


It would not have been an Architecture Day, as it was earlier this week at the former estate of Intel co-founder Robert Noyce, if the chip giant did not unfold a few pages in the roadmaps for its future CPUs and GPUs.
The details are a little sparse, as they often are, on roadmaps that are revealed to the public. But the actual product roadmaps, which insiders and key customers and ODMs and OEMs see are several inches thick when they are printed out, as Raja Koduri, senior vice president of the Core and Visual Computing Group, general manager of edge computing solutions, and chief architect at Intel, explained in his keynote at the Architecture Day event. That stack of data does not count the substantial number of revisions that this broad portfolio of compute, networking, and storage products undergoes as they make their way to market or, as has happened often in the past couple of years, don’t.
There is no question that Intel is under the most intense competition that it has seen in more than a decade, and this is healthy for both Intel and its rivals in the datacenter. But only a fool would ever think for a second that Intel, when it is focused by its legendary paranoia, can’t recover from missteps and deliver compelling chippery. It has happened time and time again, as we all know, and the reason why is simple: What Intel, and its rivals, do is exceedingly difficult.
At some level, it is amazing that any chip ever comes out on time, much less behaving as it was expected to by its designers. Modern CPUs, GPUs, and FPGAs are arguably the most complex devices ever created, and it is important – and fittingly kind – to step back and appreciate what has been accomplished in six decades of computing in the datacenter and the key role that Intel played in making innovation happen both in terms of the manufacturing and the evolving architecture of chips. This is a market that is always hard, and that is why the rewards are so great for the victors.
Ronak Singhal, an Intel Fellow and chief core architect at the company, unveiled some of the salient characteristics of the future CPU cores that will be deployed in its Core client and Xeon server processors, and even gave a tip of the roadmap book to the Atom processors that sometimes make their way into systems as engines to run storage, network functions, and other workloads in the glass house. Singhal got his bachelor’s and master’s degrees in electrical and computer engineering from Carnegie Mellon and went immediately to work at Intel after graduating in 1997, and notably was on the performance teams for the Pentium 4 processor, whose NetBurst architecture was the one that Intel once thought it could push to 10 GHz way back when. (The thermal densities were too high for this to ever work, as the company discovered to all of our chagrin.) Singhal lead the performance teams for the transformational “Nehalem” Xeons, which debuted in 2009 with a revamped architecture, and their follow-on “Westmere” Xeons, and after that led the core development for the “Haswell” Xeons. These days, Singhal is responsible for the CPU core designs for the Core, Atom, and Xeon families of chips.
There are some significant changes coming with the future cores used in the Core and Xeon processors, and Singhal walked us through some of them during his keynote at the Architecture Day earlier this week. Without further ado, here is the roadmap for the Xeon/Core and Atom cores:

As you can see, there will be an annual cadence to microarchitecture updates to the cores used in the Core and Xeon lines, matching the continual (and probably annual) updating and refinement of the 14 nanometer and 10 nanometer manufacturing processes, as we discussed already earlier this week. This means that the old tick-tock model is officially dead for the Cores and Xeons, a manufacturing and design approach that Intel has used effectively for more than a decade to mitigate risk by only changing one thing – processor or microarchitecture – at a time. But the AMD and Arm competition is picking up the pace, with an annual cadence of design refinements coupled with manufacturing process improvements, so Intel has to quicken its steps and absorb a little more risk. We figure that Intel is hedging a bit these days, and aims to convert the monolithic Cores and Xeons into multichip module designs, mixing chiplets with different functions in appropriate processes, as AMD, Xilinx, and Barefoot Networks have confirmed they are doing with their chips coming in 2019. We will not be surprised at all if processing cores of the future “Ice Lake” Xeons are implemented in 10 nanometers but other parts of the socket – probably memory and I/O controllers – stay in a very refined and mature 14 nanometer process. That’s what we would do.
The “Sunny Cove” core that is coming in 2019 – we presume late 2019 for hyperscalers and cloud builders and for shipment to other customers some time in 2020 – and that will end up in the Ice Lake Xeons, which as far as the roadmaps we have seen show it coming out about 16 months after the impending “Cascade Lake” rev on the current “Skylake” Xeon SP processors. (Frankly, we expected for Cascade Lake to actually be launched for wider sale at Architecture Day, which it was not.)
