

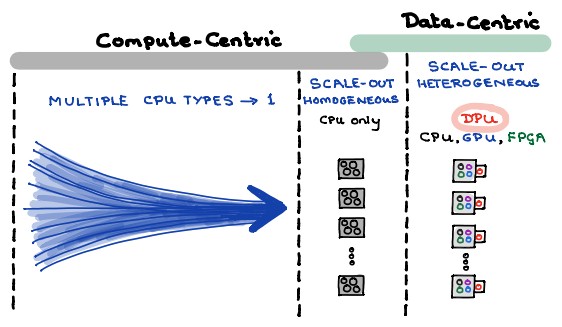
As we all know well, the various elements computer architecture swing on their own pendulums, with consolidated being at the center and distributed being at the opposite ends of the arc. All things being equal, we would all just as soon have one giant central processor that can do everything and as few distributed intelligent elements as possible in a system. When jobs outgrow the size of a single system or that system becomes to expensive to support ever-growing workloads, that is when we shift to an offload and distributed model for both compute and storage.
We would argue that it is in fact a rare condition in system architecture when everything can be consolidated fully down to a central system. Even with the System/360 that debuted from IBM in 1964, there was a thing called a main frame where the central processing unit was housed and, because of the limited capacity of the memory, storage, and networking devices attached to this main frame, there was a certain amount of intelligence embedded into all of these subsystems. To a certain extent, the rise of RISC/Unix machines in the late 1980s and early 1990s represented the apex of consolidated systems, with relatively dumb controllers, and the early days of the X86 server advancing into the datacenter also were driven by largely self-contained, consolidated systems. The workloads expanded, however, and software started running across clusters of machines as to dot-com and HPC booms both got going, and the cost of running workloads fell substantially and the scale of workloads rose even faster, yielding a renaissance in distributed computing that, frankly, we are still only really beginning to fully appreciate.
In more recent years, as the CPUs in systems were increasingly burdened by network and storage workloads, intelligent controllers have re-emerged as SmartNICs and now data processing units, or DPUs. This is a new – and much needed – twist on a very old idea, and ahead of the launch of the architecture behind its first products at the Hot Chips 32 conference underway this week, we sat down for a long chat with Pradeep Sindhu, co-founder and chief executive officer at Fungible, who believes that Fungible, not the myriad existing and startup makers of SmartNICs, can lay claim to creating the first real DPU, which it invented in concept in 2015 and is bringing to market shortly.
Sindhu has a very long and deep career in the computer industry, and when he talks, you listen, and interesting, he doesn’t bring PowerPoints to walk through. He grabs a piece of paper and draws them out in real time, with a pen, and if you are lucky, he gives them to you when he is done. We were lucky.
Here is the image Sindhu drew to start the company:
Sindhu got his B.Tech. in electrical engineering from the Indian Institute of Technology in 1974, got his masters of science in electrical engineering from the University of Hawaii in 1976, and his PhD in computer science from Carnegie Mellon University in 1982, where he studied under Bob Sproull, who had worked at the famous Xerox Palo Alto Research Center before moving to Carnegie Mellon. And thus, Sindhu got his foot in the door at Xerox PARC and worked there for eleven years on the tools for chip design and high-speed interconnects for shared memory systems; he then worked at Sun Microsystems on microprocessor designs. In 1996, Sindhu saw all the money that Cisco was going to be making in the router business thanks to the commercialization of the Internet, and he and Dennis Ferguson and Bjorn Liencres founded Juniper Networks, Cisco’s biggest rival for decades in both routing and then switching in the datacenter. Juniper went public in 1999, and the founders and their investors all got fabulously wealthy from creating a very successful networking business.
Sindhu remained chief technology officer at Juniper until February 2017, when the merchant silicon providers have largely wrested control of networking from the proprietary ASIC makers like Cisco and Juniper and when he decided to take on the I/O and storage bottlenecks in modern systems and co-founded Fungible with Bertrand Serlet, who also worked at Xerox PARC (on software, not hardware) and then famously worked at NeXT with Steve Jobs after he left Apple and then moved over to Apple to work on various bits of software, including steering the Mac OS X release. Serlet left Apple in 2011, and founded a startup called Upthere, which was sold to Western Digital in 2017, which was after Sindhu and Serlet had started Fungible. Jai Menon, who was chief technology officer at both IBM and Dell, joined the two as chief scientist last September.
