

There is a new challenge workload on the horizon, one where few can afford to compete. But for those who can, it will spark a rethink in what is possible from even the most powerful traditional supercomputers.
It might sound odd that it can be collected under the banner of language modeling since that invokes speech and text analysis and generation. But emerging workloads and research show how far this is from traditional natural language processing. Over the next several years, language models will likely become far more general purpose, encompassing an unimaginable range of problem types.
Being able to have a world described through language and rendered as an image or video, or even asking text-based questions about the world with answers based on a system’s understanding of our nuanced reality sounds like science fiction. But we are inching toward this future. The problem with making this a practical reality, however, is that the economics of a near infinitely scalable model are incredibly prohibitive.
Bryan Catanzaro, VP of Applied Deep Learning Research at NVIDIA put this into staggering context when he told us that he thinks it is entirely possible that in five years a company could invest one billion dollars in compute time to train a single language model. Think about that for a moment.
“With models like GPT-3 we are starting to see models that can go beyond, that can actually become more general purpose tools for solving real-world problems. It’s a step toward a more general form of artificial intelligence and that justifies the investment in training these enormous language models on clusters like Selene.” Recall that #5 ranked Selene is NVIDIA’s own AI supercomputer used for experimental and production operations. This includes everything from dense model experimentation like Catanzaro’s team does to providing the backbone for initiatives at the graphics giant like those wrapped into the host of Maxine services.
“We’re going to see these models push the economic limit. Technology has always been constrained by economics, even Moore’s Law is an economic law as much as a physics law. These models are so adaptable and flexible and their capabilities have been so correlated with scale we may actually see them providing several billions of dollars worth of value from a single model, so in the next five years, spending a billion in compute to train those could make sense,” Catanzaro says.
These services have been valuable for NVIDIA, he says, but when he looks ahead to areas first in entertainment and gaming where text can be used to feed into image or video synthesis—to create worlds from description—those future investments seem more plausible. Where those fit into large enterprise is still up in the air but Catanzaro says with language models as a general purpose platform to develop new problems and applications, smart people at companies globally will find ways to make up the billion-plus investments.
“Language modeling is one of the most expensive done in ML now,” Catanzaro explains. “Vast language models need enormous amounts of compute with GPT-3 for example and its zero-shot learning approach where we ask the language model to solve a new problem that’s never been seen and it often comes up with the right answer without being taught the task simply because the language model is powerful enough to understand the question and provide an answer that makes sense in context.”
Chances are, as you read this, you keep going back to that whole billion dollar idea. That may sound a little crazy, but it is not hard to get to $1 billion, either on premises and particularly on the public cloud.
This is some approximate math but it shows, for companies that see the value and want to sign up for a long-term commitment to a continuously training/retraining language modeling adventure, getting to a billion dollars doesn’t take long.
The initial configuration of Selene had 280 DGX-A100 systems, which cost $199,000 each approximately. If networking is around 15 percent of the total cost of the system and proper storage is around 20 percent, at list price the machine would cost on the order of $85 million. After volume discounts or by going with a third party making a similar server using HGX-A100 motherboards and their own compute engines, maybe you could get the price down to $75 million.
Over a three-year period, that works out to something like $2,852 per hour for the entire Selene system, not including power, cooling, operations, and other costs. A cloud builder with lots of volume might be able to get the components for a little less. The p4d instances at Amazon Web Services cost $32.77 per hour for a system with two processors and eight A100s. And for an equal amount of capacity as Selene, you are talking $9,176 per hour for 280 instances, and over three years that is $241.3 million on demand; if you do three year reserved instances the price to rent a Selene-like system on AWS for three years comes down to – you guessed it – $85.2 million.
To get to $1 billion, you are going to need to spend for 12X the capacity of Selene. So maybe that is not so easy, after all, or maybe it will be because these models are going to be truly enormous.
