

Like the large enterprises they sell gear to, the big OEMs are a conservative lot and they take a paced, methodical approach to introducing new technologies into the datacenter.
It takes a while for new workloads to shake out and for hardware and software engineers to figure out the optimal configurations of both to support these new workloads. That, in a nutshell, is why the new Power Systems IC922 server, aimed at workloads that require heavy I/O, such as data storage and databases as well as inference performed on GPU, FPGA, and other ASIC accelerators, is coming to market more than two years after its brawnier Power Systems AC922 older sibling was first announced.
The AC922, as most of you well know, is the server node at the heart of the “Summit” hybrid supercomputer at Oak Ridge National Laboratories and its companion “Sierra” system at Lawrence Livermore National Laboratory. These are the pre-exascale systems built by IBM, with the help of Nvidia and Mellanox Technologies, for the US Department of Energy, and they are the most powerful supercomputers installed on the planet at the moment. Both have Power9 processors as their host computing engines, and then have either six (in the case of Summit) or four (in the case of Sierra) Nvidia Tesla V100 GPU accelerators attached to the processors and to each other via NVLink ports.
While the AC922 has a tremendous amount and variety of compute available, it is overkill for certain kinds of workloads and does not meet the price/performance or thermal needs for others. And so IBM has come up with a variant of the Power9 server lineup that is better suited to running the data ingest and storage workloads at the front end of machine learning training as well as the inference that needs to be done as part of applications once the neural networks are trained on a big box like the AC922.

To do those two bookend jobs in the machine learning workflow requires a machine that has very high I/O capability for the data ingest and storage job and then plenty of room for various kinds of accelerators, linked with very high I/O again, to the host compute complex. And that is what the IC922 is all about. But make no mistake about it. Just like the AC922 can do double duty as a compute engine for traditional HPC simulation and modeling workloads as well as host machine learning training, the IC922 system would make a pretty powerful scientific workstation, with pretty decent GPU accelerated compute and rendering thanks to the addition of a fairly large number of Tesla T4 accelerators from Nvidia.
Dylan Boday, director of infrastructure for the Cognitive Systems division within IBM’s Systems Group, tells The Next Platform that the I in the product name stands for both inference and I/O, and that the C stands for cloud; while we can see the first two making sense, it is hard to reckon the cloud angle here unless IBM intends to deploy lots of these on its eponymous public cloud. The 9 means it has a Power9 chip, the first two means it is a two socket-server, and the second two means it comes in a 2U rack form factor. Here is what the motherboard for the IC922 looks like:
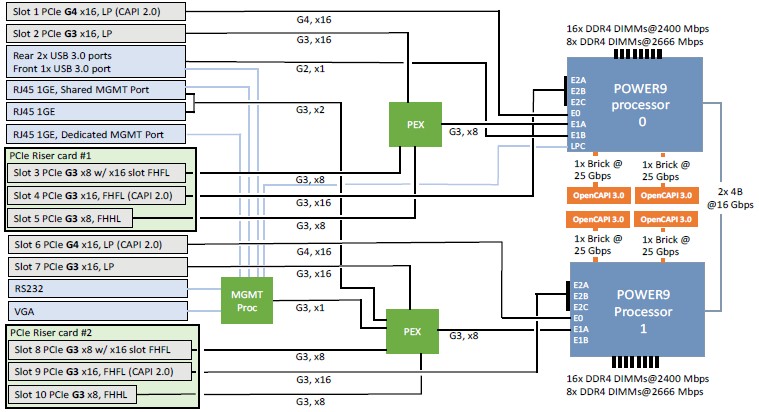
The IC922 system uses the 24-core “Nimbus” variant of the Power9 chip, which has four threads per core (called SMT4 by IBM) rather than the 12-core “Cumulus” variant, which as eight threads per core (called SMT8). In the case of the IC922, the server can be equipped with one of three different Power9 variants, and one of them is not a processor with all 24 cores activated. Customers can choose from:
- A 12-core chip that has a base frequency of 2.8 GHz that turbos up to 3.8 GHz and that burns at 160 watts; it costs $1,999
- A 16-core version with a base frequency of 3.35 GHz that turbos up to 4 GHz and that burns 225 watts; it costs $2,799
- A 20-core variant that runs at 2.9 GHz base with a 3.8 GHz turbo speed that also burns 225 watts; it costs $2,999
The “Skylake” and “Cascade Lake” Xeon SP processors from Intel top out at 28 cores per chip and 56 threads, but these Platinum-level chips are crazy expensive. The more mainstream Gold-level Xeon SPs have 20 cores and 40 threads per socket, and IBM can basically deliver twice as many threads – and therefore potentially twice as many VMs or containers per socket if customers pin one VM or container per thread. And depending on the circumstances with the workloads, given the much higher clock speeds IBM is offering, the threads could be roughly equivalent in performance between Power9 and Xeon SP.
