
It took the X86 architecture fifteen years get an appreciable share of datacenter compute, and it took the Arm architecture about ten years to get a foothold you could measure. Perhaps it might only take five years for the RISC-V architecture to do the same because the hyperscalers and cloud builders are tired of not controlling their own infrastructure fates more than they already do.
This is certainly something that companies like Tenstorrent, SiFive, Esperanto Technologies, and Ventana Micro Systems are counting on happening. And given the ability and desire of the hyperscalers and cloud builders to control their own hardware and software stacks and their admission that they do not have to design everything down to the transistor, we think that companies that both build chiplets and license IP are going to get some business from these datacenter titans to speed up the design cycles for their servers.
It was only back in December 2022 when Ventana, whose co-founders and engineers have deep experience in designing X86 and Arm server chips, revealed the Veyron V1 server chip design, for which we did an in-depth drilldown on back in February of this year. This processor was absolutely competitive with X86 and Arm server chips of the time, and we showed that in our analysis. With the Veyron V1 chiplets shipping in the second half of this year, and available as FPGA emulators since last year, you might be wondering why Ventana has been so quick to get the kicker Veyron V2 in the field.
The answer is that Ventana had to compete with a new round of X86 and Arm server chips that are in the field and also shift chiplet interconnects for its RISC-V server designs at the request of the hyperscaler and cloud builders who are looking for a leg up in creating RISC-V server chips.
The interconnect shift is a subtle but important one. With the original Veyron V1 designs, which have been in the works for two years, Ventana picked the best option that was available at the time for chiplet interconnects, which is called Bunch of Wires, or BoW for short, and which is controlled by the Open Domain Specific Architecture group within the Open Compute Project. That was about as open as a standard could get, particularly when considering that Ampere Computing, Alibaba, AMD, ARM, Cisco Systems, Dell, Eliyan, Fidelity Investments, Goldman Sachs, Google, Hewlett Packard Enterprise, IBM, Intel, Lenovo, Meta Platforms, Microsoft, Nokia, Nvidia, Rackspace, Seagate Technology, Ventana, and Wiwynn were all behind BoW and working on that standard for a fast, wide, and cheap die-to-die interconnect to make the promise of mixing chiplets across processes and vendors a reality.
But then Intel came along with the alternative Universal Chiplet Interconnect Express, or UCI-Express, standard back in March 2022, essentially spiking its own Advanced Interface Bus, a royalty-free PHY for connecting chiplets that was announced in 2018 – well ahead of the BoW effort. Because the IT industry likes technical differentiation and choices, and Intel likes to exert more control than it was getting in the BoW effort, UCI-Express was born, much like the Compute Express Link, or CXL, standard was formed by Intel to put memory semantics atop PCI-Express and adopted by just about everybody who had a competing approach to coherent memory across CPUs and accelerators. UCI-Express was endorsed out of the gate by Advanced Semiconductor Manufacturing, AMD, Arm Holdings, Intel, Google, Meta Platforms, Microsoft, Qualcomm, Samsung, and Taiwan Semiconductor Manufacturing Co. HPE, IBM, and Nvidia were missing from the initial UCI-Express push, but they will eventually come around.
Balaji Baktha, co-founder and chief executive officer of Ventana, says that in talking 46 current and potential customers looking at the Veyron V1 and V2 CPU designs, it became apparent that UCI-Express was the way to go for chiplet interconnects. And hence the company accelerated its Veyron V2 launch, which includes substantial RISC-V core enhancements, as it adopted UCI-Express rather than BoW for its chiplet interconnect.
Here is a comparison of the feeds and speeds of the BoW, AIB 2.0, and UCI-Express 1.1 interconnects, complements of a paper put together by Lei Shan, who used to work at IBM’s TJ Watson Research Center on interconnect hardware and who is now at Arm server chip upstart Ampere Computing:
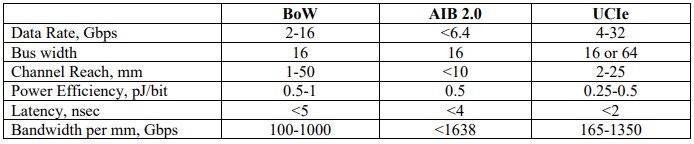
As you can see, the data rate for UCI-Express is 2X that of BoW and the bus bandwidth can be the same or 4X higher. The channel reach is half the distance for UCI-Express, but the power efficiency is 2X better on the links and the latency is less than half of that of BoW. The bandwidth per millimeter is anywhere from 35 percent to 65 percent higher, too.