Fungible has been pretty tight-lipped about what it is up to, but not to Mayfield, Walden International, Battery Ventures, Norwest Venture Partners, SoftBank, and Redline, who have collectively kicked in $310.9 million into Fungible in three rounds of funding as the company prepares to demonstrate, with its products, the difference between a SmartNIC and a DPU. Sindhu wanted to make sure that the message about what constitutes a DPU – and what does not – was clear before the product preview at Hot Chips, which is why he hopped on the Zoom with us to elaborate. Get some coffee, and enjoy.
Timothy Prickett Morgan: Pradeep, just dive in. I have been waiting a long time for this moment.
Pradeep Sindhu: Let me clarify a little bit about the DPU, particularly since the discussions you have had with Jensen Huang of Nvidia recently. Who by the way is a friend of mine – I’ve known him for forty five years, all the way back when he was at LSI Logic and I was at Sun Microsystems. And I think we have mutual respect for each other, and I’ve also discussed this topic with him – actually nearly a year ago, and at which point he was not a believer but I think that he has seen the light since then.
We formed this company in 2015 and the vision of the company was that there is a new kind of microprocessor that is needed. And while we coined the term DPU in 2017. As you know, labels are easy to give. But the doing the groundwork and building the technology that is behind the label is a little bit more challenging. And if there’s one thing I want to do today it is to give you a chapter and verse understanding of the technology behind the concept of the DPU so that you could easily differentiate the DPU from other pretenders – and they really are pretenders. We’re very happy to have somebody to support the vision, somebody as significant a company as Nvidia and a luminary like Jensen . But I’ll be darned if I’ll have somebody steal my vision.
So let me first give you a picture, which as we know speaks at least 1,000 words.
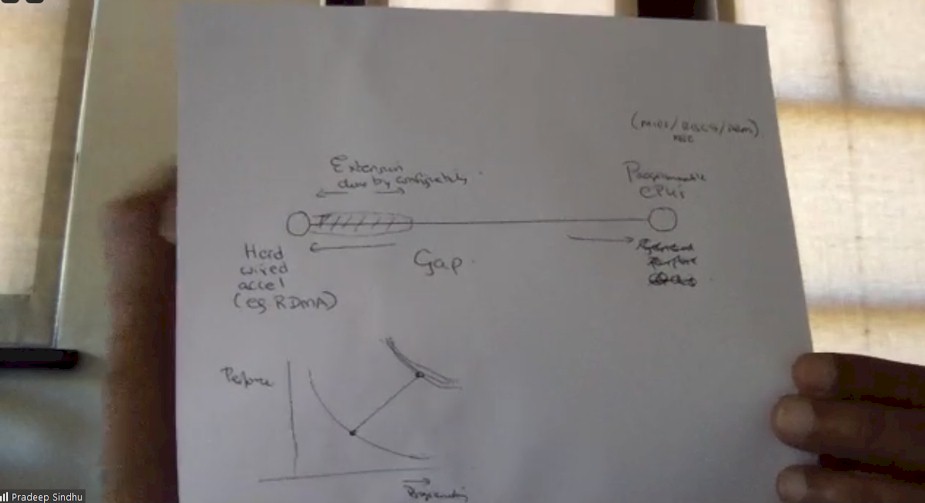
This picture basically shows performance on the vertical axis and programmability on the horizontal axis. And you can see that there is an inverse relationship between them with any given technology and particularly with any given architecture.
This inverse relationship is a long, historic relationship, and there are fundamental reasons for this. We probably don’t want to get into why. But please trust me that there is a basic fundamental relationship between the performance of an engine and its programmability and we will define each of these terms very quickly. The only way to break this tradeoff is either to you is much more advanced technology or to use advanced architecture.
TPM: I respect a man who draws his own pictures, by the way.
Pradeep Sindhu: That’s how I understand things.
TPM: I am the same way.
