150,000, essentially the same price as the DGX-1 which it resembles. We figure that once Nvidia makes the raw GPU compute trays with the integrated NVSwitch circuits on them available to third parties, Cisco will do a C Series rack machine that packs the same compute wallop as the DGX-2.
One last thing: This C480 ML system would be good for GPU accelerated databases, like MapD and Kinetica, of course. So you could converge three different workloads onto the system, not just two.