

When you host the workhorse supercomputers of the National Science Foundation, you strive to provide the best possible solutions for your scientists. The Stampede and Frontera systems at the Texas Advanced Computing Center (TACC) at the University of Texas at Austin have been those workhorses. TACC continues to get National Science Foundation grants to expand computing capabilities for innovative and leading research.
Stampede, Stampede2, and Frontera – have been used for predictions of earthquakes and sea level rise, detecting gravitational waves, and millions of other simulations over the years. These supercomputers have been – and continue to be – built on the latest technologies from Intel, Dell, Nvidia, and leading network technology providers.
The most recent evolution of the TACC system, Stampede3, will integrate the latest generation of Intel CPUs and GPUs – the Intel Xeon CPU Max Series and Intel Data Center GPU Max Series – along with repurposing previous-generation Intel processors from Stampede2 and adding Cornelis Networks 400 Gb/sec Omni-Path fabric. Stampede3 will offer scientists a new level of computing capability for simulation and artificial intelligence they’ve not had before.
Stampede3 also gives TACC scientists an opportunity to test performance of several NSF-funded “characteristic science applications” on the new architecture. The applications reflect the broad range of science domains and computational approaches – from language to method to workflow – that researchers use. These applications were chosen by the community of large-scale scientific computing users to help “verify the design of the LCCF and validate that the facility is applicable across the broad range of science disciplines supported by the LCCF when it is constructed.”
TACC wanted to see how these codes would run on Stampede3’s architecture of Intel CPUs with high bandwidth memory (HBM). HBM has been one of the key ingredients in the rise of GPUs. It was also instrumental in the 2020 and 2021 Top500 #1 world ranking of the “Fugaku” supercomputer, which includes HBM-powered processors. The Intel Xeon CPU Max Series is the first x86 CPU to integrate HBM.
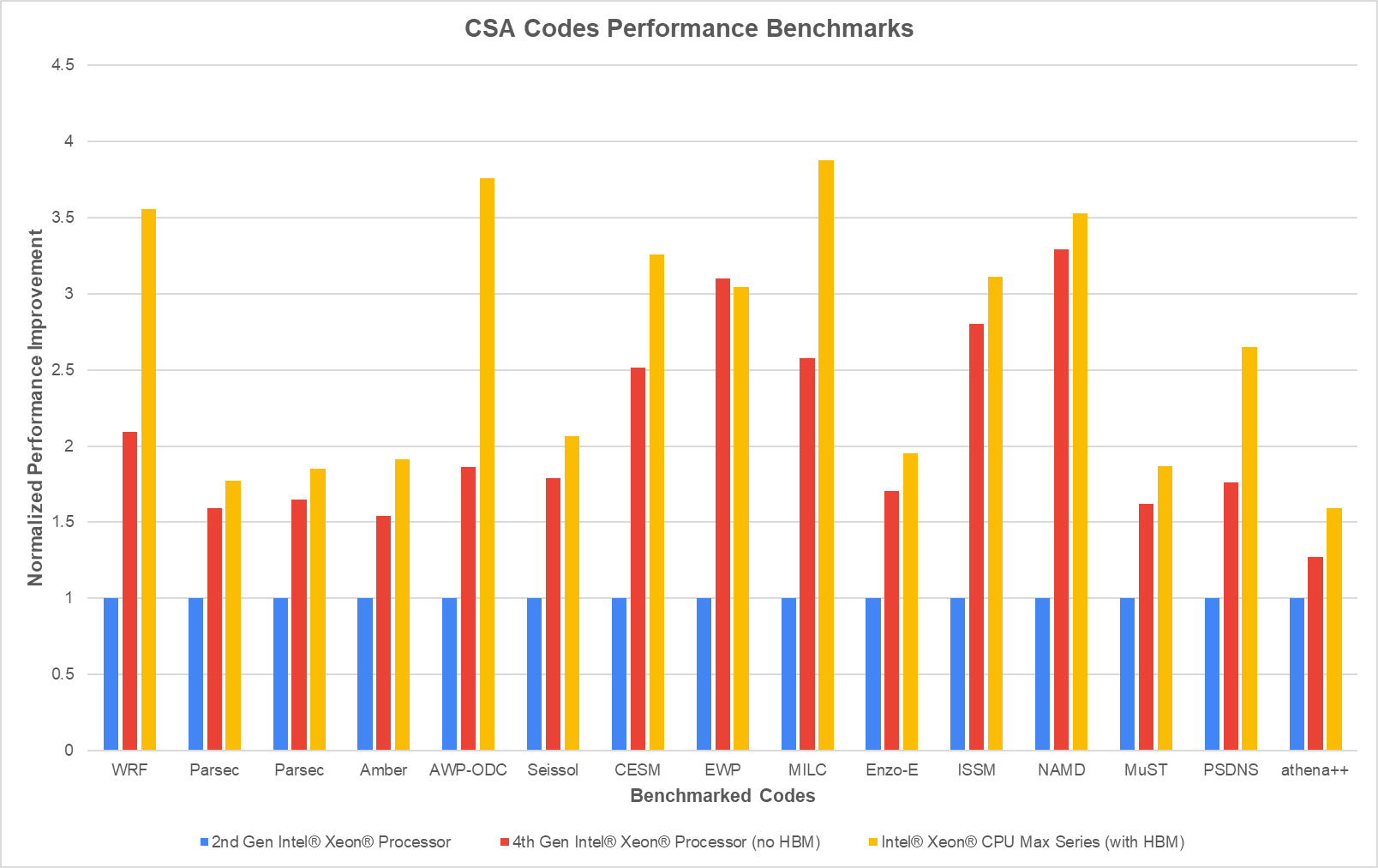
TACC researchers chose 13 of the CSA codes along with WRF, the Weather Research and Forecasting code (see the table below). These codes were benchmarked on both Stampede3 and Frontera, with its 2nd Gen Intel Xeon processors.