Pradeep Sindhu: So you notice that there an arrow going from this lower tradeoff to a higher tradeoff? That’s what the DPU basically did in one picture. Very, very clean summary.
We have made architectural innovations that allow you to make a different tradeoff than general purpose CPUs or hardwired engines do for a limited domain. This is very, very important. You cannot do this for all computations. But you can – if you confine yourself to merely data centric computations, which we will also define carefully – you can work wonders that are roughly a 20X price/performance improvement by architectural means, not technology means. By the way, Fungible has not yet used the most advanced lithography available, which we can do and we will do. And then you are going to see another factor of 2X to 3X over this improvement.
TPM: What process are you using for the initial DPUs that Fungible has created?
Pradeep Sindhu: It is 16 nanometer FinFET going to 7 nanometers next gen. So this delta that we have gotten from here to here is roughly a 20X price/performance improvement over general purpose CPUs.
Now let me now go through the other part of the picture, which is at the top now, the spectrum.
What I’m showing here on one side is a completely hardwired implementation. This bubble here. You know, this bubble is a completely hardwired data path will be very high performance. Nobody will be able to compete with it. But it will be very limited to doing exactly and only exactly what you’re designing it to do. Very inflexible, brittle. On the other extreme, as you have programmable CPUs: For example, MIPS, Arm, RISC-V, X86, what have you. Now these CPUs I showed as a data point, a single point, but any general purpose CPU can perform any computation. They should be clear because this was discovered back in 1946 by Alan Turing when he and John von Neumann defined the notion of general purpose computing. So it doesn’t take much to make something be fully general. However, the performance you can get with these general purpose CPUs is quite pathetic for data centric computations.
Now in the industry, there is a huge gap between this bubble and this hardwired implementation. Now you see this little flare over here data. That’s an attempt by clever people to extend the pipeline hardwired approach through what I call configurability. I can configure parameters in the pipeline to make it a little bit more flexible. Now, on this subject, I speak as an expert. And why do I speak as an expert? I have developed at Juniper some hundred plus different pieces of silicon with the idea of configurability and reaching out towards programmability as much as I could.

 And we are not talking about P4 here. P4 is a latecomer to this game, OK? It’s putting varnish on some technology that already exists. It’s a language. It’s a configuration language, not a programing language. P4 is not a programing language. So what I distinguish between configurability and programmability is that with programmability, I can specify in exquisite detail what it is that I want to do and how it is I want to do it with, you know, the tiniest forceps I can specify what to do. The what I configurability provides you again in a limited domain and to a limited extent is some flexibility. And that flexibility – with P4 or without P4 – is rather limited. Let’s be clear about that. And it is especially limited for data centric calculations because these calculations require what is called stateful processing.
And we are not talking about P4 here. P4 is a latecomer to this game, OK? It’s putting varnish on some technology that already exists. It’s a language. It’s a configuration language, not a programing language. P4 is not a programing language. So what I distinguish between configurability and programmability is that with programmability, I can specify in exquisite detail what it is that I want to do and how it is I want to do it with, you know, the tiniest forceps I can specify what to do. The what I configurability provides you again in a limited domain and to a limited extent is some flexibility. And that flexibility – with P4 or without P4 – is rather limited. Let’s be clear about that. And it is especially limited for data centric calculations because these calculations require what is called stateful processing.
Now, I’ve used the term data centric many, many times. Let me now define it.
TPM: I am all ears. If you have seen a picture of me, you know that is true.
Pradeep Sindhu: Data centric computations are a new class, but very, very important class of computations for datacenters. These data centric computations became came to the fore somewhere around 2000 or so. And since then, they’ve been becoming increasingly important. They have four attributes and I’ll label each one of them very, very quickly.
First of all, for a data centric workload, all of the workload comes to you in the form of packets on the wire, and whether these are Ethernet packets, IP packets, or packets on PCI bus is irrelevant. They’re packets on the wire.
The second thing is that these packets belong to many, many, many different contexts, which are independent of each other. So there’s a lot of different computations which are going on concurrently. And this is the second essential aspect of data centric computing, which is that I am doing not one computation, I’m doing thousands of computations concurrently and I require a very high throughput. So and you can imagine that packet switching, which is fundamental and there is a mixing intermixing of the packets of many, many, many different plans on the wire. And so when that work load arrives at an engine which is trying to deal with this workload, you’re going to have a lot of multiplexing going on. So that’s the second essential aspect, which is many contexts.