“Invariably, if chip designers want to use chiplets, they are going to have to support to be UCI-Express,” Baktha tells The Next Platform. “There is a tremendous push and a lot of momentum behind UCI_Express because everybody wants a standard. BoW could have been a standard. But we don’t want to be the ones who continue to build that going forward because the UCI standard also solves packaging costs effectively, and is yielding at a very optimal level. UCI also solves 3D memory stacking problems. So it’s easy to leverage UCI-Express 2.0 and bridge the gap that exists with UCI-Express 1.0 using our own expertise – for instance, UCI did not provide links to the AMBA CHI coherent interface bus at all. So we added AMBA capability on UCI 2.0.”
The other big change that Ventana wanted to grab quickly and put into its Veyron V2 core design was the RISC-V Vector 1.0 512-bit vector extension that is akin to that now offered by Intel “Knights” Xeon Phi processors starting in 2015 and in “Skylake” Xeon SP processors in 2017 and just added to AMD “Genoa” Epyc processors a year ago. These 512-bit vector engines are not literally a clone of Intel’s AVX-512 (like the ones in the AMD Genoa chips are at the software level at least) but they are close enough to not create a total software nightmare for Linux developers who want to port their code from X86 to RISC-V. Moreover, the 512-bit vectors will offer competitive performance with X86 and Arm processors for HPC and AI workloads where the CPU will do the math rather than an accelerator either on the CPU package or external to the CPU like GPUs and other accelerators often are.
Ventana has added extensions to the V2 core that allow that vector engine to support matrix operations as well as to allow customers to add their own matrix engines to the architecture, either in the core or adjacent to it in a discrete chiplet using UCI-Express links. By the way, the V1 core did not have any vector engines or matrix engine extensions, which was obviously going to be a problem since a lot of AI inference is still being done on CPUs and in some cases AI training and HPC simulation and modeling is also done on CPUs.
The other big change with the Veyron V2 design – we keep saying the full core name so as to not get confused with the “Demeter” V2 core with a pair of 256-bit vectors from Arm Ltd in its Neoverse CPU designs – is that Ventana has created a substantially improved RISC-V core.
By fusing instruction processing more aggressively in the Veyron V2 core and making a lot of other tweaks, Ventana has been able to boost the instructions per clock (IPC) for a basket of workloads by 20 percent. The top-end clock speed of the V2 is pushed up to 3.6 GHz, compared to 3 GHz for the Veyron V1 core, too, which boosts the performance of the core by another 20 percent, to yield a 40 percent overall performance boost from the V1 core to the V2 core in Ventana’s Veyron RISC-V CPU designs.
Baktha gave the keynote address at the RISC-V Summit 2023 conference today, and revealed some more of the speeds and feeds of the Veyron V2 chiplet complex and potential CPU designs that Ventana customers can create using its intellectual property and that of others.
The Veyron V2 core was designed for the 4 nanometer process from Taiwan Semiconductor Manufacturing Co, which is a shrink from the 5 nanometer processes that were the default design for the Veyron V1 chiplets we talked about earlier this year. The V2 core supports the RVA23 architecture profile, which has those 512-bit vector extensions as mandatory. There are also cryptographic functions that are run on the vector engines.
The V2 core from Ventana supports the RV64GC spec and implements a superscalar, out of order pipeline that can decode and dispatch up to 15 instructions per clock cycle. The V2 core can support Type 1 and Type 2 server virtualization hypervisors as well as nested virtualization thanks to its IOMMU design and Advanced Interrupt Architecture (AIA). The core also has ports for debug, trace, and performance monitoring. All of these are table stakes for a modern hyperscale datacenter server CPU. Neither the V1 nor the V2 cores have simultaneous hyperthreading, just like the Arm cores from Amazon Web Services and Ampere Computing do not and the future ‘Sierra Glen” cores used in the future “Sierra Forest” Xeon SP processors will not.