(Editor’s note: Nvidia says that Selene has been recently upgraded to 560 DGX-A100 systems, which doubles its size and cost, and means you only need 6X more compute — something we did not know when we wrote this story. The idea holds just the same.)
The math puts this in perspective, even if the ROI and real-world use cases that can make this a suitable investment are still a bit nebulous.
All of the economic scale means figuring out how to keep scaling the model itself is critical but Catanzaro and team have shown some impressive results over time. Below see the scaling results from current GPT-3 models on Selene. Notice the jump from 8 billion parameters on the original Megatron model from over a year ago to 175 billion parameters (the size of GPT-3) and the relative performance. The team went from 200 GPUs to 3,000 A100 GPUs to train a single model with sustained 400 petaflops (at FP16, not the double-precision we’re used to).
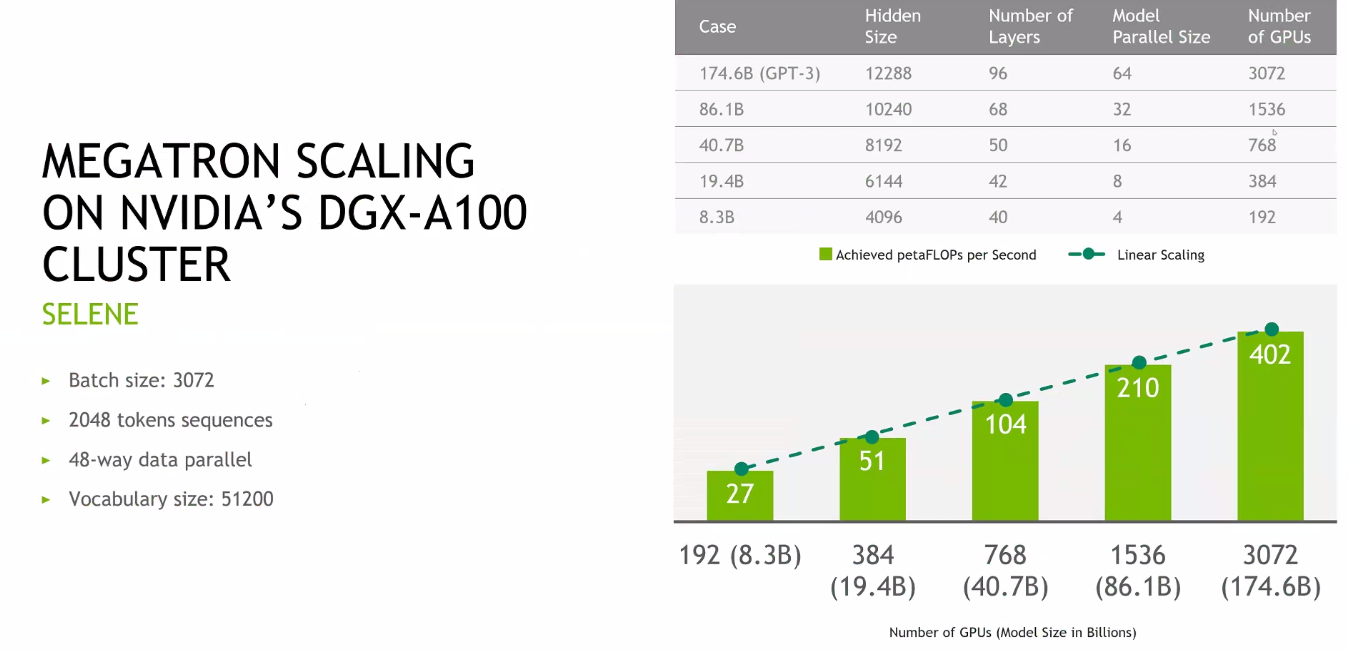
But if companies are ever going to invest a billion in compute time to use these models what challenges are on the roadmap in terms of scalability of the models?
