



The advent of the Data Processing Unit or the I/O Processing Unit, or whatever you want to call it, was driven as much by economics as it was by architectural necessity.
The fact that chips are pressing up against reticle limits and CPU processing for network and storage functions is quite expensive compared to offload approaches have combined to make the DPU probable. The need to better secure server workloads, especially in multitenant environments, made the DPU inevitable. And now, the economics of that offload makes the DPU not just palatable, but desirable.
There is a reason why Amazon Web Services invented its Nitro DPUs, why Google has partnered with Intel to create the “Mount Evans” IPU, why AMD bought both Xilinx and Pensando (which both have a DPU play), and why Nvidia bought Mellanox Technology. The DPU, which is becoming the control point in the network and increasingly the gatekeeper to compute and storage, is at the center of all of the system architectures among these hyperscalers and IT vendors who want to propagate DPUs to the masses.
We have a lot of DPU theory and some hyperscale DPU practice, but as we have complained about in the past, we don’t have a lot of data that shows the cost/benefit analysis of DPUs in action. Nvidia heard our complaints and has put together some analysis using its BlueField-2 E-series DPUs, which have a pair of 100 Gb/sec ports, compared to using a regular SmartNIC with a pair of 100 Gb/sec ports.
Given the state of electricity pricing in the world – it is going up faster in Europe than in North America the savings in power from using DPUs will be more or less. But according to John Kim, director of storage marketing at Nvidia who put together the price/performance comparisons of clusters using and not using DPUs, even at the 15 cents per kilowatt-hour that prevails in California, the addition of DPUs to systems in a cluster more than pays for itself with the power saved through server footprint shrinkage as cores are released from the server nodes that had been running network and storage functions.
The presentation that Kim put together showed the effect of offloading Open vSwitch (OVS) from hypervisors running on the servers to the BlueField-2 DPU and then another one showing the User Plane Function (UPF) workload from Ericsson being offloaded from the server CPUs in a 5G base station to a DPU running in the chassis. In each case, Nvidia calculated the effect of adding DPUs for these offloads across a cluster of 10,000 machines, and only calculated the savings in power at those California electricity rates. In both cases, Nvidia calculates how many cores on the servers were running either workload and how many watts it burns and then how many watts it takes to run it on the DPU, and then calculates the savings in power and the lower power cost over a three-year term. Nvidia did not try to assess the economic value returned for the cores freed up by the DPU offload.
Here are the performance increase and power savings numbers for the OVS offload:
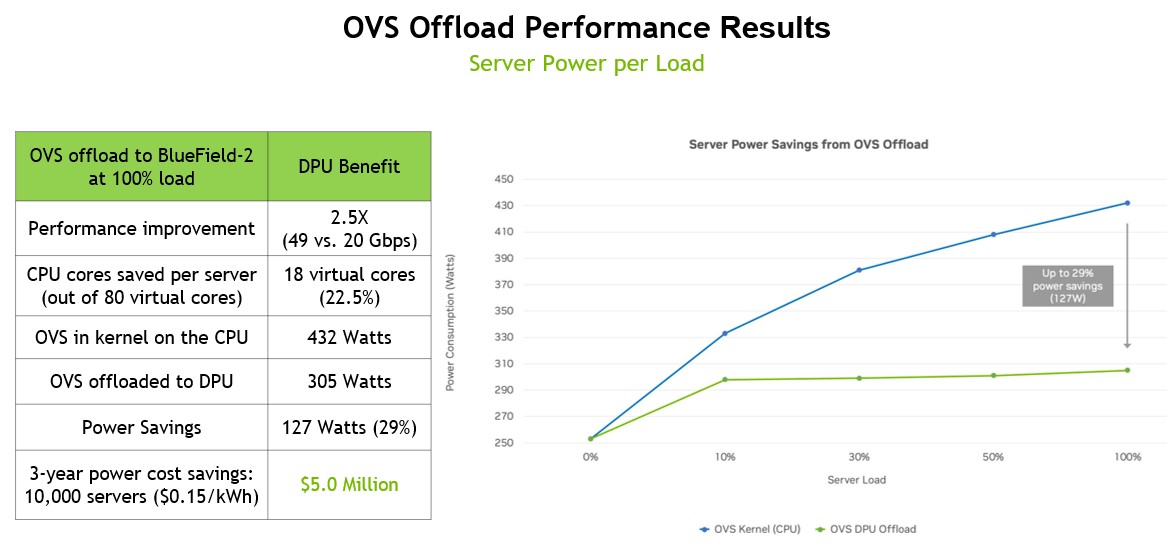
This benchmark test was run on a Dell PowerEdge R740 server with a pair of Intel “Cascade Lake” Xeon SP-6248 Gold processors, which have 20 cores each running at 2.5 GHz and a BlueField-2 DPU with a pair of more modest 25 Gb/sec Ethernet ports. To run OVS on the server requires 18 threads and 9 cores out of the total of 80 threads and 40 cores, which represents 22.5 percent of the compute capacity inherent in the machine and also the same share of the total 150 watts CPU watts in theory and an actual 432 watts across the entire server. By moving to the OVS workload to the DPU, OVS only consumes 305 watts as it runs, and if you spread that power savings across 10,000 nodes, then the three year savings is $5 million.
