
Depending on how you look at it, a database is a kind of sophisticated storage system or storage is a kind of a reduction of a database. In the real world, where databases and storage are separate, there is a continuum of cooperation between the two, for sure. There is no question that relational databases drove the creation of storage systems every bit as much – and drove them in very different directions – as file serving and then object serving workloads have.
What if you didn’t have to make such choices? What if your storage was a real, bona fide, honest to goodness database? What if Vast Data, the upstart maker of all-flash storage clusters that speak Network File System better and with vastly more scale than more complex (and less useful) NoSQL or object stores, was thinking about this from the very moment it was founded, that creating a new kind of storage to drive a new kind of embedded database, was always the plan? What if AI was always the plan, and HPC simulation and modeling could come along for the ride?
Well, the Vast Data Platform, as this storage-database hybrid is now called, was always the plan. And that plan was always more than the Universal Storage that was conceived of in early 2016 by co-founders, Renen Hallak, the company’s chief executive officer, Shachar Fienblit, vice president of research and development, and Jeff Denworth, vice president of products and chief marketing officer, and launched in February 2019. This is a next platform in its own right, which means that it will have to do clever things with compute as well. So maybe, in the end, it will just be called the Vast Platform? But let’s not get ahead of ourselves.
Then again, why not? The co-founders of Vast Data did way back when.
“Back in 2015, in my pitch deck, there was one slide about storage in that entire deck, which had maybe fifteen slides,” Hallak tells The Next Platform. “One of them had storage in it, the rest of them had other parts that needed to be built in order for this AI revolution to really happen in the way that it should. Eight years ago, AI was cats in YouTube videos being identified as cats. It was not close to what it is today. But it was very clear that if anything big was going to happen in the IT sector over the next twenty years, it would be AI and we wanted to be a part of it. We wanted to lead it. We wanted to enable others to take part in this revolution that looked like it might be confined to a few very large organizations. And we didn’t like that. We want to democratize this technology.”
And that means more than just creating a next-generation, massively scalable NFS file system and object storage system based on flash. It means thinking at ever-higher levels in the stack, and bringing together the concepts of data storage and a database against the large datasets from the natural world that are increasingly underpinning AI applications.
Data in no longer restricted to limited amounts of text and numbers in rows or columns in a database, but high resolution data – video, sound, genomics, whatever – that would break a normal relational database. AI workloads need enormous amounts of data to build models, and lots of performance to drive the training of models and sometimes an enormous amount of compute to run inference on new data as it enters the model. All of this puts tremendous pressure on the storage system to deliver information – something that Vast Data’s Universal Storage, a disaggregated shared everything implementation of NFS that has a very fine-grained quasi-object store underneath it, can handle.
“Data has a lot more gravity than compute does,” Hallack adds. “It’s bigger and it’s harder to move around. And so for us to play in that AI space, we cannot confine ourselves just to the data piece. We have to know something and have an opinion about how the data is organized. It is about the breaking of tradeoffs, and it is not just a storage thing. If you take out that word storage, and put in the word database, the same type of challenges apply. Cost, performance, scale, resilience, ease of use – these are not storage terms. They’re very generic computer science terms.”
The first inklings of the Vast Data Platform were unveiled in the Vast Catalog, introduced in February of this year, which basically put a SQL front end and semantic system on top of the NFS file system and object storage underpinning the Universal Storage. This was the first hint that a new engine was underneath the covers of the Universal Storage that supported SQL queries. Now, Vast Data is taking the covers completely off, revealing how the data storage and database have been converged into a single platform and how it will eventually have a compute layer.
And as such, we are going to treat the Vast Data Platform announcement just like we would a server compute engine announcement, giving it an overview to start (that would be this story you are reading) and then a deep dive after we do some digging into the architecture. Technically, we are on vacation at the beach in Hilton Head Island, South Carolina and have children to play with on the beach. . . .
A Full Stack Problem, Indeed
As Jensen Huang, co-founder of Nvidia, is fond of saying, AI is a full stack problem and Vast Data, like Nvidia, has been thinking about the full stack from Day One. As far as we can tell, Vast Data has no interest in making hardware for compute, storage, or networking and is perfectly happy to leave that to others. Because, quite frankly, it has better things to do.
