
There are two ways that CPU makers can deliver more bang for the buck, and those running distributed computing workloads can go either way – or somewhere in between – as they build out their server clusters.
The first is to push the process technology and architecture envelope to get a lot more performance into a given CPU socket. With the right kind of pricing, the performance rises faster than the cost generation to generation, and therefore the cost per unit of compute comes down and everyone is happy with better bang for the buck. Or, a CPU maker and its system builder customers can hang back, knowing that they will manage a fleet of similar machines, perhaps over six or seven years, and find a way to keep the performance per core about the same and ride each generation down lower and lower into the SKU stacks to get consistent performance at an ever-decreasing cost and therefore improve the bang for the buck that way.
We know HPC centers that do the latter, buying, for instance, servers with X86 cores that run in the 2 GHz or 2.5 GHz range and that deliver about the same performance on their simulation and modeling workloads regardless of CPU generation. As each generation has a little more IPC in the integer units, they sometimes do not see such improvements per clock for the vector units, so it all normalizes out on vector math if you keep the clock speeds in the same range. This makes it easier to manage a fleet of cores for vector math that are roughly the same in performance to drive a wide variety of workloads that are submitted to run on the cluster.
Fore those HPC shops that are looking for cheap cores, AMD has just announced six new models in its “Milan” Epyc 7003 series of X86 server processors, which offer the best bang for the buck in the AMD catalog these days for general purpose compute. In conjunction with these six new models, AMD has also told customers that it is going to keep making and selling Milan Epyc chips through 2026, so customers can feel confident that they can invest in machines based on these new Mila CPUs today and be able to expand their capacity in the next three years without having to change architecture.
The new Milan chips are not for everyone, of course, and are designed for those who are looking for the best price/performance, not the absolute best performance or lowest performance per watt that AMD can deliver in its now wide and deep CPU lineup. But if you are doing HPC on the cheap, you need to take a look at these new Milan CPUs. Take a gander:
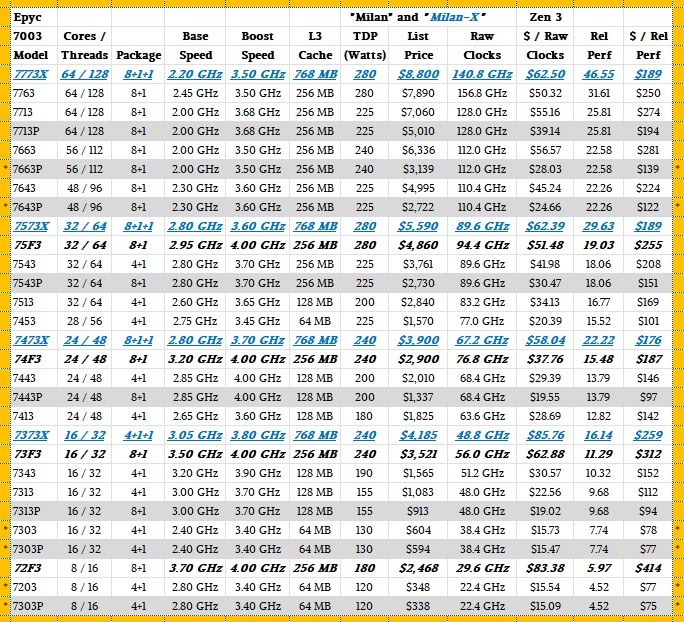
The table above shows all of the variants of the Milan family. The ones in bold blue underlined italics with Xs on the end of their names are those with 3D V-Cache. Those in bold black italics with an F at the end are the HPC boosting high frequency versions. Those on the gray bars with a P at the end are single socket only CPUs, which is an artificial distinction that AMD is making so it can charge less for a single-socket machine and more for a two-socket, NUMA shared memory machine. Those in plain old text are the plain vanilla SKUs in the Milan lineup. The six new Milan chips have an asterisk in the orange border on the left or right.
Four of the six new Milan CPUs are aimed at single-socket servers – the 56-core 7663P, the 48-core 7643P, the 16-core 7303P, and the 8-core 7203P – and the two remaining CPUs are plain vanilla ones with eight or 16 cores that can be used in single socket machines. As you can see from the table, all six of these chips offer the best bang for the buck in the Milan lineup, and when you count the aggregate clock speed throughput and adjust for IPC improvements across architectures, the cost per relative performance on integer workloads of these new Milan chips is the best in the history of the Epyc CPUs within their respective performance bands.
AMD is giving a strong signal that you really need to be thinking of a node as a single CPU. Which is not a new message from the datacenter CPU and now datacenter GPU and FPGA maker.