List of CSA and WRF codes for benchmarking on Stampede 3 and Frontera:
| Weather Research and Forecasting (WRF) | Mesoscale numerical weather prediction system. |
| Parsec1/2 | A package designed to perform electronic structure calculations of solids and molecules using density functional theory (DFT). |
| Amber | A suite of biomolecular simulation codes. It contains publicly available molecular mechanical force fields for the simulation of biomolecules and provides a package of molecular simulation programs. |
| Anelastic Wave Propagation, Olsen, Day, Cui (AWP-ODC) | Simulates wave propagation in a 3D viscoelastic or elastic solid. |
| Seissol | Code that simulates seismic wave phenomena and earthquake dynamics. |
| Community Earth System Model (CESM) | A fully coupled global climate model that simulates Earth’s past, present, and future climate states. |
| EWP | 3D deterministic wave propagation code |
| MIMD Lattice Computation (MILC) | Runs simulations of four dimensional SU(3) lattice gauge theory. |
| Enzo-E | Runs extreme scale numerical simulations to address current scientific questions in astrophysics and cosmology. |
| Ice Sheet and Sea Level System Model (ISSM) | Used to model the evolution of the polar ice caps in Greenland and Antarctica. |
| Nanoscale Molecular Dynamics (NAMD) | Simulates large biomolecular systems. |
| MuST | Code used to detect and report MPI errors |
| Parallel Spatial Direct Numerical Simulation (PSDNS) | Simulation approach used to compute spatially evolving disturbances associated with the laminar-to-turbulent transition in boundary-lay flows. |
| athena++ | An astrophysical magnetohydrodynamics code. |
The Intel Xeon CPU Max Series can run in an HBM-only mode and a flat mode where HBM can be turned off, relying only on DDR5. TACC tested the efficacy of the Intel Xeon CPU Max Series in both of these memory modes to understand the performance characteristics and benefits of HBM vs. DDR5. The Intel Xeon CPU Max Series delivered significant performance gains in both modes, especially for memory-bandwidth-bound applications.
Codes Run Up to 3.8SX Faster
Among the 14 applications that were assessed are software for large international experiments widely used codes from the earthquake and astrophysics communities, and custom codes that explore innovative approaches to machine learning and black hole modeling.