The Veyron V2 core has 512 KB of L1 instruction cache and 128 KB of L1 data cache plus a 1 MB L2 data cache. The cores have a 4 MB slice of L3 cache associated with them and across the 32 cores in the Veyron V2 chiplet complex, there is therefore 128 MB of cache. The cores on each chiplet are linked to each other using a proprietary coherent network on chip mesh interconnect that sports 5 TB/sec of aggregate bandwidth for the cores, memory, and other I/O. Four V2 chiplets can be interlinked with UCI-Express to create a 128 core complex, and if you really want to push the limits, you can link up to six chiplets together to get 192 cores in a single Veyron socket.
Here is what a V2-based CPU might look like conceptually with an I/O die and six 32-core V2 chiplets as well as some domain-specific accelerators linking in:
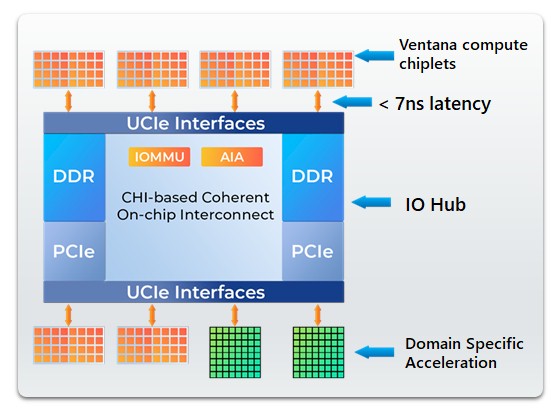
This diagram shows links off the I/O hub to PCI-Express 5.0 controllers and DDR5 memory controllers, but companies can swap in HBM3 memory controllers if that is what they want to do. The default design has twelve DDR5 memory controllers across six V2 chiplets or eight across four V2 chiplets, which is the same kind of balance we expect to see in any server CPU these days.
Here is how Ventana is simulating the integer performance of the Veyron V2 and in terms of raw SPECint2017rate throughout per socket:
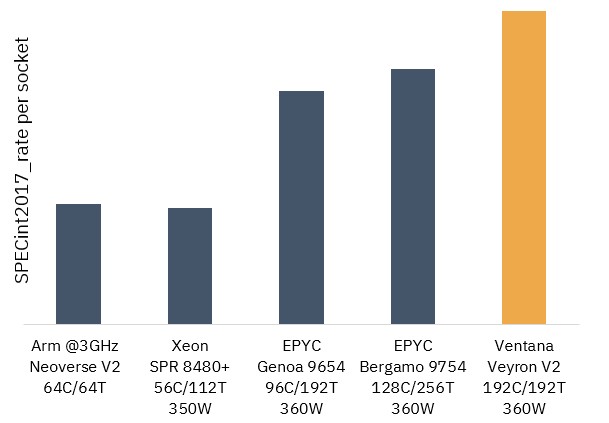
If you do the math on the chart above, a Veyron 2 RISC-V CPU with 192 cores will have about 23 percent more integer throughput than a “Bergamo” Epyc 9754 processor from AMD with 128 cores and 256 threads in the same 360 watt power envelope and will best a 96 core “Genoa” Epyc 9654 in the same 360 watt thermal envelope by around 34 percent. The performance gap with the 56-core “Sapphire Rapids” Xeon SP 8480+ is more like 2.7X in favor of the Veyron V2 chip, and that is not surprising in that it has 3.4X the cores and 1.7X the threads and despite the fact that the V2 core must be running at a lower clock speed. The Arm chip down looks to be a proxy for the AWS Graviton3, which with 64 cores has a tiny bit more performance than the Sapphire Rapids chip shown.
Ventana is offering a baseline Veyron V2 design with four chiplets for 128 cores and eight DDR5 memory channels with UCI-Express interconnects on the chiplets and an I/O hub to bring them all together inside of the server CPU socket. The Veyron V2 designs will be production ready in the third quarter of 2024, when the UCI-Express 1.1 PHY that is used to interconnect the chiplets is expected to be available.

Dell’s AI Server Business Now Bigger Than VMware Used To Be
We have been watching the big original equipment manufactures like a hawk to see how they are generating revenues and income from GPU-accelerated system sales. These OEMs provide the best indicator of the health of the GenAI revolution and the efforts to democratize the massively parallel – and massively expensive …

What Happens When Hyperscalers And Clouds Buy Most Servers And Storage?