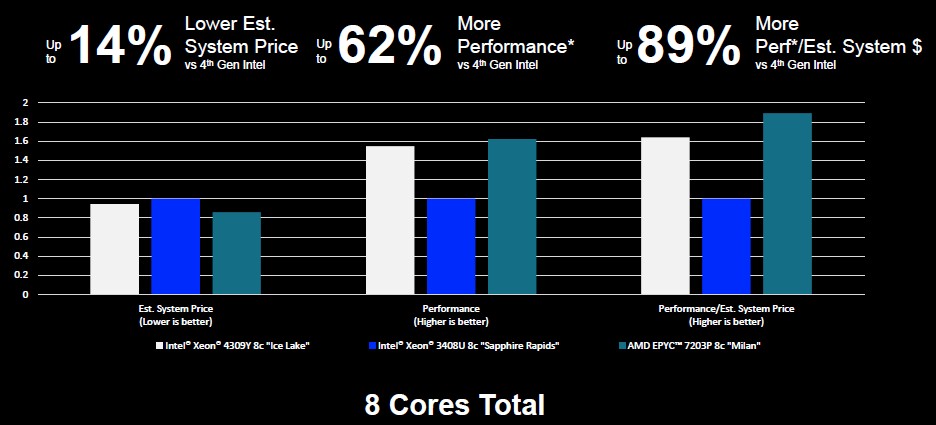
Here is how AMD does the math on relative system price, performance, and system price per performance for machines based on these new Milan chips versus comparable “Ice Lake” and “Sapphire Rapids” CPUs at the eight-core level:
And here are comparisons for machines with 8, 16, and 24 cores:
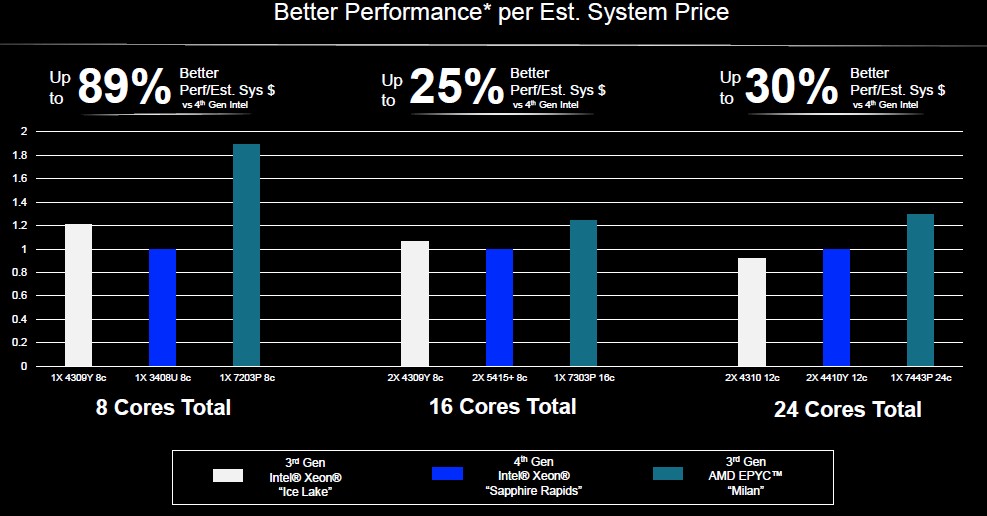
The 24-core AMD Epyc 7443P was already in the product lineup and was already pretty aggressively priced, although not to the degree that the CPUs with 16 and 8 cores are now.
Admittedly, the Milan Epycs use slower PCI-Express 4.0 peripherals and slower DDR4 memory than the faster peripherals and memory in the “Genoa” family of Epyc chips, which includes the Genoa Epyc 9004 series, the “Bergamo” 97X4 series, and the “Siena” Epyc 8004 series. But again, if you just want to load up on cheap CPU cores, these new Milans will do the trick.

Arm Neoverse Roadmap Brings CPU Designs, But No Big Fat GPU
Spoiler alert! A lot of neat things have just been added to the Arm Neoverse datacenter compute roadmap, but one of them is not a datacenter-class, discrete GPU accelerator. And another one that is also not there is a more specific matrix math accelerator like the ones that Intel (well …

Microsoft Azure Brings the Cache with Milan-X
Microsoft has been among the first to build and operationalize clusters based on AMD’s Milan-X processors, which were formally announced this morning. This is a big deal for HPC shops that have made the cloud leap, either for burst or production, as it means 3X the L3 cache of Milan, …

Throwing Down The Gauntlet To CPU Incumbents
The server processor market has gotten a lot more crowded in the past several years, which is great for customers and which has made it both better and tougher for those that are trying to compete with industry juggernaut Intel. And it looks like it is going to be getting …
Way to go! Milan’s Zen 3, DDR4, PCIe4, is Frontier-generation tech (Top500 #1 for a couple more days), hardly obsolete. Likely a great substrate for growing cost-effective “mini-Frontiers”, especially if MI210s eventually become more affordable as well (one can only hope!)!