Importantly, the throughput of the OVS switches goes from 20 Gb/sec to near the peak theoretical performance of the two ports on the DPU, at 49 Gb/sec. There is an obvious performance benefit, but this is more like getting the performance inherent in the network and it is not clear what effect this has on actual application performance. Those Xeon SP-6248 Gold processors have a list price of $3,622, so those nine cores have a value of $814.50 and obviously a similar 22.5 percent share of all the other components in the server. (We don’t know what this server costs, so we can’t say for sure how much.)
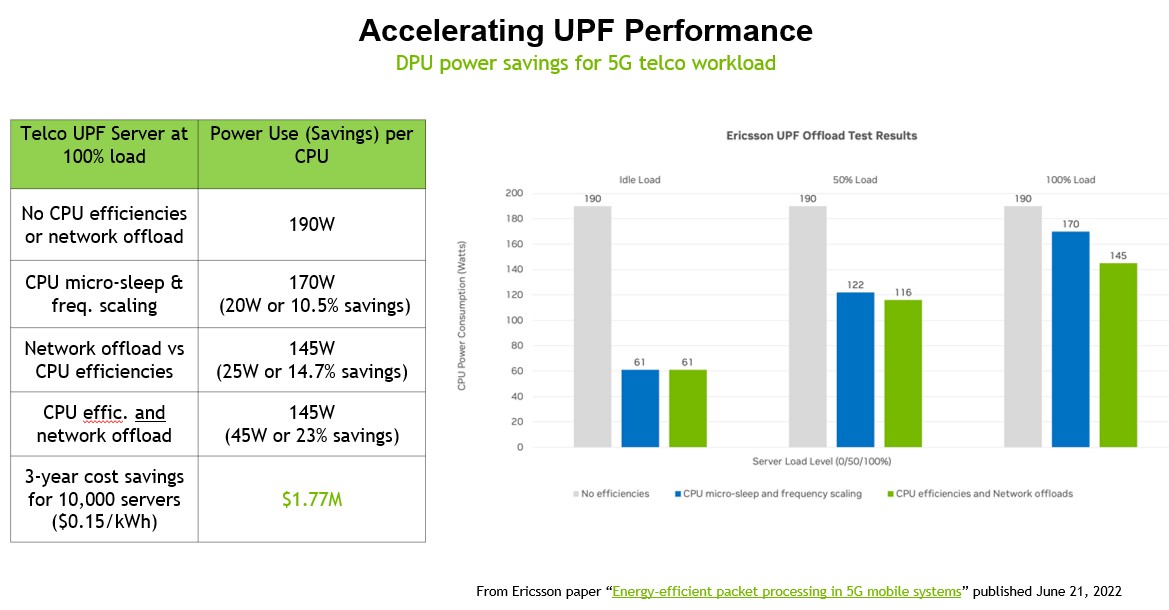
On the Ericsson UPF benchmark, which you can read all about in this paper published back in June, the wattages are lower, the server costs are lower, but the savings are still substantial, as you can see here:
Where the DPU is really shining – and for the moment is perhaps most acutely needed in IT organizations – is for encrypting data as it passes between servers as they run applications and from servers to client devices accessing applications and data. So Nvidia created an IPSec encryption scenario for encrypting the server and client sides of applications and how much power savings would result. Take a look:
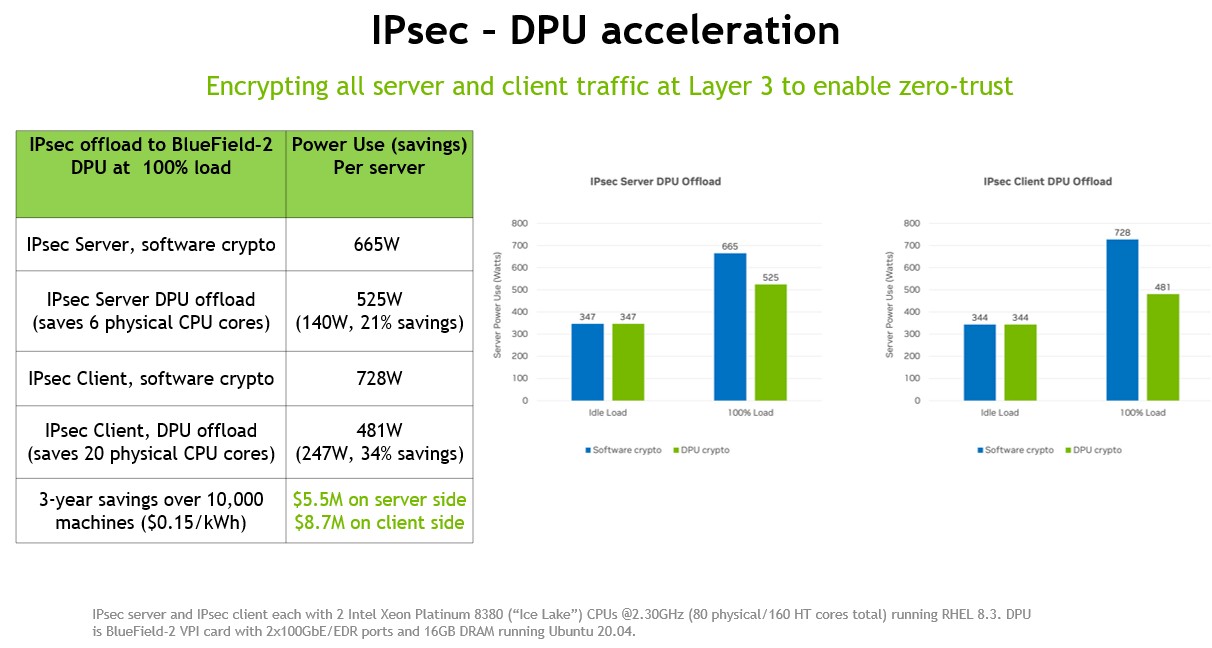
This set of tests was run on a server with a pair of Intel “Ice Lake” Xeon SP-830 processors with 40 cores each running at 2.3 GHzm with a BlueField-2 card with a pair of 100 GB/sec Ethernet ports and 16 GB of its own memory. On this setup, the server side IPSec encryption and decryption consumes six physical cores (which is 7.5 percent of the cores) and the client side requires a much more hefty 20 cores (or 25 percent). We don’t know if there is a performance delta here between the CPU and the DPU running IPSec, but what Nvidia did calculate us the power savings of doing the offload to the DPU, which adds up to $14.2 million across 10,000 nodes over three years.
Our complaints with DPU makers in the past when they make such claims have been that they do not provide direct costs for the before and after scenarios so we can look at the numbers ourselves. And so Kim provided a table that shows the detailed costs of the hypothetical 10,000 node cluster running the CPU-only and DPU offload configurations. In this case, Nvidia is holding the non-IPSec workload – meaning the real work that the cluster is supposed to be doing – steady, and that means as the DPU frees up 26 cores out of 80 cores per server, it means that a DPU-accelerated cluster with only 8,200 servers can do the same work as 10,000 machines that are running IPSec in software.