We have a long-standing joke that dates from the early 2000s, when the hyperscalers – there were not yet cloud builders as we now know them – started having hundreds of millions of users and millions of servers and storage arrays to run applications for them at the same time …
Supermicro At 30: From Designing AI Chips To Selling AI Systems
There is something about late September. Nvidia was founded 30 years ago on Tuesday this week, Google was founded 25 years ago on Wednesday, and Supermicro was founded 30 years ago today. Three decades ago, Supermicro and its sister company, Ablecom, were both family affairs, as sometimes happens with startups. …
I’m not sure that I would see these Veyrons as general purpose datacenter processors, especially when compared to Ampere’s 192-core Siryn (available now?)[1] and Intel’s 288-core Sierra Forest (available 1H 2024)[2]. As suggested by the European Processor Initiative (EPI), I would be more inclined to view RISC-V CPUs as in-accelerator support devices, in systems where ARM (eg. Rhea1), x86, or POWER, remain as primary general purpose drivers. Esperanto’s 1,088 RISC-V core ET-SoC-1 [3], EPI’s 4,096 RISC-V core Manticore [4], and Tenstorrent’s upcoming dataflow chippery, essentially match that concept in my opinion, with more flexibility than pure GPUs.
[1] https://www.nextplatform.com/2023/05/18/ampere-gets-out-in-front-of-x86-with-192-core-siryn-ampereone/
[2] https://www.nextplatform.com/2023/09/19/intel-xeon-roadmap-on-track-288-core-sierra-forrest-coming-soon/
[3] https://www.nextplatform.com/2021/09/20/esperanto-chip-drives-ml-inference-performance-and-power-efficiency/
[4] https://www.european-processor-initiative.eu/dissemination-material/manticore-a-4096-core-risc-v-chiplet-architecture-for-ultra-efficient-floating-point-computing/
V2 Veyron IOMMU is Type 1+2 server virtual hypervisor very good for DC general CPU … plus bonus same ISA to RISC-V accel if you want! This tech more enthusiastic than OpenSPARC and OpenPOWER … voici voilà, non?
Looks like components for a real CPU to me.
Yes, you’re both right (I think)! Ventana’s engineering team sure did a great job enhancing RISC-V to make it credible, featurewise, for the datacenter with Veyron V2 (I like their work). What keeps me from fuller endorsement in the general purpose DC CPU space is the apparent lack of more workload-appropriate performance assessment. SPECInt gives a quite narrow perspective and there seems to be a dearth of any other benchmark ever being applied to RISC-V (I’m happy to be corrected if wrong here!). As a result, for datacenters, POWER10 (for example) is much more convincing with its SPECjbb results ( https://www.nextplatform.com/2022/09/07/ibm-power10-shreds-ice-lake-xeons-for-transaction-processing/ ), and so is EPYC (among others) ( https://www.nextplatform.com/2023/03/23/more-power-to-you-energy-efficiently/ ).
It could be just a matter of time until results of appropriate benchmarks are published for RISC-V DC chips (maybe there’ll be some at SC23?), but until then, being a sometimes dull-&-boring dude, almost as drab and tedious as some federal government, and at times sullenly bland and beige, I’ll reservedly curb my enthusiasm a bit on this (eh-eh-eh!). Hopefully Calista Redmond encourages RISC-Vers to broaden the benchmarking ecosystem for their artifacts.
When the pipeline is described as able to “decode and dispatch up to 15 instructions per clock cycle”, are these compressed (16-bit) instructions (the C profile of RISC-V, in RV64GC), or regular 32-bit ones (eg. with 8 of those potentially dispatched per clock)? Also, is the “512 KB of L1 instruction cache” on a per core basis, or on a per chiplet basis (32 cores) which would come out to a more normal 64 KB of L1 I-cache per core? “Inquisition minds” … (as François and others once said!).