As for main memory, the AC922 was able to use 128 GB DDR4 DIMMs to get its maximum capacity across sixteen slots per socket up to 4 TB on a two-socket system, but IBM is only supporting 16 GB, 32 GB, and 64 GB memory sticks in the IC922 because, as Boday explains, most customers running data ingest or inference workloads are not going to need such huge memory spaces and they are not going to want to pay the heavy premium for 128 GB memory sticks. The main point here is that the Xeon SP processors only have six memory controllers and therefore twelve memory slots per socket, and therefore the Power9 socket has a 33 percent bandwidth and capacity advantage, stick for stick, over a Xeon SP socket. IBM is able to deliver 170 GB/sec of peak memory bandwidth per Power9 socket with 2.67 GHz memory DDR4 populating all of the memory slots, or 340 GB/sec for the combined system.
The I/O slots and bandwidth are just as important, of course, particularly in a hybrid architecture like IBM is pushing with both the IC922 and AC922. The IC922 has ten PCI-Express slots coming off the pair of Power9 chips, as shown in the schematic above, and when the machine is fully equipped with two dozen NVM-Express flash modules, it can drive 1 TB/sec of I/O bandwidth into and out of the storage and still have enough I/O left for some high speed networking adapters. This is a very powerful storage server by any measure.
At the moment, the Tesla T4 GPU accelerator is the only offload motor that is officially supported on the IC922. The Tesla T4 comes in variants with PCI-Express 3.0 x8 or x16 slots, and depending on the mix and match of these, and the use of I/O riser cards, IBM can put six or eight of the Tesla T4 accelerators inside of the IC922 chassis. The machine can drive six T4s at full bandwidth, but has to backstep a bit on a few of the Tesla T4 cards when eight devices are installed, according to Boday. At some point in the future, FPGA and ASIC accelerators will be certified to run in the IC922 system, and we suspect that Xilinx Alveo FPGA cards will be first up. There is no reason why AMD Radeon Instinct cards could not plug into the system, and ditto for a slew of specialized ASICs or even Intel Arria 10, Stratix 10, or Agilex FPGA accelerator cards. It will be interesting to see what IBM does here.
What we want to know is the typical ratio of machine learning training systems to inference systems at large enterprises, and Boday offered us some insight, saying that in the engagements where IBM has been peddling the AC922 systems, the ratio is somewhere between 4 to 5 inference machines for every training machine, and moreover that the average inference machine has two to four Tesla T4-class accelerators and the typical training machine has around four GPUs.