With Cascade Lake, which we detailed back in August, Intel is pulling in the Vector Neural Network Instructions (VNNI), which are being marketed under the DL Boost brand, that were originally going to be part of the Ice Lake Xeons, which will help Intel defend its machine learning inference turf in the datacenter. Basically, Intel is supporting 8-bit integer (INT8) and 16-bit integer (INT16) data formats in the AVX-512 vector coprocessors on the Xeons, allowing for more data to be crammed and chewed on for inference workloads. In an INT8 convolutional inner loop for inference, it takes three instructions to process on the Skylake using 16-bit floating point (FP16), and now it takes one instruction on Cascade Lake. So the AVX-512 units can process three times as much data per clock. If customers want to use the fatter INT16 format, they can get a 2X speedup over the way it was done on Skylake with FP32.
The double-pumped “Cascade Lake AP,” which we detailed here last month, will put two whole 14 nanometer, 24-core Cascade Lake SP processors into a single socket and is expected in what looks like April or May of 2019. This will be aimed at HPC customers in particular, as far as we know.
Cascade Lake is to be followed in late 2019 with “Cooper Lake,” and it looks like the Xeon SP line will be on an annual cadence with launches late in the year again, with Ice Lake sliding in on a slightly different cadence. The big change with Cooper Lake will be support for the bfloat16 format that Google created for the third generation of its Tensor Processing Units (TPUs) and that is also used in the Nervana neural network processors. Floating point numbers are comprised of bits to encode exponents and bits for encoding a mantissa, which expresses the number of significant digits in the floating point number. The bfloat format can express the same range of numbers as an FP32 number, but can do it in the same 16 bits as the official FP16 exponents and mantissas, like this: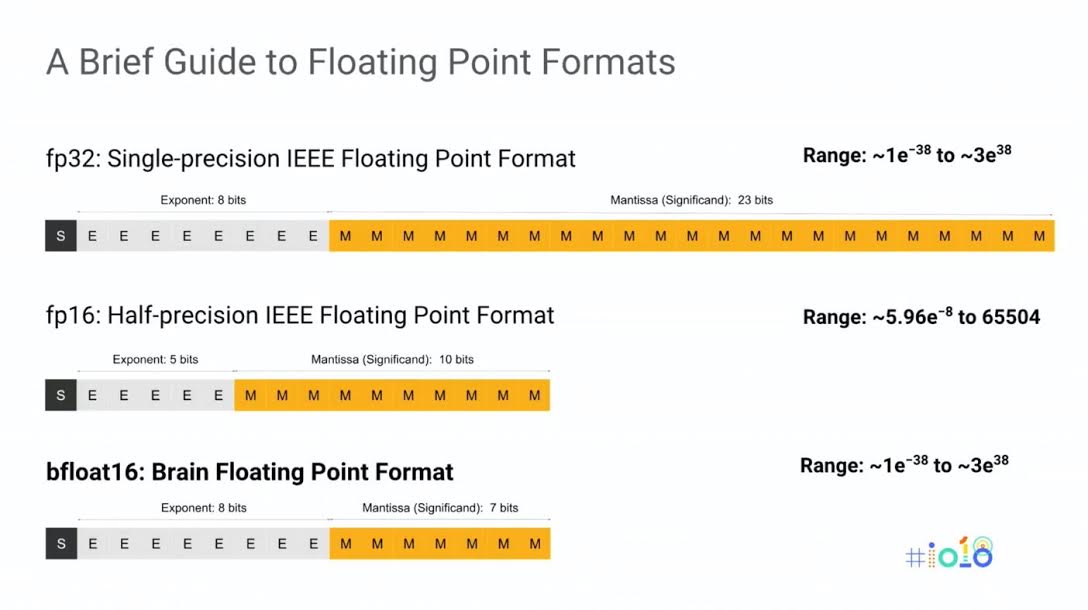
The upshot for the Cooper Lake processors is that the bfloat16 data type will be native to Xeons, and it will offer twice the number crunching throughput per clock cycle as the FP32 format at the same numerical range. This, says Singhal, will help accelerate machine learning training on Intel Xeons. Further down the Xeon road, Intel is promising to add instructions and other features that will provide a “step function improvement in both inference and training” natively on the Xeons, but it is not being specific about how it will accomplish this.
