


If you want to know how and why AMD motors have been chosen for so many of the pre-exascale and exascale HPC and AI systems, despite the dominance of Intel in CPUs and the dominance of Nvidia in GPUs, you need look no further for an answer than the new “Aldebaran” Instinct MI200 GPU accelerator from AMD and its Infinity Fabric 3.0 coherent interconnect that is being also added to selected Epyc CPUs.
The Infinity Fabric coherent memory gets the HPC and AI programmers on board because it simplifies and automates the memory management between the large memory space on the CPU and the fast memory space on the GPUs attached to it. This was the winning combination between the IBM “Cumulus” Power9 processor and the Nvidia “Volta” V100 GPU accelerator that resulted in these chips being the foundation of the 200 petaflops “Summit” supercomputer at Oak Ridge National Laboratories and the 125 petaflops “Sierra” supercomputer at Lawrence Livermore National Laboratories. (Both machines were fully installed in 2018.) The Power9 and the V100 chips all had NVLink 2.0 ports and therefore memory could be coherent across the two CPUs and four or six GPUs in the nodes of these supercomputers.
For whatever reason, Power10 does not support NVLink 3.0 – probably as a consequence of losing the bids with Nvidia for the follow-on “Frontier” 1.5 exaflops system at Oak Ridge and “El Capitan” 2 exaflops system at Lawrence Livermore. We smell some sour grapes. Power10 could easily support the NVLink 3.0 protocol over its “BlueLink” OpenCAPI 3.0 interfaces, but doesn’t. And as a consequence, given that neither Intel nor AMD were going to add NVLink support to their CPUs, Nvidia decided to design its own “Grace” Arm server chip so it can control both the CPU and GPU in future deals. However it happened, Nvidia will be big enough to be a prime contractor on post-exascale systems that will be in the works in 2024 and 2025 – machines that have in excess of 10 exaflops, say, if we want to draw a line somewhere – and it will be in position to supply the CPU and GPU motors for the nodes, the NVSwitch to link them together if it decides to do in-node switching, and the 800 Gb/sec Quantum3 InfiniBand interconnect to lash nodes together. Or, it can let HPE be the prime contractor like AMD is doing for the exascale-class systems. Don’t be surprised if Nvidia launches its own Linux stack, buys SUSE Linux so it doesn’t have to support IBM’s Red Hat Enterprise Linux, or strongly endorses Cray Linux or SUSE Linux.
It is not so much that these issues between IBM and Nvidia killed their potential winning bids for these two key exascale machines, but rather AMD coming in with a single throat to choke and what we presume is more performance and better price/performance won AMD the deals, particularly once Hewlett Packard Enterprise bought Cray and there was a much bigger company – on that can actually afford the bill of materials for machines that cost $500 million or $600 million – acting as prime contractor.
But if you want to narrow the AMD exascale wins at Oak Ridge and Lawrence Livermore down to one single factor, it is the Aldebaran GPUs, which represent the bulk of the processing and memory bandwidth of the Frontier and El Capitan machines.
This time last year, when AMD launched the Instinct MI100 GPU accelerator cards and their “Arcturus” GPU, which supports the compute-optimized CDNA architecture that is a bifurcation from the RDNA architecture used for gaming GPUs, we said that AMD was at a tipping point with its datacenter GPUs. That was because the Arcturus GPU was competitive with the Nvidia “Ampere” A100 on many fronts, and still is on a lot of vectors (pun intended) even after Nvidia boosted its memory last year. But with the Aldebaran dual-chip module, AMD has reworked the underlying CDNA architecture (CDNA 2) and laid down a whole lot of floating point math units to meet or beat Nvidia on throughput and bandwidth. The win is basically a feat of packaging as much as anything else, and also an admission that for HPC workloads and certain parts of the AI stack, 64-bit precision floating point operations matter as much as mixed precision matrix math does.
You have to do all of these things well, as Nvidia so aptly demonstrated with its “Pascal” P100 and “Volta” V100 accelerators over the past five years. We are going to get into this Nvidia versus AMD GPU war separately, and in detail, but for now suffice it to say AMD delivered earth-shattering FP64 performance (like Intel is promising with its “Ponte Vecchio” Xe HPC GPU accelerator) and at some point – very likely next spring – Nvidia is going to have to respond to capture at least some of the next round of supercomputing deals.