If it is indeed fifteen 32-bit instructions per clock, and 512 KB of L1$I per core, then I wonder if they can hit the apparent sweet spot of 2.5 mm^2 per core (at 4nm) that Neoverse V2 gets (at 7 nm) and Zen 4c has (at 5 nm)? Or maybe it is more of an “out-there” design, like Microsoft’s “chiplet cloud”, that is not realistically designed for tape-out ( https://www.nextplatform.com/2023/07/12/microsofts-chiplet-cloud-to-bring-the-cost-of-llms-way-down/ )?
Fetch width is 16 bytes, so 8-wide decode only for 16-bit instructions, and 4-wide for 32-bit instructions. Rename is just 4 wide…
The cache is per core. So total 1.6MB cache plus 4MB L3, or 5.6MB per core. That’s even more cache than Genoa (5MB total cache per core). Graviton 3 has just 1.6MB per core.
However the real kicker is that in order to beat Genoa, Veyron V2 needs twice the number of cores and cache (and thus die size). The large die size and relatively low per-core performance makes it uncompetitive for cloud uses.
SiFive’s exit from the general purpose RISC-V CPU field, with layoff of its engineering team ( https://www.theregister.com/2023/10/25/riscv_champ_sifive_said_to/ ) just two months after the lacklustre Phoronix benchmark of its VisionFive 2 chip ( https://www.phoronix.com/review/visionfive2-riscv-benchmarks ), and two weeks before the RISC-V Summit North America 2023 (Nov.7-8), doesn’t really give confidence in that aspect of this architecture (as in Slim Albert’s first post above). Wrapping Ventana’s innovations around an OpenPOWER core, or focusing on RISC-V’s use within accelerators (or in IoT, or in hard drives, etc …) might be the winning pivot at this juncture.
They could also focus (pivot) on interfacing with quantum computers, in pre- and post-processing roles, replacing FPGAs there. It’s not a very large market at present but it is the future (more so than dataflow I think). The Quantum Approximate Optimization Algorithm (QAOA), for example, could really help solve graph-oriented problems more efficiently than more conventional recursive bounded search tree algos that involve substantial backtracking by necessity (to tackle McCarthy’s non-determinism) (eg. https://www.nextplatform.com/2023/09/21/beyond-the-traveling-salesman-escape-routes-get-a-quantum-overhaul/ ).
Seeing as this is the very first RISC-V article in many years that I see where not a single emotional enthusiasmatic proponent of the arch has commented with stilted blind enthusiasm, I think it can be unequivocally and conclusively determined that this arch is now finally completely and utterly dead, buried, and gone! Shalom, and RIP RISC-V! Folks of good computational faith should now get serious and start working on RISV-VI, or RISC-VJ (James Brown RISC machine!), the 2W3R arch that can actually perform well on dynamic language workloads (and graphs, and everything that matters really!)! As Cerebras’ Feldam almost said in his recent HPCWire interview: It’s high time to be “tossing your salad differently”! 8^p
Ah-ah-ah! Quite funny … I quite agree with your comment to TNP’s 05/18/23 piece on Meta’s Training and Inference Accelerator (MTIA) for DLRM, that has 64x(1-scalar + 1-vector) RISC-V cores on a PCIe board, with a huge fan ( https://www.nextplatform.com/2023/05/18/meta-platforms-crafts-homegrown-ai-inference-chip-ai-training-next/ )!
I just found that there’ll be some RISC-V HPC benchmark at SC23 Denver this Monday (Nov. 13), but the Author Abstract states “the x86 […] CPUs […] outperform the SG2042 by between four and eight times” ( https://sc23.conference-program.com/presentation/?id=ws_risc111&sess=sess455 ).
The paper for that SC23 presentation is available in open access ( https://arxiv.org/abs/2309.00381 ). Figures 4 and 6 compare the 64-core Sophon SG2042 (64x XuanTie C920 RISC-V cores with 128-bit vectors) to 4-core Sandybridge, 18-core Broadwell, 28-core Icelake, and 64-core Rome, in single-core and multi-threaded modes, respectively. It makes fine reading for a cloudy weekend!
Oooooooh. Interesting!
Performance aside, what about RISC-V Software Ecosystem? We’ve seen many good ARM-based designs in the past, but it took 10 years to (seriously) enter DC …and the struggle is not completely over yet…?
Having ported to Arm and Power, it is that much easier to port the Linux stack to RISC-V — so everyone tells me.