
Sponsored Feature: Back in the old days, there was a CPU and chip designers crammed everything into that single CPU, which made sense for the greatest number of customers offset against the additional cost of adding extra functionality. Any kind of specialized computing ended up being implemented on special accelerator cards running on the peripheral bus or implemented in higher level software running on the CPU. And that caused obvious, but inevitable, inefficiencies due to the economics involved.
Here in the second decade of the 21st century, the same economics and desire for accelerated functions are playing out. But instead of doing so across the motherboard they are more likely to be playing out inside of a socket, which is itself more like a motherboard and in many ways a self-contained system in its own right.
CPUs these days do not just have multiple cores, but nested hierarchies of clusters of cores with their own distinct NUMA memory regions. Some specific and more generic forms of acceleration are etched directly into the cores, just like with single-core CPUs in the old days.
But thanks to the amazing chip transistor densities and chiplet packaging techniques available today, other forms of acceleration are not pushed out to the PCI-Express bus, far away from cores and main memory. Instead, they’re implemented outside the cores but on the core complex chiplets themselves or in distinct chiplets that are interconnected inside the socket package.
To a certain extent, all modern server CPUs have a mix of standard integer and floating-point compute in the cores and other kinds of compute in the non-core regions of the package. And so when comparing processors from different vendors, it is important not to just count cores and clock speeds and the resulting integer and floating point performance on industry standard benchmarks from SPEC. You must look at specific workloads and the extent to which the accelerators inside of the cores, as well as those outside of the cores, work in concert to boost real-world application performance.
A Cornucopia Of Accelerators
Over the years, Intel has been adding greater numbers of more diverse accelerators to its Intel® Xeon® and Intel® Xeon® SP server CPU architectures. This has been driven by the needs of specific applications which Intel has targeted to grow its Xeon and Xeon SP footprint beyond general purpose compute in the datacenter running applications written in C, C++, Java, Fortran, Python, PHP, and other languages. In some cases, the move from datacenter compute into adjacencies such as network function virtualization (NFV) or storage – where custom ASICs have been replaced by X86 CPUs – drove the addition of specific accelerators. The same is true in the HPC simulation and modeling, and AI training and inference, spaces.
As GPUs have been redesigned to support the heavy vector and matrix math used in HPC and AI applications, and custom ASICs have been invented to push performance even further than GPUs, Intel (amongst other server CPU makers) has been fattening up vector engines and allowing them to support lower precision integer and floating-point data to pull some of this HPC and AI work back onto the CPU.
And in more recent processors, matrix math units designed specifically to accelerate the specific low precision matrix math commonly used on AI inference (and sometimes training) are also being added to the compute complex.
With the “Golden Cove” cores used in the “Sapphire Rapids” 4th Gen Intel® Xeon® Scalable processors, the existing AVX-512 math unit has been expanded to include support for accelerating certain math algorithms commonly performed by vRAN software running on 5G network base stations, for example.
The Golden Cove cores also bring a new Intel Advanced Matrix Extensions (AMX) unit, which allows for larger matrices to be added or multiplied in a single operation and that deliver much more throughput than running mixed precision integer operations on the Intel AVX-512 vector unit.
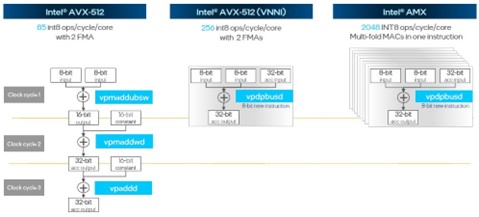
Both the Intel AVX-512 and Intel AMX math units in each core can be used simultaneously – it is not an either/or proposition. But clearly, for relatively small matrices the INT8 performance of the Intel AMX unit, which offers an 8X increase in raw throughput, is going to be compelling, particularly for (but by no means limited to) AI inference work. And given that the natural place to do AI inference is within the CPU where the applications are running, the addition of the Intel AMX accelerator will help Intel protect its AI inference turf. The majority of AI inference is still done on CPUs today, and Intel would like to keep it that way.
We’ll shortly do a deeper dive on running AI inference natively on the Sapphire Rapids CPUs and speak more generically about the performance benefits of these and other accelerators.
