
Everybody wants to build a platform, hence the name of this publication. When it comes to AI, some organizations want to cobble together their own platform, either from homegrown software or using as much open source software and commodity hardware as possible. For every AI platform buyer, there is an AI platform vendor, and it is no secret that while Nvidia wants to supply components to the hyperscalers and public clouds as well as the OEMs and ODMs, who are all building AI platforms to peddle, Nvidia also wants to be an AI platform provider in its own right.
It might as well, because it has had to build or enhance the AI frameworks that underpin its own business and it had to build the distributed systems that its own researchers and software developers use to advance the state of the art. Once that happened, Nvidia became a system seller in its own right and now it is circling back around again, building out the control planes for training and inference systems.
Ahead of the Mobile World Congress 2021 and International Supercomputing 2021 events, which will start days from now, and at the Equinix Analyst Day, Nvidia rolled out more of its software stack while at the same time announcing an effort called AI Launchpad to expand its AI hardware from the public clouds, where the hyperscalers behind them control the hardware designs, to co-location datacenters that are cloud-like but allow customers to either buy and install Nvidia DGX servers and have them hosted and managed by a third party – and if need be, with cloud-like pricing on bare metal instances.
Equinix, which is the world’s largest co-lo operator and which has super-fast pipes into all of the big public clouds and its own Metro Edge locations, is the first AI Launchpad builder. There will no doubt be others because the public cloud is an expensive place to do production workloads over time, regardless of scale.
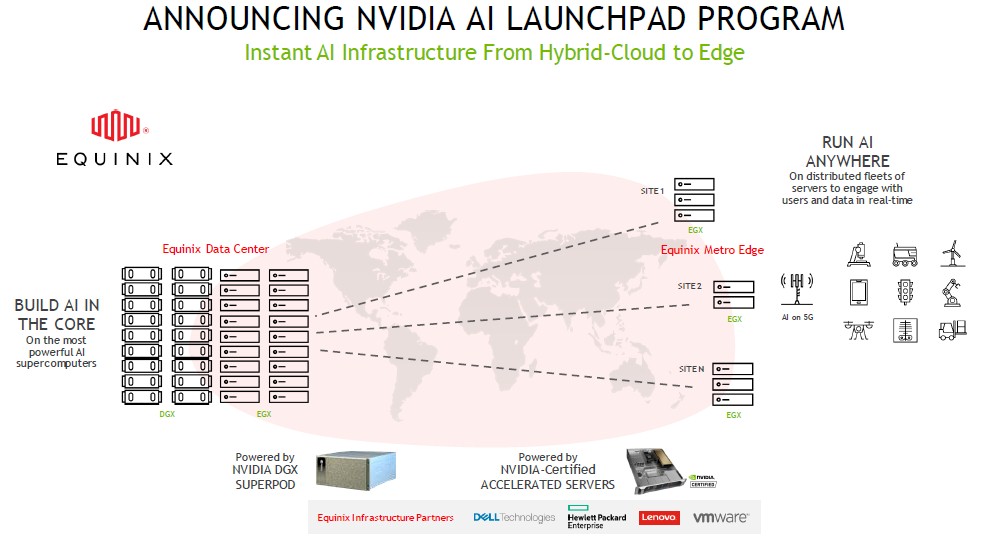
You might be thinking that having all of the major public clouds building and installing GPU-accelerated systems would be sufficient for Nvidia to keep control of AI training workloads and get a very good footing to expand the use of GPUs for AI inference. This is necessary, but not sufficient. For very good economic reasons, enterprises around the world are going to develop in the cloud but deploy within datacenters that give them lower cost and the data sovereignty and workload isolation they have a new appreciation for after a decade and a half of the public cloud. Enterprises want the cloud experience of utility pricing and easily expandable capacity without abdicating all control and without having to be married to any particular cloud vendor. As we have been saying for years, we expect that at a certain scale – somewhere around 50 percent of wall time utilization for cloud capacity – it makes much more sense to rent or buy your own infrastructure than to pay the high margins that the cloud providers demand for their compute, storage, networking, and platform services.
The process of buying infrastructure, however, is a complete pain in the neck and is horribly time consuming. All of the OEMs are trying to turn all of their hardware cloudy in terms of how it is consumed but make it a physical asset that customers can control either on premises or in a co-lo facility. And given that the co-los from Equinix are massively connected to the Internet backbone of the world and the backbones of the hyperscalers and the cloud builders (who carry something stupid like 70 percent of the world’s Internet traffic), a co-lo is a much better answer than trying to pour your own concrete and bring in your own pipes.
“So instead of in our engagements where enterprises say, ‘I need to go buy servers so I will come back in two or three months to get started,’ they can get started instantly,” says Justin Boitano, general manager of enterprise and edge computing at Nvidia. “They can set up the infrastructure in minutes and get those projects going rather than trying to build that infrastructure themselves. That is going to help customers get started on this journey faster and show value to internal stakeholders before making bigger capex investments – and help accelerate the entire cycle for us.”