That brings us, finally, to the Sunny Cove core that is going into the Ice Lake Xeons. The strategy here is to make the instruction pipelines in the Xeons wider so they can execute more instructions in parallel, deeper so there are more opportunities to find the parallel streams to keep these wider pipelines full, and smarter so the latencies in moving data and processing instructions are lower. This includes integer and floating point processing, of course, but it also includes things like these special machine learning instructions as well as cryptography, compression and decompression, various kinds of SIMD and vector processing, communications and networking, particularly when it comes to communication between cores on a chip and out to accelerators.
The Sunny Cove architecture is quite a bit different from the core design that is being used with Skylake, Cascade Lake, and Cooper Lake, as Singhal showed:
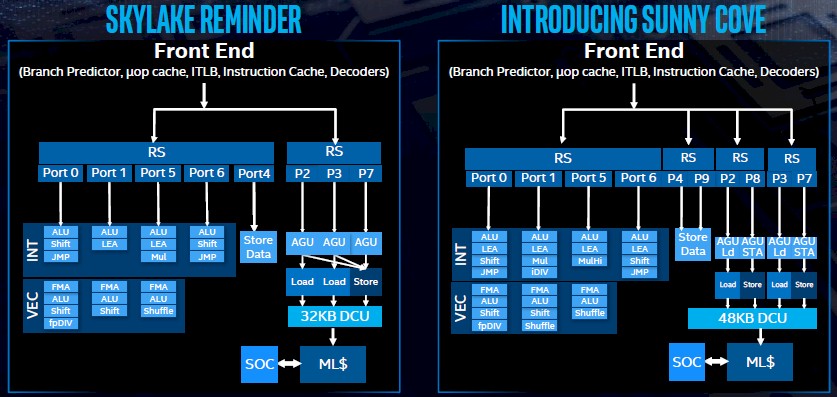
Intel did not divulge any changes it has made in the front end of the processor, where branch predictors, micro-op cache, instruction translation lookaside buffer, instruction cache, and decoders all live to feed instructions into the core to be executed.
In the Skylake architecture, there were two reservation station (RS) schedulers, which figure out what instructions are running and then executes them down on the integer and vector units in the core. With Skylake, there is one data store operation and seven possible instruction executions in each clock cycle. The four ports –Ports 0, 1, 5, and 6 – on the left of the Skylake block diagram are for execution of integer or vector instructions, Port4 does the data store, and Ports 2, 3, and 7 do memory instructions in relation to the Level 1 data cache, which has weighed in at 32 KB for more than a decade. With Skylake, you can do two loads and one store with every clock cycle.
“With Sunny Cove, what you will see is that at each level of the pipeline, we have made improvements,” explained Singhal. “Let’s first talk about deeper. When we look at the structure of the processor, one of the ways we are able to provide better performance is by being able to look at a deeper and deeper set of instructions to find parallelism, to find instructions that are independent of each other and run them simultaneously. The more instructions I can look at, allows me to find more operations to work on, which is one way to drive my instructions per clock. If you look at the fundamental structures inside of Sunny Cove, whether it is the reorder buffer, the load buffer, the store buffer, the reservation stations – all of them grow substantially compared to Skylake.”
To feed all of those increased buffers, Intel is cranking up the data cache on each core by 50 percent to 48 KB. (SRAM is expensive in terms of transistor budget and relative cost compared to DRAM, at about 1,000X higher, which is why the L1 caches – and indeed L2 caches and L3 caches when they are present on processors – are not much larger.) The L2 caches on the Sunny Cove cores is also going to increase compared to the Skylake cores (and its Cascade Lake and Cooper Lake follow-ons), but Intel is not saying by how much. The micro-op cache and the instruction TLB will also be larger with Sunny Cove.