The third thing is that the computation is stateful. Now this one is very much misunderstood. So what does stateful computation mean? And by the way, there are people who have been using the term stateful without really understanding it. And there is a startup that begins with the P that has been doing this and it seems to me clearly that they don’t quite understand what stateful means.
TPM: I suspect those people from the former Cisco would argue with you, but do continue.
Pradeep Sindhu: What stateful really means is the following: That in order to complete the computation, I have to read some state and then I have to modify it – do some computation – and then write it back. So there’s a read, modify, write going on. And when I have multiple contexts and I had many, many packets from the same context coming, this makes the computation very, very hard, about 4X to 10X harder than non-stateful computations.

Just to give you a very clear idea, routers and switches do not do stateful computations because there’s no updating of the state going on. Now, there’s one other thing about statefulness, which is that normally when you have a stateful computation, the amount of state is large enough that it doesn’t actually fit on a chip. Now, this is a technological statement which I’m making today. You know, 50 years from now, maybe this may not be true because I can put a ton of state inside the chip. So the fact that I cannot store the state on chip and I have to go outside, makes the problem even more difficult.
Those first three attributes of statefulness of our data-centric computations. And all of these are important. And all of these need to be there. The last one is that the ratio of packets per second to instructions per second is medium to high.
Now, what instructions am I talking about? I’m talking about when you want to come up with metrics, you have to be precise and you have to have some units of measure without units that may say you can measure anything. So a lot of people talk with waving their hands in the air. We don’t. So our unit of measure is standard RISC instructions. It’s a well understood concept, and it is an instruction that you can do it about 300 nonseconds to 500 nanoseconds. And it’s well established that all microprocessors are built using a small subset of RISC instructions – you know, add, subtract, load, store, etc. So those kinds of instructions are a convenient way to measure the degree of difficulty. Also, we need to consider the computational task, how computationally heavy is it? So what I’m saying is that the packet per second rate divided by the instructions per second rate is medium to high. In other words, the number of instructions per packet is relatively small. Are those four points crystal clear?
TPM: Like the quartz chunk sitting on my desk, yes.
Pradeep Sindhu: We believe that roughly one third or more of the energy spent inside a datacenter today is spent on data-centric computations. And these computations today are done mostly by general purpose CPUs. And you can imagine that if one third of the power consumption in a datacenter is spent on a device which can be made 20X more efficient, that means the DPU can move the needle a lot.
TPM: I am with you.
Pradeep Sindhu: It doesn’t stop there because today what the DPU does in addition to performing data-centric computations very well, there is the second piece which people have not discovered yet, and that is the fabric. And I will mark my words that when we come out of stealth, everybody is going to have a fabric. Why? Why do I say this? Because I’ve been to this movie a few times. In 2006, when I announced at Juniper that we were working on something called QFabric, I explained the seven attributes of the fabric. And by the way, we had occasion over the last decade to improve that technology by leaps and bounds. Within a few months, everybody and their grandmother had a fabric – and whether they actually had it or not, they labelled it one.
This is what I meant when I started by saying it is quite easy to put a label on things. It doesn’t take effort, but to develop the technology takes extreme effort and extreme concentration and focus. Now, because the term fabric has been fully bastardized by the industry, we choose to call our technology True Fabric.
TPM: I hope you left the “e” in True. Marketers sometimes do weird things to names.
Pradeep Sindhu: Of course we did. I am a stickler for English spelling. True Fabric is a fundamental advancement to the science and technology of networking in the datacenter.
So why do I say this? When you have a datacenter at small, medium, or large scale, if you wish to write your applications in a scale out manner, which is the only sensible way forward, a fundamental assumption you make is that whatever application you build is built as a set of microservices that are interacting with each other over the network. Now when you do this, you can imagine that the amount of communication over the network, in this case the local area datacenter network, becomes very high.
TPM: It’s crazy high and it allows tail latencies to do nutsy things to applications.
Pradeep Sindhu: That’s exactly right.