And yes, this is about Nvidia, which does not want to have the big public clouds have so much leverage over it, either. Nvidia wants as many companies as possible using its AI platform as soon as possible, and not everyone wants to deploy AI in the public cloud. Or is allowed to. Development is one thing, production is quite another, co-los have a much cleaner pricing model than clouds, which soak customers with their hard to predict networking fees even if their compute and storage seems relatively inexpensive.
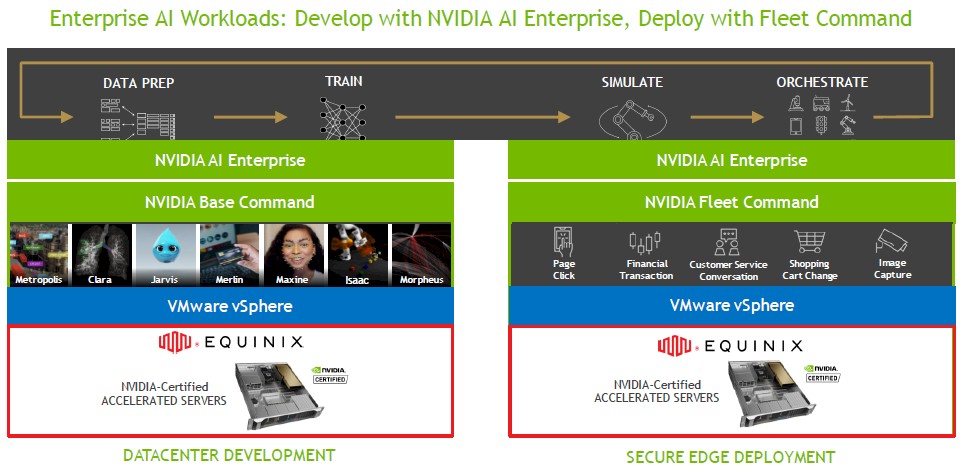
The pricing for AI Launchpad services is intended to be in the “dollars per hour” for bare metal systems and the Nvidia software stack running on top of it, controlling this all. There is going to be a VMware layer in here, too, but the majority of enterprises are already paying the VMware virtual infrastructure tax and using the same compute, storage, and networking substrate in the AI Launchpad service as they are accustomed to in their on premises datacenters makes sense. In the long run, we strongly suspect that the VMware layer can be – and will be – removed and replaced with a bare metal container environment. But don’t get too excited. That will probably be expensive, too. And enterprises will pay it because they don’t have the ability or desire to build their own AI container platform.
(HPC workloads get to piggyback on all of this innovation, by the way. So there is that.)
As part of the AI Launchpad program, both Nvidia and Equinix are making investments in the program, but Equinix will own the hardware that customers deploy, and that includes systems from Nvidia itself as well as Dell, Hewlett Packard Enterprise, and Lenovo, which are OEM partners with Equinix and with Nvidia as well. Other OEMs will follow suit, and some of the ODMs who make iron for the hyperscalers and cloud builders may also play. (Open Compute designs could be a big thing here for companies who want something like what Facebook and Microsoft have as opposed to what Nvidia builds.)
Equinix will roll out its AI Launchpad offering “in the late summer,” says Boitano, starting in the United States and focusing on regions where there are lots of big enterprises who want to start doing AI in production, and then it will roll out globally from there.
As part of today’s announcement, Nvidia is rolling out its Base Command software, which is part of its enterprise AI stack and which was invented so Nvidia could do its own data preparation and machine learning training runs on its own supercomputers. This software costs $90,000 per month to run on Nvidia’s DGX systems, and Boitano says that the company is working on ways to get it certified and available on OEM machines. For edge use cases, Nvidia is announcing the general availability of Fleet Command, which is unveiled at the GTC 2021 event earlier this year and which does orchestration and management of GPU-accelerated systems at the edge that are running AI workloads. As the block diagram shows above, AI Enterprise is the Nvidia commercial runtime for developing models and transforming them into inference engines. Pricing for Fleet Management was not revealed.

AWS Taps Nvidia NVSwitch For Liquid Cooled, Rackscale GPU Nodes
Since the advent of distributed computing, there has been a tension between the tight coherency of memory and its compute within a node – the base level of a unit of compute – and the looser coherency over the network across those nodes. All things being equal, you try to …
Now Nvidia Is Armed To The Teeth
Companies with high stock valuations are a bit like the central banks of major countries. The cash they throw off as leaders in their markets gives them great sway over the industries they play in, and the ever-increasing stock value they have is another kind of money they can spend. …

For Meta Platforms, An Open AI Policy Is The Best Policy
For Mark Zuckerberg, the decision by Meta Platforms – and way back when it was still known as Facebook – to open much of its technology – including server and storage designs, datacenter designs, and most recently its Llama AI large language models – came about because the company often …
Be the first to comment