Looking at Catanzaro and team’s evolving work shows where things break and what continues to work as they keep scaling. Much of the footwork has been on the software size exploring different ways to handle model parallelism. The starting point is data parallelism, which is the “easiest” but is limited from an algorithmic perspective because the bigger the batch, the more time is spent optimizing, eventually leading to diminishing returns. Still, to get their results they pushed data parallelism to the upper limit before looking at other methods, including “tensor parallelism” to get maximum GPU utilization and pipeline parallelism, something already well understood in HPC.
Tensor scaling is key to the linear scaling shown above. In this case, each layer of the neural network is split into pieces without any changes to semantics of the computation; it’s just direct parallelization. There are limits to how tiny the slices to be without incurring heavy communication overhead. Pipeline parallelism, the other key to linear scaling of these models across the 2,240 A100 GPUs (and 280 DGX machines) benefits from the structure of neural networks with multiple layers that are identical from a computational perspective. The team can chop up these layers and define different layers to different processors. This is effective but semantics matter—unlike with tensor parallelism they change with pipelining and even with cleverness in minimizing the bubbles that come during pipeline filling and draining it has its limits as well. Ultimately, it’s pushing all of these ways to address model parallelism to their max before the law of diminishing returns kicks in, a fine balance, Catanzaro says.
On the hardware side, the advantages of the GPU on these problems are well known but it’s the interconnect and network architecture that delivers the linear scaling Catanzaro cites. The Selene system is basically 280 DGX A100 machines joined externally with Mellanox Infiniband but in each node is the all-important NVSwitch. “The thing about NVSwitch is that it has all-to-all communication abilities so the software has total flexibility about how we’ll perform model parallelism, both tensor and pipeline. There are tradeoffs we can make that have different impacts on the interconnect, some more favorable for compute (helping us get max utilization out of the GPUs) but others involve increasing demands on the interconnect,” Catanzaro explains.
The models need all-to-all connectivity but as one might imagine, the communication patterns are deeply complex compared to a more traditional nearest-neighbor mesh architecture, which is needed on systems that don’t have NVSwitch. Using that, he says they can explore far more combinations of model parallelism to increase compute throughput significantly.
It’s true that all of these capabilities are available on the cloud, although there are some hits in terms of getting that model out (for instance, Azure has NVSwitch). What will be most interesting over time is how many massive-scale system sales this could lead to among the majors. Although the ones we can think about–the only ones who might do this–own their cloud anyway.
If we move some of these insights about work being done to continue the linear scalability of these models back to the economic conversation, that billion dollar investment figure might not be as wild as it sounds on the surface. If five years of continued scalability of the model, even if not perfectly linear, means increasing complexity of problems that can be addressed, it’s not inconceivable to think of what it would take to build a “super” Selene—and getting to a billion dollars in hardware alone isn’t as inconceivable as it sounds.

You guys are on fucking fire rn – keep up the good work
There is one major flaw in this idea, because the larger the model the more data you need to feed into it. Eventually it is not going to be compute the bottleneck but actually getting and managing all the data you’re going to process, store, potentially filter and feeding through to the models for training.
The future of AI is self-learning, this requires limited data.
A billion $ in hardware is not so extreme. The latest exascale HPC’s for the DOE are coming at over $500 million and they’re coming this year and next. And I wonder if these projected costs include power because some of these are consuming 40MWH.
I’m quite sure that sensitive customers only announce significant scale supplies when there’s a political or significant economic objective met with doing so. My longest job in what would be called a HFT shop for nearssf approximation these days, but was doing much the similar thing since the early nineties, bought a bunch of VARs to avoid the attention disproportionate to optical scale supply deals attract. I got that job due to a fluke meeting with the sales director of the largest regional VAR of the time at the tailoring workshop of a friend – this VAR had been turning away my future employers business because they didn’t satisfy the VARs strict minimum 200 headcount threshold to be worth the attention. Single digit guys and my new home for the next 20 years opened their account with a order that moved that resellers 10Q needle.