Let’s take a look at the Aldebaran GPU package to start:

Each of the two Aldebaran chiplets in the center of the package, which AMD calls a Graphics Compute Die, or GCD, has 29.1 billion transistors and is etched in the 6 nanometer processes of Taiwan Semiconductor Manufacturing Co. The Infinity Fabric circuits completely wrap around the elements of the chiplets, and each chiplet has four Infinity Fabric links, each with 16 lanes of Infinity Fabric, that deliver a total of 800 GB/sec of bandwidth of connectivity between the two chiplets so they can share data. At some point, when more chiplets are added to a package, we expect for there to be an Infinity Fabric switch to link them in a non-blocking manner, like Nvidia does at the server-node level with its NVSwitch.
This particular package of the Aldebaran GPU is designed for the Open Compute Accelerator Module, or OAM, form factor, which Facebook and Microsoft unveiled after their collaboration back in March 2019. Intel is also creating versions of Ponte Vecchio that come in the OAM form factor, as we reported in August. The Nvidia SXM4 form factor used for the A100 GPU accelerator card, we presume, can be modified to fit into the OAM form factor – they look pretty similar, and this is not an accident on the part of Microsoft and Facebook.
Here is what that OAM module with the Aldebaran DCM GPU looks like:

The new CDNA 2 architecture is a superset of the previous GCN and CDNA architectures. With the CDNA compute units used in the Arcturus GPU, matrix math units were added as “first-class citizens” next to floating point shading units. With the CDNA 2 architecture, there are four matrix core units and four 16-wide SIMD units for a total of 64 shader cores in each compute unit, or CU. Each CU has its own dedicated L1 cache and a local data share to move data between the matrix units on the left and the shader units on the right.
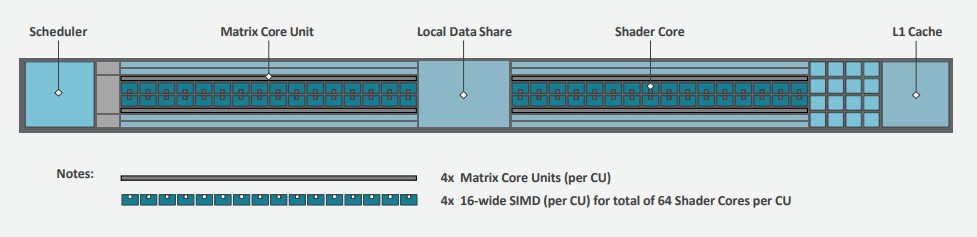
With the CDNA 2 architecture, the matrix cores now support double precision floating point calculations (FP64), and this is much more efficient than using standard FP64 vector units that implement fused multiply-add (FMA) processing. AMD says in a CDNA 2 architecture whitepaper that its FP64 matrix unit delivers twice the throughput of an FP64 vector unit, and also improves energy efficiency at the same time. The FP64 throughput on the Aldebaran chip complex is 4X that of the Arcturus GPU, and without that, there is simply no way AMD would have won the exascale deals. As it is, the performance was good enough that AMD can deliver about 30 percent more FP64 oomph than was expected by the US Department of Energy for its $500 million budget for Frontier and its $600 million budget for El Capitan, and that is what closed the deal. The national labs are not afraid to tweak their codes from fused-multiply add math to matrix math, and frankly, AMD does not have a very large installed base of customers that are using prior Instinct cards, so getting customers to do matrix math is not as big of a deal. Eventually, all GPUs will do their floating processing in matrix math units, and many CPUs will, too, dropping vector units when all the code is ported some generations hence.
To build a GPU, you start blocking off compute units like you are building subdivisions on the outside of a city. The Aldebaran chiplet has four “neighborhoods” that AMD calls a compute engine, each with two columns of 14 compute units. Four of these compute engines, for a total of 112 compute engines, are linked together with a shared L2 cache in the center. Each Aldebaran GCD has 8 MB of L2 cache, and on the high-end MI250, that L2 cache has a peak bandwidth of 6.96 TB/sec, which is more than twice as much as L2 cache bandwidth as was on the Arcturus GPU.