The wider part is immediately obvious in the block diagram above. Sunny Cove sports twice as many resource stations hanging off the front end of the core. The integer and vector units have the same ports as in Skylake, but now the data store unit has its own two-port resource station instead of hanging off the execution units. And the memory unit now has two resource stations, each with two ports, that feed down across four pipes into that expanded L1 data cache. The out-of-order allocation units on the front end can handle five operations per clock, instead of four with Skylake and its derivatives. There are two load and two store units for the L1 cache, each with their own ports, and the whole memory circuit is more balanced with address generation units (AGUs) tied specifically to loading or storing instead of sharing stores. Add it all up, and the bandwidth into and out of the L1 cache is 2X in the Sunny Cove core as is available in the Skylake and derivative cores. On the execution side, there are SIMD shuffle units that perform shuffle operations that are common in HPC and machine learning workloads, an integer divider unit to help reduce latencies for these operations, and there are a slew of instruction enhancements to accelerate cryptography, shifts, and bit shuffles, and memory encryption is added as well.
Let’s Get Physical
Perhaps the most significant addition with the Sunny Cove cores is a fatter memory. While Xeon processors have had 64-bit processing and 64-bit virtual memory addressing for applications and operating systems, but the underlying processor thinks in terms of linear addresses that are calculated from the virtual addresses and physical addresses that are calculated from the linear addresses to set up memory pages. The point is, the “real” memory accessible on Xeon processors is considerably smaller than the 64-bits implied in the architecture.
The linear addressing on the Sunny Cove cores will be 57 bits, getting closer to the top-end 64-bit that is possible in the architecture, up from 48 bits with the Skylake and derivatives and the earlier “Haswell” and “Broadwell” Xeons. The upper limit on the physical addressing with the Sunny Cove chip is what matters most. With the Skylake and prior chips, the physical addressing was capped at 46 bits, which translates into an upper physical memory in the system of 64 TB. This is one reason why you don’t see a lot of machines with more than eight or twelve sockets in the Xeon SP line. For one thing, memory is too expensive and the premium is high for Xeons that can reach the top-end 1.5 TB per socket upper limit of the Skylake Xeons. Moreover, chipsets like the NUMAlink 6 and NUMAlink 7 from Hewlett Packard Enterprise (the former SGI) can harness up to 32 sockets in a tight or loose NUMA configuration. (This is important for in-memory processing.) With that setup and using 256 GB memory sticks, such a system fully loaded would have 12 memory slots per socket and 96 TB of main memory. Ah, but the physical addressing with the Skylake and earlier Xeons stops at 64 TB. So, you can drop back to 128 GB memory sticks and only get 48 TB.
This isn’t bad, mind you. The “Nehalem” Xeon 5500 processors from early 2009, which are when the chip architecture last changed in a major way, topped out at 40-bit physical addressing, or 1 TB. No one ever got anywhere near that given the cost of main memory. With the Sunny Cove’s 52-bit physical addressing, main memory could, in theory, scale up to 4 PB. Assuming a doubled-up Xeon AP socket, which could have up to 16 memory controllers we think, to reach 4 PB of memory using 512 GB memory sticks, it would take 256 sockets in a NUMA server. This is doable – HPE can do it with the NUMAlink interconnects today, but the memory accesses for local to the processor and across the cluster are extremely unbalanced so performance is difficult to tune for some applications. The point is, there is probably a decade of memory headroom by moving to 52-bit physical addressing. The memory capacity nine years ago on the Xeons was 1 TB and it will be is 64 TB through the Cooper Lake Xeons in 2019; another factor of 64X increase puts you at 4 PB, the current cap on physical addressing. If DRAM suddenly got cheaper and memory controllers much more parallel, physical memory capacity could accelerate.
With the follow-on “Willow Cove” cores coming in 2020, Intel we do a redesign of the cache hierarchy as well as optimizing its 10 nanometer process for some performance tweaks; it will also add more security features, and no doubt a slew of hardware mitigations for any Spectre/Meltdown variants that have popped up between now and then. After that in 2021 comes the “Golden Cove” cores, which will sport improvements in single-threaded performance, more instructions for accelerating machine learning algorithms, performance boosts for networking (particularly 5G wireless), and the obligatory security enhancements.
