



If it wasn’t bad enough that Moore’s Law improvements in the density and cost of transistors is slowing. At the same time, the cost of designing chips and of the factories that are used to etch them is also on the rise. Any savings on any of these fronts will be most welcome to keep IT innovation leaping ahead.
One of the promising frontiers of research right now in chip design is using machine learning techniques to actually help with some of the tasks in the design process. We will be discussing this at our upcoming The Next AI Platform event in San Jose on March 10 with Elias Fallon, engineering director at Cadence Design Systems. (You can see the full agenda and register to attend at this link; we hope to see you there.) The use of machine learning in chip design was also one of the topics that Jeff Dean, a senior fellow in the Research Group at Google who has helped invent many of the hyperscaler’s key technologies, talked about in his keynote address at this week’s 2020 International Solid State Circuits Conference in San Francisco.
Google, as it turns out, has more than a passing interest in compute engines, being one of the large consumers of CPUs and GPUs in the world and also the designer of TPUs spanning from the edge to the datacenter for doing both machine learning inference and training. So this is not just an academic exercise for the search engine giant and public cloud contender – particularly if it intends to keep advancing its TPU roadmap and if it decides, like rival Amazon Web Services, to start designing its own custom Arm server chips or decides to do custom Arm chips for its phones and other consumer devices.
With a certain amount of serendipity, some of the work that Google has been doing to run machine learning models across large numbers of different types of compute engines is feeding back into the work that it is doing to automate some of the placement and routing of IP blocks on an ASIC. (It is wonderful when an idea is fractal like that. . . .)
While the pod of TPUv3 systems that Google showed off back in May 2018 can mesh together 1,024 of the tensor processors (which had twice as many cores and about a 15 percent clock speed boost as far as we can tell) to deliver 106 petaflops of aggregate 16-bit half precision multiplication performance (with 32-bit accumulation) using Google’s own – and very clever – bfloat16 data format. Those TPUv3 chips are all cross-coupled using a 32×32 toroidal mesh so they can share data, and each TPUv3 core has its own bank of HBM2 memory. This TPUv3 pod is a huge aggregation of compute, which can do either machine learning training or inference, but it is not necessarily as large as Google needs to build. (We will be talking about Dean’s comments on the future of AI hardware and models in a separate story.)
Suffice it to say, Google is hedging with hybrid architectures that mix CPUs and GPUs – and perhaps someday other accelerators – for reinforcement learning workloads, and hence the research that Dean and his peers at Google have been involved in that are also being brought to bear on ASIC design.
“One of the trends is that models are getting bigger,” explains Dean. “So the entire model doesn’t necessarily fit on a single chip. If you have essentially large models, then model parallelism – dividing the model up across multiple chips – is important, and getting good performance by giving it a bunch of compute devices is non-trivial and it is not obvious how to do that effectively.”
It is not as simple as taking the Message Passing Interface (MPI) that is used to dispatch work on massively parallel supercomputers and hacking it onto a machine learning framework like TensorFlow because of the heterogeneous nature of AI iron. But that might have been an interesting way to spread machine learning training workloads over a lot of compute elements, and some have done this. Google, like other hyperscalers, tends to build its own frameworks and protocols and datastores, informed by other technologies, of course.
Device placement – meaning, putting the right neural network (or portion of the code that embodies it) on the right device at the right time for maximum throughput in the overall application – is particularly important as neural network models get bigger than the memory space and the compute oomph of a single CPU, GPU, or TPU. And the problem is getting worse faster than the frameworks and hardware can keep up. Take a look:

The number of parameters just keeps growing and the number of devices being used in parallel also keeps growing. In fact, getting 128 GPUs or 128 TPUv3 processors (which is how you get the 512 cores in the chart above) to work in concert is quite an accomplishment, and is on par with the best that supercomputers could do back in the era before loosely coupled, massively parallel supercomputers using MPI took over and federated NUMA servers with actual shared memory were the norm in HPC more than two decades ago. As more and more devices are going to be lashed together in some fashion to handle these models, Google has been experimenting with using reinforcement learning (RL), a special subset of machine learning, to figure out where to best run neural network models at any given time as model ensembles are running on a collection of CPUs and GPUs. In this case, an initial policy is set for dispatching neural network models for processing, and the results are then fed back into the model for further adaptation, moving it toward more and more efficient running of those models.
In 2017, Google trained an RL model to do this work (you can see the paper here) and here is what the resulting placement looked like for the encoder and decoder, and the RL model to place the work on the two CPUs and four GPUs in the system under test ended up with 19.3 percent lower runtime for the training runs compared to the manually placed neural networks done by a human expert. Dean added that this RL-based placement of neural network work on the compute engines “does kind of non-intuitive things” to achieve that result, which is what seems to be the case with a lot of machine learning applications that, nonetheless, work as well or better than humans doing the same tasks. The issue is that it can’t take a lot of RL compute oomph to place the work on the devices to run the neural networks that are being trained themselves. In 2018, Google did research to show how to scale computational graphs to over 80,000 operations (nodes), and last year, Google created what it calls a generalized device placement scheme for dataflow graphs with over 50,000 operations (nodes).