The Aldebaran GPU chiplets are wrapped with four memory controllers and memory PHYs, four internal Infinity Fabric links, three external Infinity links, and a fourth port that can be a PCI-Express controller or an Infinity Fabric link, depending on the model. (This supports the notion that Infinity Fabric is really just PCI-Express with a bunch of HyperTransport point-to-point interconnect protocol stuff running atop it.)
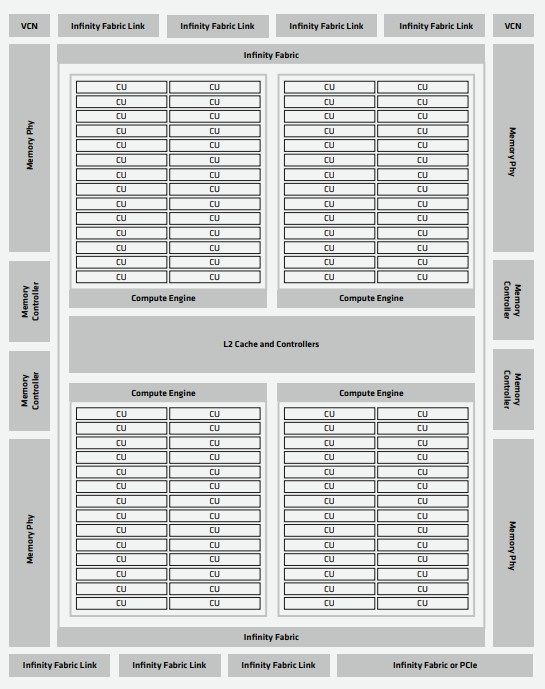
If you turn two of these Aldebaran GCDs on their side and link them by their quad of Infinity Fabric ports and plunk down eight stacks of HBM2e memory on the combined eight memory controllers, you create the Aldebaran package that is at the heart of the Instinct MI200 GPU accelerator:
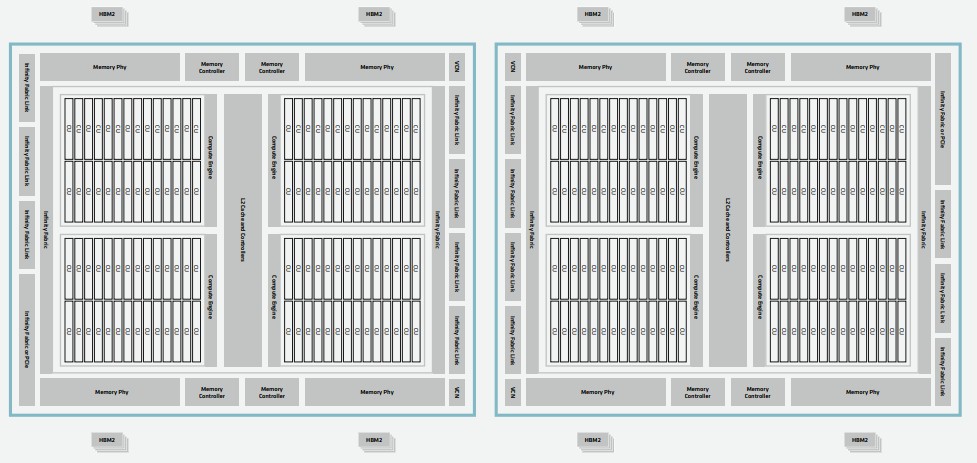
Each Aldebaran GCD has 64 GB of HBM2e memory and delivers 1.6 TB/sec of bandwidth. It is an important distinction (perhaps) that the Aldebaran dual-chip GPU presents itself as two GPUs to software, not as a single device – albeit two devices with a very fast and very fat Infinity Fabric pipes between them. So when we were saying that AMD was “pulling a K80” in reference to the time in November 2014 when Nvidia was late with its “Maxwell” GPUs and did not have enough FP64 performance in them anyway, it put two whole “Kepler” GK110 GPUs on a single PCI-Express card and called it a K80, this is not precisely analogous. The two GK110 GPUs in the K80s were not interconnected and could not share data; the two Aldebaran GCDs are and can.