In q3 Genoa volume grew 121% and $1K total channel inventory value +113% q/q and paid for AMD q3 Data Center and Gaming Division revenue combined. Back one Epyc generation into secondary market options the channel is focused pushing Milan and Rome designed to compete with _11 Sapphire Rapids and Ice respectively. CPU + Board combos are now widely available for Rome, Milan, Ice supporting VAR channels. In q3 Milan 48 and 32 cores cleared down significantly and for Rome sellers off are 48, 24 and 8 cores where the secondary market is all about known stable, sustainable, utility value and price performance. Intel Ice also traded down. Xeon Cascade Lakes and Skylake remain the primary Xeon trading markets on their large installed base.
Specific ‘cheap cores’ here’s server market sales trend for q3. Percent of all inventories plus supply and/or trade-in and sales trend. Cheap cores are highly demanded.
Sapphire Rapids Max = 0.00058% of total available listed here and flat
SR Platinum = 0.113% + 360%
SR Gold = 0.154% + 84%
SR Silver = 0.081% + 115%
SR XW34xx = 0.013% + 109%
SR XW24xx = 0.075% + 12%
Bergamo = 0.027% new entry
Genoa = 0.242% < 14.7%
Sienna = 0.014% new entry
TR5K = 0.078% < 14.4%
Ice Platinum = 0.274% < 20.9%
Ice Gold = 0.427% < 26.7%
Ice Silver = 0.228% < 25.7%
Ice W = 0.030% + 88.8%
Milan = 0.658% < 13.5%
TR3K = 0.164% < 5.9%
Copper Platinum = 0.031% + 21%
Cooper Gold = 0.010% + 63.6%
Cascade Lake Platinum = 1.275% < 12.9%
XCL Gold = 4.976% < 5.5%
XCLG refresh = 1.461% < 12.9%
XCL Silver = 1.647% < 15.1%
XSL Silver refresh = 0.605% < 14.1%
XCLB all up = 0.536% < 19.6%
XCL W32 = 0.166% < 35.1%
XCL W22 = 0.549% < 25.2%
Rome = 1.527% < 6.4%
TR2K = 0.059% < 7.4%
Skylake Platinum = 2.126% < 32.6%
XSL Gold = 13.18% < 21.2%
XSL Silver + Bronze = 3.739% < 34.4%
XSL W31/21 = 0.640% < 19.9%
E7 v4 8-way = 0.603% < 24.6%
E7 v4 4-way = 0.266% + 21.2%
E5 v4 4-way = 0.810% < 13.1%
E5 v4 2-way = 20.146% < 32.8%
E5 v4 uni = 1.067% < 5.3%
Naples = 0.746% + 9.1%
TR1K = 0.066% + 19.3%
E7 v3 8-way = 0.806% < 8.2%
E7 v3 4-way = 0.166% < 0.08%
E5 v3 4-way = 0.383% < 43.5%
E5 v3 2-way = 28.934% < 24.2%
E5 v3 uni = 1.616% < 7%
E7 v2 8-way = 0.120% < 60.2%
E7 v2 4-way = 0.311% < 21.4%
E7 v2 4-way = 0.034% < 1.8%
E5 v2 4-way = 0.579% < 30.9%
E5 v2 2-way all up = 8.104% < 27.2%
E5 v2 uni = 0.507% < 21.5%
6.25.23 to date WW channel server / workstation inventory clears down <22.8%.
Intel by product generation;
Sapphire Rapids all-inclusive WW channel available October 28 = 0.439%
Ice Lake = 0.961%
Copper Lake = 0.041%
Cascade Lakes = 10.82%
Skylake = 19.68%
Broadwell v4 = 22.89%
Haswell v3 = 31.90%
Ivy v2 = 9.65%
AMD by product generation;
Bergamo = 0.0275%
Sienna = 0.014%
Genoa = 0.241%
TR5K = 0.078%
All up = 0.3626%
Milan = 0.658%
TR3K = 0.164%
All up = 0.822%
Rome = 1.527%
TR2K = 0.059%
All up = 1.586%
Naples = 0.746%
TR1K = 0.066%
All up = 0.812%
The server market in q3 was ultimately all about secondary 'installed base' and 'price performance'.
Mike Bruzzone, Camp Marketing
“As each generation has a little more IPC in the integer units, they sometimes do not see such IPC improvements per clock, so it all normalizes out on vector math.”
Uh, what?
Yeah, that idea got all kinds of messed up. Here’s my do-over:
“As each generation has a little more IPC in the integer units, they sometimes do not see such improvements per clock for the vector units, so it all normalizes out on vector math if you keep the clock speeds in the same range. This makes it easier to manage a fleet of cores for vector math that are roughly the same in performance to drive a wide variety of workloads that are submitted to run on the cluster.”