TPM: And it is hard to predict the performance of anything with this kind of architecture because of this.
Pradeep Sindhu: Again, correct. It is hard to predict the performance. OK, so now we have many, many, many attempts over the last 45 years by people to solve this problem. There have been over two dozen PhD theses addressing this topic. The problem is as yet unsolved until Funglible came on the scene.
TPM: No, that’s not true. You just put deep buffers on your switch and pay Broadcom a lot more money and pray that you don’t drop packets on the floor. That’s how you do. You do realize I’m being very sarcastic here. . . .
Pradeep Sindhu: Yes, of course. Incredibly deep buffers don’t help.
TPM: It just increases the latency, one way or the other, most of the time but not always.
Pradeep Sindhu: So let’s just review very quickly the work that has been done by the industry over the last 45 years. TCP came a long, long time ago, but TCP was trying to solve a very, very hard problem, which is the problem of communicating packets over the wide area networks that were literally chewing gum and baling wire. And the only way to detect whether I had a good connection or not was through packet drops. But TCP did remarkable things, and the rest is history.
Well, the problem with TCP is that it has five things that are built, and I can name them very quickly. It’s network congestion avoidance. There is error recovery. There is a packets to bytes and bytes to packets and there is application level. So control being the top four and one is being port multiplexing. So five different things were put into TCP for good reasons because we did not know better. Well, the other attempts to solve the problem – and TCP solved this problem, end to end. In other words, I had a TCP stack running at the two ends and it didn’t matter what kind of a network I had in-between.
The three other attempts to solve this problem – Fibre Channel, then InfiniBand and then finally RoCE – all three of these technologies use the same technique, which is they do hop by hop congestion control. Hop by hop congestion control is to be contrasted with end to end congestion and error control, and if you go back and read some of the first papers on IP, it was clearly explained that things like congestion control and error control are best handled at the end. They cannot be solved fundamentally in the middle of the network. And this was called the end-to-end principle. And principles are true eternally.
So the end to end principle still applies. It hasn’t vanished. And so what we did at Fungible is build on top of standard Ethernet and standard IP, not TCP. We have invented a protocol that we call FCP, and that protocol, it stands for Fabric Control Protocol or alternatively Fungible Control Protocol. And what this does is it implements the essence of TCP essentially in hardware. And the essence of TCP is how do I communicate from one side to the other with no packet loss and with no congestion and with error recovery but where are the units being moved back and forth are not bytestreams with their packets. And this is much more fundamental than bytestreams because you can build bytestreams out of packets. But doing the reverse is very hard – or it’s hard in the sense that it requires much more computation to parse – you have to construct on one end and parse on the other.
So FCP is revolutionary because it finally allows you to run a datacenter network at large scale. And by large scale, I mean up to four thousand to six thousand racks, not ten racks, not a hundred racks, not a thousand of racks, with each rack connected at 3.2 Tb/sec or more. What FCP is able to do is to connect together these things in such a way that I can get full cross-sectional bandwidth, meaning 85 percent to 90 percent utilization of the network while maintaining low latency and low jitter.
So the thing that you had pointed out in the beginning, which is that you cannot disaggregate resources easily and in high performance with the technologies available today. We have solved that problem, once and for all. And so this is a fundamental groundbreaking contribution to the industry and we are very proud of having done that.
Now, I also believe that by definition, a DPU needs to incorporate these two things, which is a protocol like a FCP and the ability to handle datacenter computations much, much faster inside one device at the endpoint closest to a server and preferably inside the server.
So, in my mind, the DPU has three aspects. Number one is data-centric computations. Number two is something like FCP. And number three is full programmability. These are the three legs of the stool. And I would submit to you that nobody else even comes close to having a DPU. This is why it frustrates me greatly when Nvidia stands up in front of the world and says that they have in, Mellanox BlueField, a DPU.
What Nvidia has is a piece of RDMA hardware, actually RoCE hardware, and then a small number of Arm cores that are ships in the night – and there is a gap in the middle that is unfilled. So what happens with this type of chip is that as long as you are doing RDMA — and we just talked about the fact that RDMA doesn’t work for scales greater than ten or fifteen racks, and hyperscaler are after hyperscaler has told us that they are frustrated with RoCE, please help us. So if as long as you’re sending RoCE v2 packets, you can do that at some scale and at some performance, but still with very high jitter. The moment you try to do anything else, you are in this line where you’re having your general purpose CPUs perform tasks very inefficiently.