The external Infinity Fabric ports on the Aldebaran GCDs deliver 100 GB/sec of bandwidth into the Aldebaran complex, so there is either 600 GB/sec for those devices that are configured to have a single PCI-Express controller (for linking network interface cards directly to the GPUs, as is done with the Frontier system) or 800 GB/sec for those MI200 series accelerators that have eight ports all running the Infinity Fabric 3.0 protocol. These ports, by the way, run 8.7 percent faster than the Infinity Fabric 2.0 ports used in the MI100 accelerator from last year.
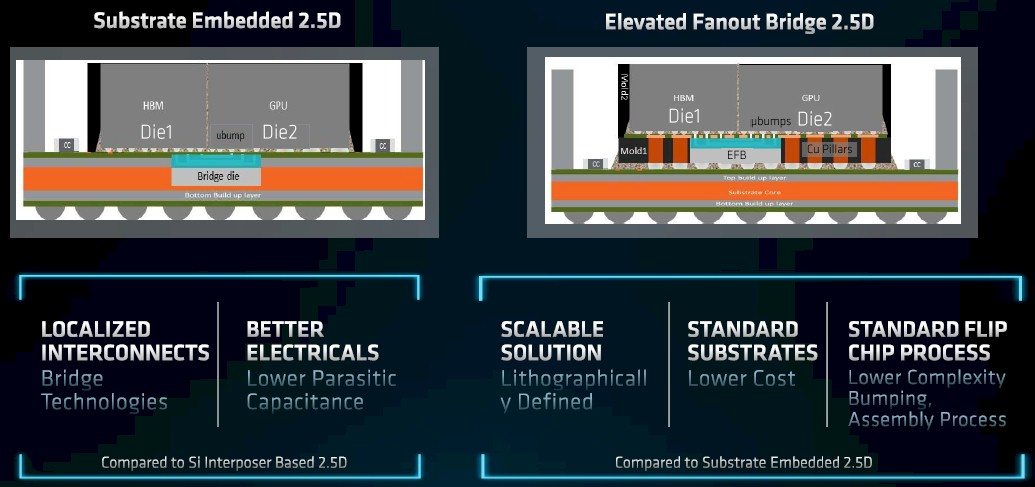
To make the Aldebaran package requires some advancements in, well, packaging. There is some chiplet interconnecting that has to go on in the third dimension – what people call 2.5D because it is stacking just for interconnect, not for compute or memory – at work here, as you can see:
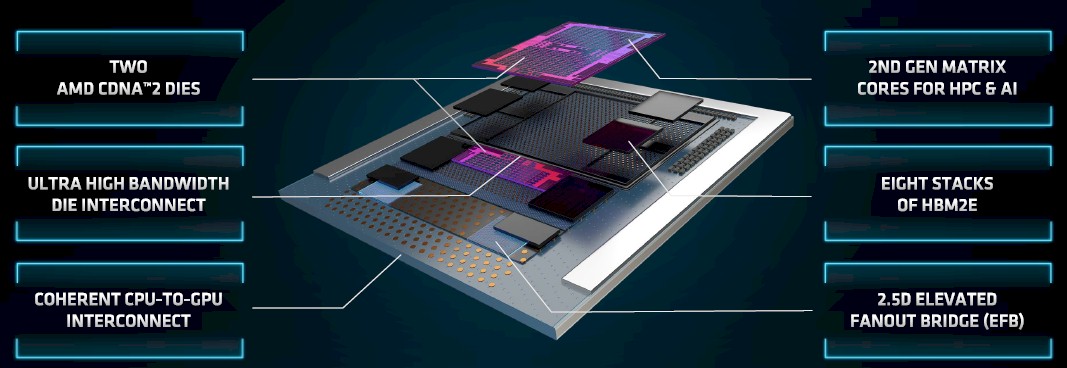
The key new innovation that AMD brought to bear, with the help of TSMC, and which makes it less costly to put a multi-die package together, is called elevated fanout bridge, which is not a silicon interposer bridge or even a substrate embedded bridge as is commonly used in GPU and other kinds of accelerators but is rather a modified substrate bridge that uses standard substrates and assembly techniques, which AMD says provides better precision, scalability, and yields while also maintaining high performance. Here is how the elevated fanout bridge 2.5D technique compares to the substrate embedded 2.5D approach:
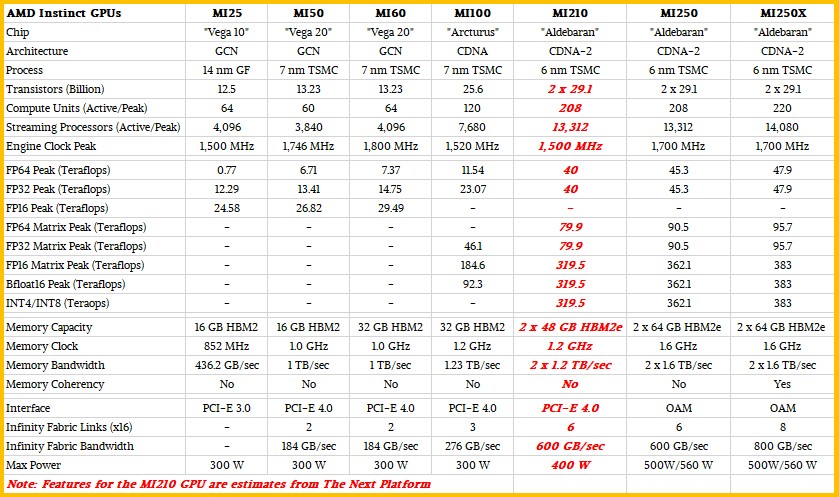
AMD does not have a long history in GPU compute, but it has come a long way in a relatively short five years. And frankly, the early years were kind of embarrassing considering all of the innovation that Nvidia was bringing to bear and all the money that Nvidia was making riding up the HPC and AI waves. But as you can see from the table below, AMD has come a long, long way in those five years – as far as it has come in CPUs against archrival Intel, in fact.