The Atom cores are on a two-year cadence, with the “Tremont” cores that had rumors swirling around about them earlier this year, being etched in the same 10 nanometer processes that Sunny Cove cores will use in the Ice Lake Xeons. The 10 nanometer shrink will yield single-threaded performance improvements as well decreased power consumption and longer battery life for the mobile devices it will be employed within. Intel is also promising network performance improvements with Tremont. “Gracemont” Atom cores add vector processing performance (all you have to do is grab those “Knights Landing” cores, really) plus single threaded performance and a frequency boost through a refined 10 nanometer process. “Next Mont” has IPC and frequency jump again, and probably a shift to 7 nanometer processes in late 2022.
Being Discreet About Future GPUs
So that is what we know about the future CPUs. We know a whole lot less about the future embedded and discrete GPU roadmap at Intel, and frankly, it is the future Xe discrete GPUs due in 2020, which have an annoying brand and which will do not know the code-names of, that are the most interesting. According to David Blythe, Intel Fellow and chief GPU architect, the Xe GPUs will also be available in embedded variants on Core and Xeon processors.
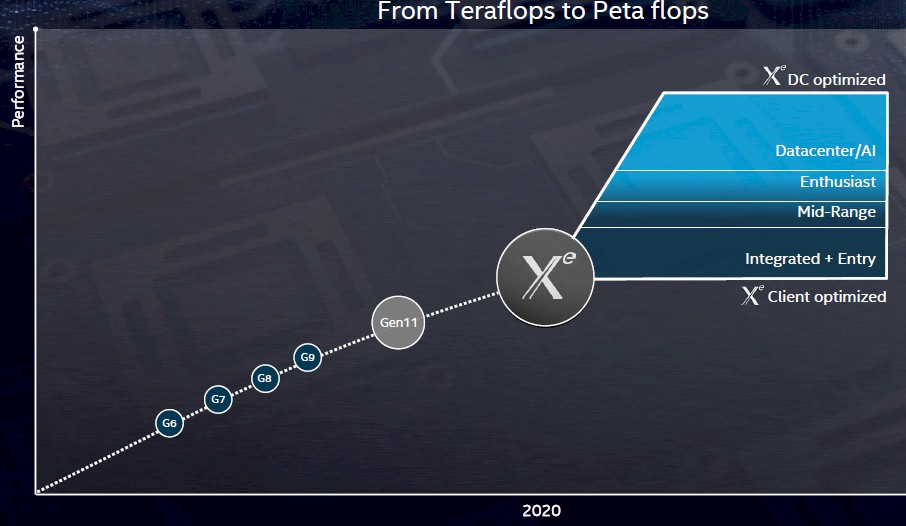
The Gen11 GPUs that Blythe talked about are presumed to be the architectural foundation on which the Xe GPUs will evolve. The Gen10 GPUs were a bit of a science project on the “Cannon Lake” Core processors, which were etched in Intel’s first attempt at 10 nanometer processes, which are not being used for any of the 10 nanometer stuff coming in 2019 and beyond. With the delay in the revamped 10 nanometer wafer baking, Intel decided to keep going to the Gen11 designs while the process roadmap was redrawn.
The Gen10 GPUs have from one to three slices, each with 24 execution units on each slice, with eight execution units on a sub-slice; the chips have varying sizes of embedded DRAM L3 caches, and with Gen11, it is expected to top out at 3 MB across eight banks of cache. That is a quadrupling of the L3 cache size used in the current Gen9 GPUs. (Gen10 doesn’t really count.) That top-end Gen11 GPU part will, in theory, have a total of 72 execution units, but due to yield issues, Intel is only counting on 64 of them being good initially. Intel already ships “Halo” Gen9.5 GPUs on Kaby Lake Core and Xeons, Coffee Lake Cores, and Goldmont+ Atom processors that have 72 execution units, so Gen11 is not much of a stretch.

The Gen11 GPUs employ tile-based rendering and also have coarse pixel shading; they deliver about a 20 percent performance boost over the Gen9.5 GPUs, putting it in the teraflops range at single-precision floating point and half that at double precision and quadruple that at half precision.
Intel didn’t really say anything more about its discrete and embedded GPU plans. But clearly it has a lot of catch up to do to reach AMD’s Radeon Instincts, and even further to go to reach Nvidia’s Tesla GPUs. Intel is going to have to think very long term to stay in this game. Intel has sold over 1 billion of chips with its embedded GPUs in them, which is a pretty good installed base on which to build.