Like mashing up exascale class storage with a native database to get rid of AI workflows like this one, from Amazon Web Services:
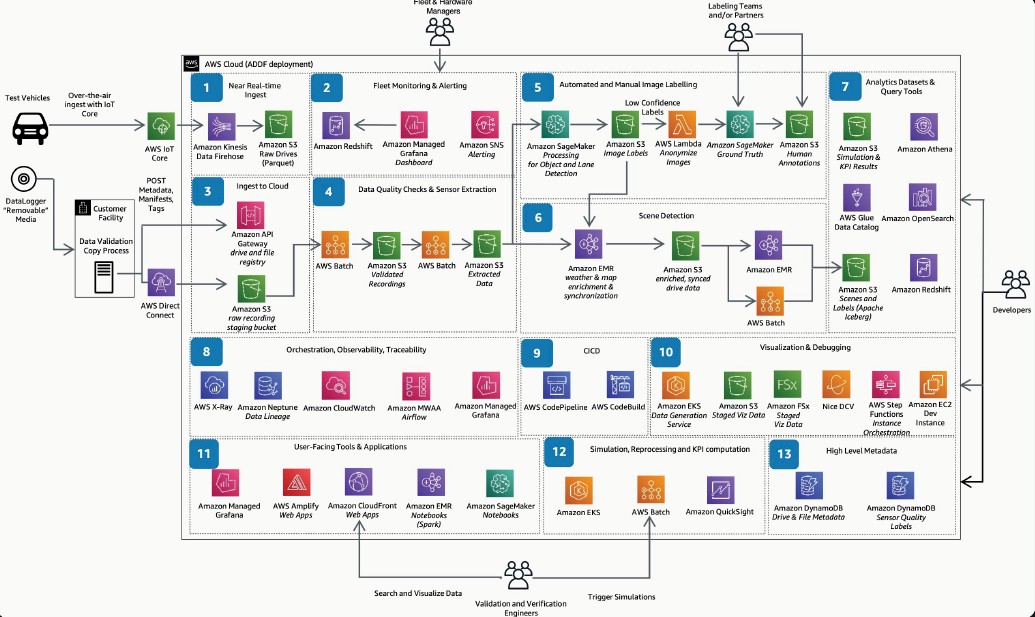
But it is more than that. It is about making sense of truly vast amounts of data.
“GPT-3 was trained on about 45 terabytes of data, which I don’t think is a lot of data in the grand context,” Denworth tells The Next Platform. “We are now working with a series of people that are building foundation models – so organizations of the ilk of Inflection AI – and we are starting to see plans for multi-exabyte single datastores. Some of the biggest business I’ve ever seen in my life is happening in the span of around eight weeks. And one of the considerations is that as you move beyond text, to the data of the natural world, the corpus grows by orders of magnitude. At the moment, there are only a few organizations on Earth that can capture that much unique information and make sense of it, and the question is: Why?”
The answer is that this is all too hard and too expensive, and there has to be a way to make it easier, faster, and cheaper. Something that looks more like this:
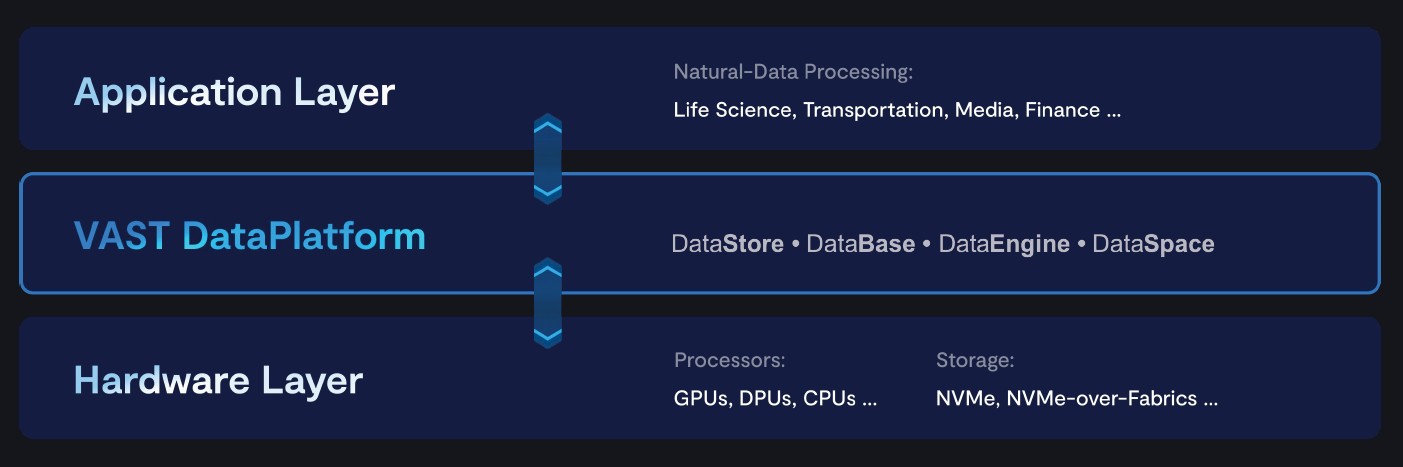
The first time we know where someone tried to create a data platform like this was a long, long time ago – relative to the timeframes of the computer industry at least — and it worked within its own context and limitations to a certain extent. The second example we know of was an abject failure, and the third had such poor performance that no one talks about it anymore.