“Then we start to think about using this instead of using it to place software computation on different computational devices, we started to think about it for could we use this to do placement and routing in ASIC chip design because the problems, if you squint at them, sort of look similar,” says Dean. “Reinforcement learning works really well for hard problems with clear rules like Chess or Go, and essentially we started asking ourselves: Can we get a reinforcement learning model to successfully play the game of ASIC chip layout?”
There are a couple of challenges to doing this, according to Dean. For one thing, chess and Go both have a single objective, which is to win the game and not lose the game. (They are two sides of the same coin.) With the placement of IP blocks on an ASIC and the routing between them, there is not a simple win or lose and there are many objectives that you care about, such as area, timing, congestion, design rules, and so on. Even more daunting is the fact that the number of potential states that have to be managed by the neural network model for IP block placement is enormous, as this chart below shows:
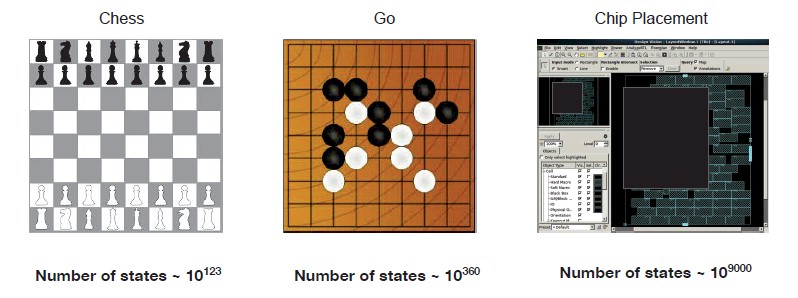
Finally, the true reward function that drives the placement of IP blocks, which runs in EDA tools, takes many hours to run.
“And so we have an architecture – I’m not going to get a lot of detail – but essentially it tries to take a bunch of things that make up a chip design and then try to place them on the wafer,” explains Dean, and he showed off some results of placing IP blocks on a low-powered machine learning accelerator chip (we presume this is the edge TPU that Google has created for its smartphones), with some areas intentionally blurred to keep us from learning the details of that chip. “We have had a team of human experts places this IP block and they had a couple of proxy reward functions that are very cheap for us to evaluate; we evaluated them in two seconds instead of hours, which is really important because reinforcement learning is one where you iterate many times. So we have a machine learning-based placement system, and what you can see is that it sort of spreads out the logic a bit more rather than having it in quite such a rectangular area, and that has enabled it to get improvements in both congestion and wire length. And we have got comparable or superhuman results on all the different IP blocks that we have tried so far.”
Note: I am not sure we want to call AI algorithms superhuman. At least if you don’t want to have it banned.
Anyway, here is how that low-powered machine learning accelerator for the RL network versus people doing the IP block placement:

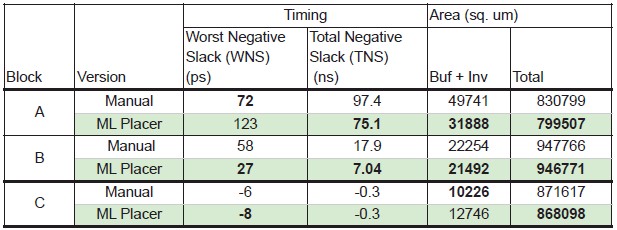
And here is a table that shows the difference between doing the placing and routing by hand and automating it with machine learning:
And finally, here is how the IP block on the TPU chip was handled by the RL network compared to the humans:

Look at how organic these AI-created IP blocks look compared to the Cartesian ones designed by humans. Fascinating.