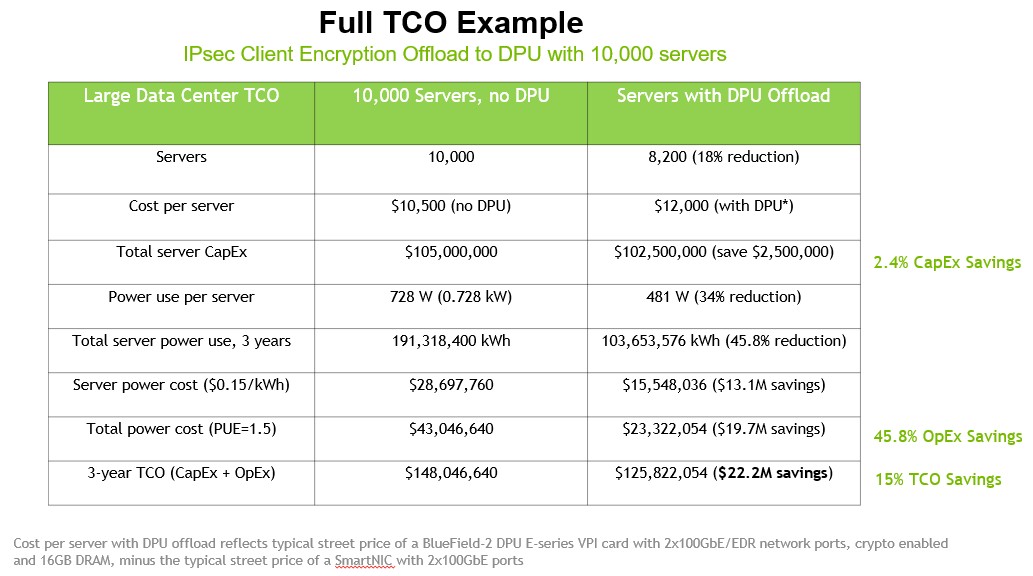
In this scenario at least, we can see that the incremental cost of a BlueField-2 E-series DPU with two 100 GB/sec ports is $1,500, which probably means it has a street price of $2,500 if a typical two-port SmartNIC with a pair of 100 Gb/sec ports costs around $1,000. (Nvidia does not provide pricing, OEM or street or manufacturers suggested retail pricing for its networking products.)
What is immediately obvious from this comparison is that the addition of the BlueField-2 DPU to each of the 10,000 nodes pays for itself in the reduction of nodes needed to support the IPSec encryption and decryption workload. By Nvidia’s math, the capital expenditures on the server hardware are actually 2.4 percent lower.
On top of that, there is a $13.1 million savings in server power and, assuming a power usage effectiveness of a very modest 1.5, there is another $6.6 million in savings in cooling in the datacenter from the cluster consolidation engendered by the DPU. Add up the capex and power savings, and the whole shebang shaves $22.2 million in savings over three years. That’s a 15 percent savings in total cost of ownership – and that is without taking into account any difference in performance or savings in datacenter real estate or having fewer servers to manage.
Now here’s the fun bit as we are thinking about it. The pendulum is swinging towards disaggregation and offload for now, with all kinds of work getting dumped from the CPU to all kinds of accelerators hanging off the PCI-Express bus. But as Google and Amazon Web Services have both pointed out, the system on a chip (SoC), and really it is the system in package (SiP), is the new socket, and as we get better and better at 2.5D and 3D packaging, don’t be surprised when UCI-Express becomes the in-socket interconnect and DPUs are pulled into the sockets for CPUs, GPU, and FPGAs as well as being freestanding units. The need to pack circuits close together for low latency may require such re-integration.
But it is probably safe to say that these network and storage access and virtualization workloads and security functions will won’t be done on CPUs – whatever the term central processing unit means anymore – in future system architectures. We have said for a while that the DPU is going to become the center of the system architecture, doling out access to compute and storage, and the CPU as we know it should properly be called a Serial Processing Unit with fat, slow memory.