

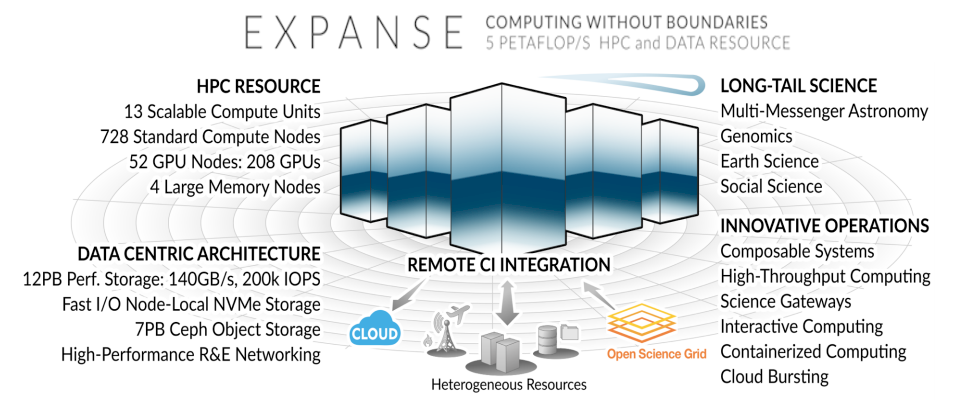
The San Diego Supercomputing Center is overdue for a new supercomputer and thanks to a $10 million grant from the National Science Foundation, next year it will finally get one. Known as Expanse, the machine is expected to deliver about twice the peak performance of Comet, SDSC’s current flagship system that was installed four years ago.
The NSF originally spent $24 million on Comet in 2015 and another $900,000 in 2017 on an upgrade that brought it to 2.76 petaflops of raw compute capacity. The original system was outfitted with Intel “Haswell” Xeon E5-2680 v3 processors and Nvidia “Kepler” Tesla K80 GPU accelerators. The capacity added in 2017 was thanks to 36 new nodes outfitted with 144 Tesla P100 GPU accelerators.
The original $24 million price tag for Comet included funding for operation, while the $10 million Expanse award does not (which will be provided in a separate award). Nevertheless, for about half the price of Comet, SDSC is getting a 5 petaflops machine. Moore’s Law might be slowing down, but over a five-year span, it can still work its magic.
Expanse was officially announced in July, but at last week’s 2019 MVAPICH User Group meeting, SDSC’s Mahidhar Tatineni revealed some additional details about the system’s makeup. Tatineni, who heads the User Services group at SDSC, said the new machine is following in the footsteps of Comet, architecture-wise, and will run the same kinds of science codes that SDSC has been supporting since its inception in 1985.
Expanse will also use the identical cast of vendors that was used to construct Comet – Intel for the CPUs, Nvidia for the GPUs, and Mellanox Technologies (soon to be part of Nvidia) for the system interconnect. And as before, Dell EMC is the system vendor. Aeon is also making a return appearance, in this case, supplying 12 PB of Lustre parallel file system storage and 7 PB of Ceph object storage.
The CPU-GPU split on Expanse is almost the same as Comet, too, with 728 CPU-only dual-socket Xeon SP nodes and 52 GPU nodes. Like Comet, each of accelerated nodes has four GPUs. According to Tatineni, those GPUs will either be the current Tesla V100s or whatever Nvidia manages to cook up between now and the 2020 rollout – the code names that have been kicking around in the rumor mill are “Ampere” and “Einstein” but there is little detail as yet. The fact that SDSC doesn’t might suggest that things are still up in the air, even at this late date, but it also might be that SDSC is not allowed to even hint at its GPU choice whatsoever beyond the vendor name.
One thing is certain. GPU nodes are rather popular at SDSC. Tatineni said Comet’s GPU partitions are typically the busiest ones and are in greater demand that the CPU partitions. Understandably, the higher-performing Tesla P100 nodes are the most requested.
The bulk of this GPU use is for regular HPC applications, including BEAST, a phylogenic analysis code, IceCube, a photon tracking simulation code, and a whole array of molecular dynamics codes (AMBER, NAMD, GROMACS, LAMMPS, and HOODMD-Blue). Over the past couple of years, though, demand for the GPUs node from machine learning and deep learning applications has been growing rapidly. As of now, there are 87 such projects, spread across 50 institutions.
Despite that, these machine learning codes are only taking about 10 percent to 15 percent of the GPU time on these. That’s probably because most of those projects appear to be using those resource to develop their codes, so are currently only using one or two nodes. “It hasn’t got to the point where someone has asked us for all the GPUs to train something,” said Tatineni. “It’s coming though.”
In fact, he’s already starting to see some requests for multi-node GPU allocations on Comet. Which makes it curious that Expanse isn’t starting out with more GPU capacity. As it stands today, the new system will be equipped with only 208 GPUs on Expanse – 80 less than on Comet. Yes, the Tesla V100s (or their successor) will have a good deal more performance than either the K80 or the P100 GPU accelerators. But if demand is growing, that probably won’t be enough to satisfy both the traditional HPC users and machine learning developers. Perhaps SDSC is hoping to get additional funding in a couple of years to include more GPUs, as it did for Comet.
One thing that might help is that Expanse will have something called SDSC scalable compute units, or SSCUs. Each unit consists of 56 standard compute nodes and four GPU-accelerated nodes. A single 40-port 200 Gb/sec HDR InfiniBand switch is used as the network hub; 30 of the ports have been split into two 100 Gb/sec links, which hooks the 60 nodes to one another, leaving ten remaining 200 Gb/sec ports as uplinks.

Resource management of these SSCUs will be done via Kubernetes, which orchestrates container deployment across a system. In this case, some of these resources could even extend beyond the physical confines of Expanse in cases where particular resources are needed but otherwise unavailable. And since cloud bursting will be an option on Expanse jobs, users will theoretically have access to all sorts of extra capacity, like, for example, additional GPUs.
Expanse is scheduled to be deployed in summer 2020.

Cerebras Shows Off Scale Up AI Performance For Big Pharma And Big Oil
Historically, the largest organizations in the world – the Global 2000 plus the biggest national government and academic research institutions – have always had the most complex data processing needs. And by virtue of the size of their IT budgets and the sophistication and scale of their workloads, they get …
AWS Taps Nvidia NVSwitch For Liquid Cooled, Rackscale GPU Nodes
Since the advent of distributed computing, there has been a tension between the tight coherency of memory and its compute within a node – the base level of a unit of compute – and the looser coherency over the network across those nodes. All things being equal, you try to …

Container Approach to Boosting GPU Utilization Secures Bigger Backing
Getting peak utilization out of GPU farms in the age of AI will be the unending quest. From being able to partition a GPU into small fractions to scaling across many GPU-dense nodes, Nvidia has already provided tools to make this possible. However, one startup thinks it has the key …
Not sure how they are getting 64 CPU cores per Compute Node, if they are dual socket Xeon-SP nodes as stated. Current Cascade Lake (2nd Gen) Xeon SP socketed CPUs are limited to 28 cores. Will this be using a yet to be release Xeon SP?
SCU = 56 Compute Nodes x 2 CPU sockets/node = 112 CPUs
SCU with 3584 CPU cores /112 CPUs = 32 cores/CPU?