Before we get into some of the performance boost examples from the Intel accelerators, it would be helpful to show the full cornucopia of acceleration, which is by no means limited to the Intel AMX matrix units and Intel AVX-512 vector units in the Xeon SP cores. Here is how the accelerator variety has grown over the four generations of Xeon SP processors:
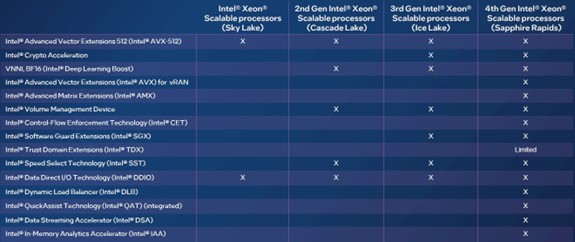
The Intel AVX-512 vector units have been around since 2015, and only now is AMD supporting an equivalent functionality in its “Genoa” Epyc 9004 processors. Ditto for BF16 and FP16 half-precision support in the Intel AVX-512 units, which Intel put into the Xeon SP line back in 2019 and which increased AI inference throughput.
For many workloads, a combination of accelerators are used to boost the overall performance of an application or the systems software underpinning it. And to that end, Intel groups those combinations of accelerators for specific kinds of workloads into what it calls Intel Accelerator Engines.
This is the abstraction level that is, perhaps, most useful for companies evaluating server CPUs and how acceleration can boost performance while also freeing up cores to do more of the current processing in any given workload, or take on additional and distinct work.

The performance of workloads that are boosted by these accelerator engines will depend, of course, on the specifics. But conceptually here is how the acceleration works in each case to maximize the effectiveness of every core on a Sapphire Rapids CPU:
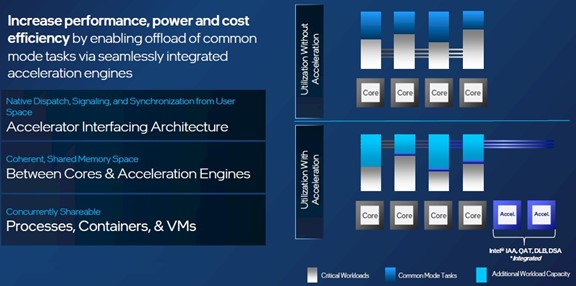
Some functions are accelerated on the core and some are accelerated off the core in that mix of accelerator engines. The net effect is that the resulting Xeon SP behaves like a CPU with many more cores on it. Again, it all depends on what functions are being accelerated. Aside from the Intel AVX-512 and Intel AMX units on the cores, here are the schematics for four of the important off-core accelerator engines:
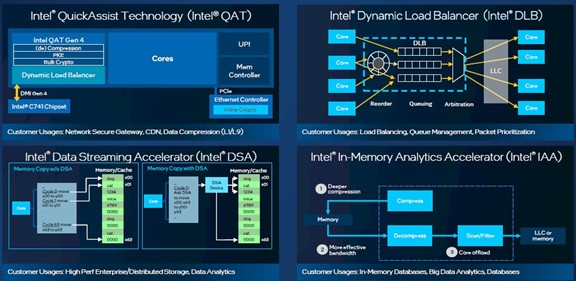
Now, to some proof points on the performance boost that comes from using the non-core accelerators.
Let’s start with the Intel Quick Assist Technology accelerator, or Intel QAT, which performs data compression and decompression as well as encryption and decryption. Running the NGINX secure gateway, it took 84 percent fewer cores to run this software when accelerated by Intel QAT than it did running NGINX straight out of the box on a 4th Gen Xeon SP without Intel QAT turned on. This test was done on a two-socket server using top bin 60-core Xeon SP-8490H processors, so that means what took 120 cores to run without Intel QAT took only 19 cores with Intel QAT. That freed up a whopping 101 cores, according to Intel’s tests.
The Intel Dynamic Load Balancer, or Intel DLB for short, does just what you think it does: it load balances data across cores and network interfaces to keep data movement from hitting congestion. Using the Istio ingress gateway as a microservices workload, the latency for data ingestion was up to 96 percent lower with Intel DLB on and kept the same throughput as Istio running with Intel DLB turned off. This test was run on a two-socket machine using 56-core Xeon SP-8480+ processors.
The Intel Data Streaming Accelerator, or Intel DSA, optimizes streaming data movement and data transforms. On a two-socket server based on 60-core Xeon SP-8490H processors with Intel DSA turned on, the I/O operations per second were 1.7X higher than with a machine that was merely equipped with the Intel Storage Acceleration Library. That is like having a machine with 204 cores without Intel DSA.
And finally, the Intel In-Memory Advanced Analytics accelerator, shortened to Intel IAA, gooses the performance of analytics primitives, CRC calculations, and data compression and decompression commonly used in databases and datastores. With Intel IAA turned on, the RocksDB open source database was able to process 2.1X more transactions than the same machine with Intel IAA turned off and using the Zstd data compression that is part of RocksDB. This test was performed using a pair of 60-core Xeon SP-8490 processors. That is akin to having a machine with 252 cores without Intel IAA.
All of which means Intel is not stressing about core counts as much as you might think it should.
Sponsored by Intel.