The only company that has actually made a smooth transition all the way from here to here is Fungible. And we’ve done this by making the CPUs – and we have not invented a new instruction set by the way, but what we have done is have the CPUs interact intimately with a carefully chosen set of accelerators inside the chip and the accelerators inside the chip are invoked in the same way that procedure calls might be invoked from one CPU to another CPU. With the same elegance, the same simplicity, and the same generality.
If you talk to any computer scientist, he or she will tell you that the most important invention in programing was the procedure call. What we have done is not only do we use procedure calls inside a DPU, we have generalized the concept of procedure calls to what is called closures. And a closure is different from a procedure call in that in a procedure call, you do a call and the procedure call does its thing and returns. Well, in a closure, you can call a procedure and that procedure can forward the call to another procedure and so on. And you can see how that datapath processing can be done extremely efficiently by making use of closures.
Now, how many people have talked about these things? I can tell you the day we come out of stealth and talk about the thing, everybody is going to be jumping up and down saying we have this, we have this, we have this too. But it’s not going to be true. Fungible is in putting a stake in the ground and is the first one that invented the DPU. We named it three years ago. We started work on it four and a half years ago. We are now bringing it to market in two devices.

Intel Unrolls DPU Roadmap, With A Two Year Cadence
There is a fundamental disconnect between the cadence that chip makers want for their devices and what the hyperscalers and cloud builders would prefer. And it looks like they are working together to split the difference and accept a two year cadence for the architectural upgrade cycle for all key …

One Way To Bring DPU Acceleration To Supercomputing
That is not a typo in the title. We did not mean to say GPU in title above, or even make a joke that in hybrid CPU_GPU systems, the CPU is more of a serial processing accelerator with a giant slow DDR4 cache for GPUs in hybrid supercomputers these days …

The Steady Hand Guiding AMD’s “Prudently Expanding” Datacenter Business
The old AMD – the one before Lisa Su took over – was often brilliant with its instruction set architecture and CPU designs, but sometimes perplexingly careless with its design choices and chip roadmaps. And so it had a bit of a boom-bust cycle in its epic battles with archrival …
“and the early days of the X86 server advancing into the datacenter also were driven by largely self-contained, consolidated systems. ”
Which is the 1990’s or 2000’s? Because server class x86’s in the 1990’s had as much offload as mainframe channel controllers. Things like the NCR scripts SCSI controllers were OS programmable microcontrollers, to later fiber channel controllers complete with MIPS CPUs onboard. And the remote side wern’t just single standalone disk drives with LBA abstractions and error correction, but RAID arrays that eventually encompassed a laundry list of features, like thin provisioning, encryption, compression, deduplication, replication, snapshots, etc. Many of which included not just virtual block layer abstractions but network filesystems frequently with even more advanced features. HSM’s for example.
The straight IP networking side isn’t as clear as the latency of NIC’s with TSO/TOE, etc has swung them in and out of favor, but things like checksum offload have been included for a couple of decades now, and much of the more advanced functionality has also been encapsulated in appliances, be it routing, firewall, intrusion prevention, etc.
So, you should be clear about “datacenter” vs “hyperscaler” where the latter thinks it’s easier to scale problems by disaggregating the above functions and the way they went about it included very heavyweight software layers running on the dedicated compute hardware. And that worked for them until they realized that the overheads of running all this on expensive “datacenter grade” cores from intel rather than custom offload engines in dedicated appliances weren’t all the inexpensive. So, now it’s being offloaded to cheap arm cores, which will last just as long as it takes to convert their datacenters to cheaper CPU cores and toss a tighter coupled chiplet with some “little” cores back into mix or realize that trying to cram every single function into a general purpose chassis rather than having some of them built for specific purposes is a better plan.
Sorry there are patents from 2023 that were shown to Microsoft that became the Series X Xbox that completely describe the DPU long before Fungible