Even though IBM is pushing the IC922 as an inference machine, the competitive analysis it has done is based on containerized geospatial application running atop the OpenShift Kubernetes container environment from its Red Hat division using a MongoDB database. The comparison below is against a Hewlett Packard Enterprise ProLiant machine with roughly equivalent configuration, and Boday says that in general, the IC922 will be less expensive than an HPE ProLiant or Dell PowerEdge system by 15 percent to 20 percent. Take a look:
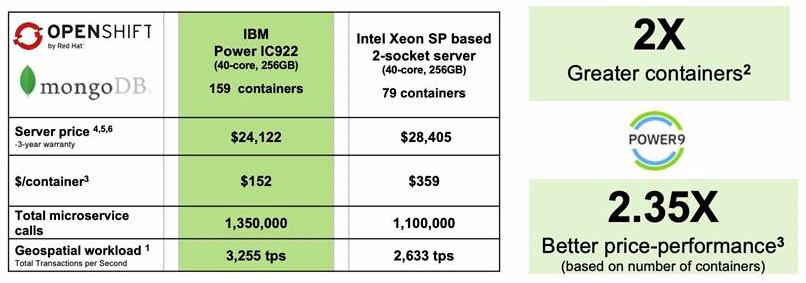
The IC922 in the comparison above has the 20-core Power9 chips running at 2.9 GHz, and in addition to the 256 GB of main memory, the system has two 960 GB flash drives, a two-port 10 Gb/sec Ethernet adapter, plus RHEL 7.6 and OpenShift Container Platform 3.11. With the three year warranty on hardware tossed in, the IBM box costs $24,122. The HPE ProLiant machine had a pair of Skylake 20-core Xeon SP-6148 processors, which clock at 2.4 GHz; this machine had the same storage, networking, and software stack. We don’t know how much credence to lend to the container count IBM is touting – it is interesting – but the microservices calls using Node.js into MongoDB and the transactions per second processed by these containers is what matters. The Power9 system handled 22.7 percent more microservices calls and processed 23.6 percent more transactions, and did so at 15.1 percent lower cost, and that works out to 33.1 percent better bang for the buck.
Now, when these Power9 and Xeon SP machines are configured up for data ingest or inference workloads, they are going to cost a hell of a lot more money, and the difference in the cost of the core processing and relatively small amount of main memory will be dwarfed by the cost of the flash storage or compute accelerators. So you have to remember that, and to fight hard for price breaks here, too, when you are shopping. (Competitive bidding is your friend.) Nvidia does not provide list pricing for the Tesla T4 accelerators, but IBM has a list price of $3,999 for the units. Six of those cost $23,994 and eight cost $31,992. Call it around $50,000 after some discounts for an inference engine fully loaded with Tesla T4 accelerators plus some high speed networking and modest storage. If you load the box up with SAS or SATA flash, it can get pretty pricey. With 24 SATA flash drives at 3.8 TB each, for a total of 91.2 TB of capacity, you are close to $100,000 at list price, and with 24 SAS drives at 3.8 TB, it costs $72,000 just for the storage. While IBM is supporting NVM-Express drives, they are not yet in its price list for the IC922, but presumably these will come at a premium given how much of a performance boost they provide.
So, a loaded up database server based on the IC922 that can push that 1 TB/sec of I/O might cost around $100,000 easily, and the inference box might cost $50,000. We don’t think this is out of whack with what HPE ProLiant or Dell PowerEdge iron configured up might cost – and they are at a memory capacity and bandwidth and an I/O capacity and bandwidth disadvantage because of the fewer memory controllers and slower PCI-Express controllers in the Xeon SP chips.
The IC922 will be generally available on February 7. The machine is supporting Red Hat Enterprise Linux, of course, but not the SUSE Linux or Canonical Linux distributions, which had been supported on prior Power iron.

“At some point in the future, FPGA and ASIC accelerators will be certified to run in the IC922 system, and we suspect that Xilinx Alveo FPGA cards will be first up.”
In the HPC Wire article, they quoted IBM as saying the following : –
‘IBM reports it will soon have a developer board. “One of the first things we’re going to do is enable the marketplace with a Bittware FPGA-based a card, https://www.bittware.com/openpower-capi-developers-kit/. It’ll be available in the near future as well. That allows developers to take advantage of the low latency/high throughput, and then we’ll even have a card for them to start exploring on that as well in the very near future.” ‘
The specific card is the 250-SoC FPGA accelerator. Its plethora of IO options allow for some interesting potential configurations including :-
1) OpenCAPI Direct attached FPGA Acceleration
2) Inline Near NVMe Storage Acceleration, thru OCuLink Cables, to the NVMe SSDs mounted in the Chassis
3) Network & NVMeoF IO through the 2x 100GbE QSFP IO cages
For anyone seriously considering leveraging CXL in their future accelerator architectures, they can get going today with this production ready OpenCAPI platform and then easily slide over whenever a production ready CXL system becomes available.