Now having done this, Google then asked this question: Can we train a general agent that is quickly effective at placing a new design that it has never seen before? Which is precisely the point when you are making a new chip. So Google tested this generalized model against four different IP blocks from the TPU architecture and then also on the “Ariane” RISC-V processor architecture. This data pits people working with commercial tools and various levels tuning on the model:
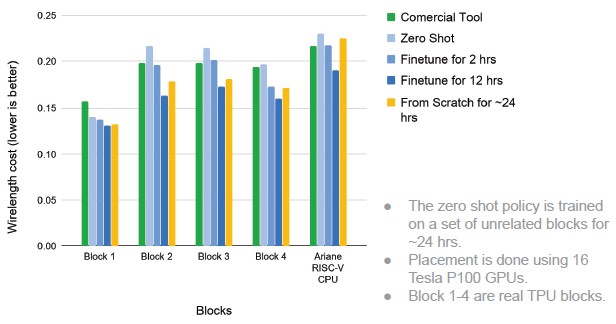
And here is some more data on the placement and routing done on the Ariane RISC-V chips:
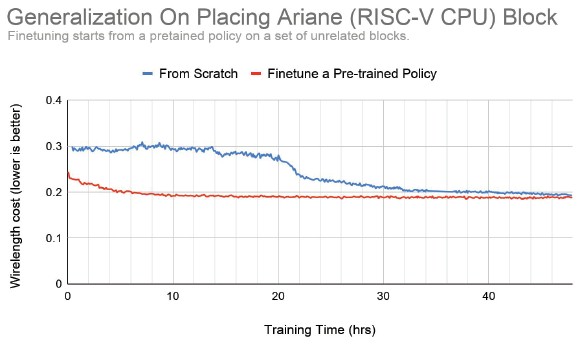
“You can see that experience on other designs actually improves the results significantly, so essentially in twelve hours you can get the darkest blue bar,” Dean says, referring to the first chart above, and then continues with the second chart above. “And this graph showing the wireline costs where we see if you train from scratch, it actually takes the system a little while before it sort of makes some breakthrough insight and was able to significantly drop the wiring cost, where the pretrained policy has some general intuitions about chip design from seeing other designs and people that get to that level very quickly.”
Just like we do ensembles of simulations to do better weather forecasting, Dean says that this kind of AI-juiced placement and routing of IP block sin chip design could be used to quickly generate many different layouts, with different tradeoffs. And in the event that some feature needs to be added, the AI-juiced chip design game could re-do a layout quickly, not taking months to do it.
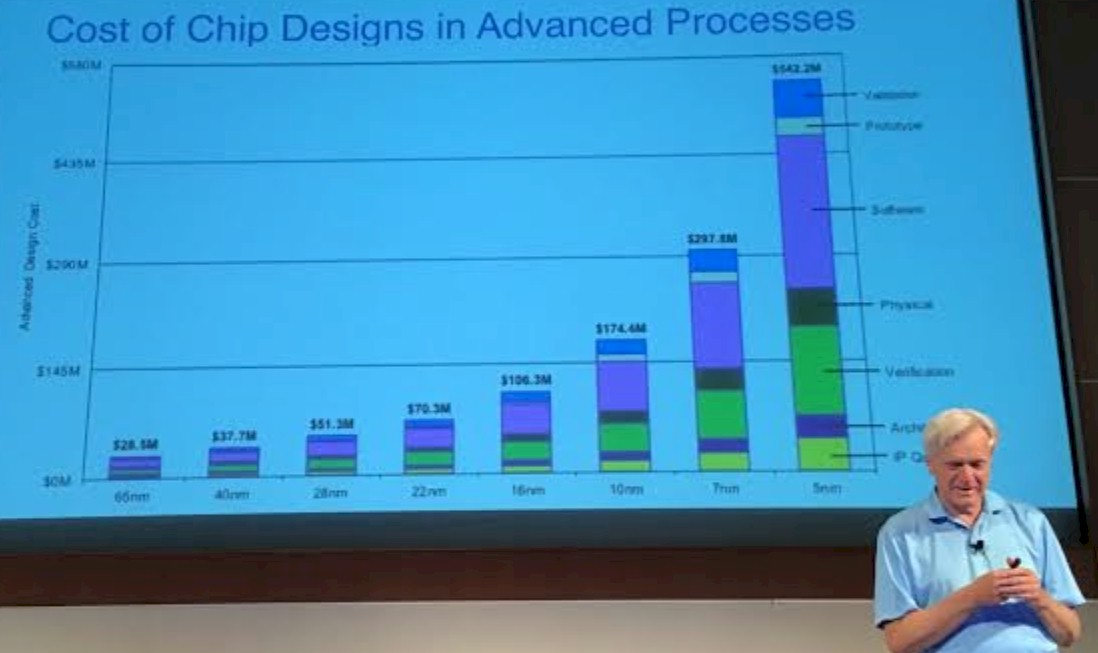
And most importantly, this automated design assistance could radically drop the cost of creating new chips. These costs are going up exponentially, and data we have seen (thanks to IT industry luminary and Arista Networks chairman and chief technology officer Andy Bechtolsheim), an advanced chip design using 16 nanometer processes cost an average of $106.3 million, shifting to 10 nanometers pushed that up to $174.4 million, and the move to 7 nanometers costs $297.8 million, with projections for 5 nanometer chips to be on the order of $542.2 million. Nearly half of that cost has been – and continues to be – for software. So we know where to target some of those costs, and machine learning can help.
The question is will the chip design software makers embed AI and foster an explosion in chip designs that can be truly called Cambrian, and then make it up in volume like the rest of us have to do in our work? It will be interesting to see what happens here, and how research like that being done by Google will help.