Way back in 1978, when IBM created the relational database, it did not commercialize it first on the venerable System/370 mainframes of the time, but on a little used but architecturally significant machine called the System/38. The brilliance of this machine is that the operating system had a relational database embedded within it, and it was accessed just like a flatfile datastore but it had all of these SQL extensions that allowed users to query the data in ways that you cannot actually do in a flatfile datastore. In effect, the relational database was the file system, and there was never a way to store data that was not able to be queried. The only trouble with this approach is that it took a lot of computation, and MIPS for MIPS, the System/38 loaded up with a relational database stack was 2X to 3X more expensive than a System/370 mainframe of the time. It wasn’t until the AS/400 was announced by IBM in 1988 that the cost of compute came down enough for this to be more practical, but it was still a slow file system. And by the late 1990s, IBM grafted the OS/2 Parallel File System to the OS/400 operating system so it could have a proper Internet file system and the database was relegated to being just a database.
Big Blue had the right idea, but it was ahead of the computational budget of the time. Just like AI algorithms created in the 1980s more or less worked, but they needed orders of magnitude more data and orders of magnitude more compute to drive the neural network to actually work.
Microsoft also had the right idea with the Object File System that was part of the “Cairo” Windows and Windows Server kernel in the 1990s, which was reborn as WinFS with the “Longhorn” Windows and Windows Server release in the early 2000s. Microsoft, too, understood that we all needed to store structured, semi-structured, and unstructured data in the same database/datastore and allow it to be queried using SQL.
And finally, there was Hadoop, the clone of the Google MapReduce data querying algorithm and massively distributed, unstructured datastore. Eventually, various SQL overlays were added to Haoop, including Hive, HBase, Impala, and Hawq, and while these worked, the performance was abysmal. Relational databases could not scale anywhere as far as Hadoop, and Hadoop was orders of magnitude slower at querying data than a relational database – and that is not particularly fast in the scheme of things.
Which brings us all the way to today and the Vast Data Platform. The team at Vast Data is taking another run at the idea, and they have a unique storage architecture that just might bring this age-old vision to fruition.
We look forward to getting into the weeds and figuring out how and why.


In The Multicloud World, The Data’s The Thing
When three years ago Dell rolled out its Apex initiative, the massive IT supplier was joining a growing list of tech companies like HPE, Lenovo, and Cisco who were adapting to a rapidly expanding multicloud world by making their product portfolios available in a cloud-like, as-a-service model. Organizations wanted more …
The Pure Unification Of Block And File Storage
Companies have been working for years to pull together block, file, and object storage under a single umbrella, giving enterprises that are at times dealing with petabytes of data spread across datacenters, the cloud, and the edge a simpler way to manage, organize, and access all that information. We have …

The AI Boom Props Up Datacenter Infrastructure Spending
If there is one thing that is absolutely immune from inflationary curbs and that is, to a certain degree, also contributing to inflationary pressures in the global economy, it is generative AI. In fact, from the limited data we have about server and storage spending in the world right now, …
Be the first to comment