AMD is currently previewing the two OAM variants of the Instinct MI200 series, which includes the MI250 with three external Infinity Fabric 3.0 ports and a single PCI-Express 4.0 portand the MI250X, which has four Infinity Fabric 4.0 ports (which is the one being used in Frontier). There are two variants of each of these: one that runs at 500 watts that is air cooled and another that runs at 560 watts that is liquid cooled; it is not clear how long the peak performance can be sustained on the air-cooled versions, but presumably not for as long as on the liquid-cooled versions. Else, why you would bother with two different wattage ratings?
AMD has promised that a PCI-Express 4.0 card variant of the Aldebaran GPU package is in the works, but has not said anything about what it might look like. We took a stab at what it might look like.
Here is what we can say for sure. The MI250X has 8.3X the FP64 performance of the MI100 if you use the matrix engines and 4.2X the FP64 performance if you stick to the vector engines. Matrix FP32 math is up by 2.1X and so is vector FP32 math and matrix FP16 math. Matrix Bfloat16 is up by 4.2X, and so is matrix INT8 math. In some cases, the number of flops per clock per compute unit have doubled or quadrupled, and then the number of compute units have nearly doubled because there are two GPU dies that have almost the same number of streaming processors each as the Arcturus chip that are lashed together in the Aldebaran complex.
In her keynote address for the Data Center Premier event this week, AMD chief executive officer Lisa Su brought it all home with a single comparison: A single Instinct MI200 accelerator has more raw performance, at any bit precision, than a whole six-GPU, two-CPU node of the Summit supercomputer. Chew on that for a bit.
As for pricing, no one talks pricing. Which means we will have to guess (with some help from our system builder friends) when we do our price/performance comparisons. We’re working on it. We want to dig into how these MI200 series GPUs stack up to the Nvidia A100s, and do more than just say it has 4.9X the FP64 performance and be done with it. The situation is a little more complex than that. Nvidia still has, for instance, the most powerful single piece of GPU silicon, although it is also really eight logical GPUs on that single die.