The codes performed well with DDR5 memory only and better with HBM on Stampede3 compared to the Frontera (see the chart). The codes performed 2x faster on average with DDR5 memory only. For massively parallel, data-hungry, and memory-bandwidth-limited problems, the codes achieved an average 2.6X speedup with HBM. And, more than a third of the codes saw 50 percent or more performance improvements using HBM compared to DDR5. Some codes saw up to 2X faster performance with the addition of HBM. MILC ran 3.8X faster than the previous version of the CPU.
“The new Intel Xeon CPU Max Series has exactly twice as many cores as the 2nd Gen Intel Xeon processor, so I expect it will be at least two times better,” said John Cazes, TACC Director of HPC. “With HBM, however, it’s 2.6X, so it’s a great multiplier. It’s got enough memory bandwidth that the cores on the Intel Xeon CPU Max Series cannot saturate the memory bandwidth that HBM provides. This is a very rare problem to have on a CPU.”
Faster. . . Climate Projections, Materials Discovered, Universes Modeled
The 14 codes cover weather, computer modeling, molecular dynamics, biomolecular simulation, astrophysics and cosmology, and other disciplines. Some performance highlights of the 14 applications include the following:
- The EarthWorks configuration of CESM was 2.5X faster with DDR5 than on Frontera; the code achieved a further 30 percent improvement (to 3.2X) in HBM-only mode.
- WRF saw 2.09X speedup with DDR5 compared to Frontera’s CPUs. With HBM, WRF ran 3.5X faster – a 70 percent speed-up over DDR5.
- The 3D earthquake code, Anelastic Wave Propagation (AWP) ran 3.7x faster on Intel Xeon CPU Max Series than on Frontera and showed a 100 percent boost with HBM.
The Community Earth System Model (CESM) is being developed by the NSF-sponsored EarthWorks project led by Colorado State University to study seasonal weather and climate phenomena at ultra-high resolutions. CESM is one of the principal climate codes used by the earth science community. The Weather Research and Forecasting Model (WRF) is designed for both atmospheric research and operational forecasting applications. The Anelastic Wave Propagation (AWP) code was developed by Yifeng Cui of the San Diego Supercomputer Center.
“Applying the power of new technologies will enable us to develop global storm-resolving models that will help us better understand the risks that come with climate change,” said Colorado State University professor David Randall, one of the developers of the EarthWorks configuration. “A 2.5X to 3X speedup means we can find answers faster or increase the resolution and accuracy of our models even further.”
No Code Changes Required
Porting codes is always a consideration when looking at new CPU and system architectures. The time and effort it takes to develop and optimize a code reduces cycles available for the scientific effort. For the TACC team, there were little to no code changes needed to port from Frontera Stampede3.
“Because we have the same system libraries, I could just lift the binaries that we ran on Frontera and run them on the Intel Xeon CPU Max Series and it just worked,” Cazes added.
Considering the thousands of codes and billions of lines of scientific software that scientists have already optimized for x86 processors, minimal to no code changes will mean getting to work much sooner. Early customers from Los Alamos National Laboratory and Numenta concurred. Adding to performance, the ease with which the codes can be taken from Frontera directly to the newest CPUs gives these researchers both faster results without the extra work.
“The use of accelerators and GPUs are definitely on the rise in HPC and AI, but it’s not clear that much of the advantage isn’t provided by high bandwidth memory,” said TACC director Dan Stanzione. “We need high performance CPUs too, and based on our benchmarks, the Intel Xeon CPU Max Series will provide clear advantages to our users.”
Ken Strandberg is a technical storyteller. He writes articles, white papers, seminars, web-based training, video and animation scripts, and technical marketing and interactive collateral for emerging technology companies, Fortune 100 enterprises, and multi-national corporations. Strandberg’s technology areas include Software, HPC, Industrial Technologies, Design Automation, Networking, Medical Technologies, Semiconductor, and Telecom. He can be reached at ken@catlowcommunications.com.


Stampede3: A Smaller HPC System That Will Get More Work Done
All of the major HPC centers of the world, whether they are funded by straight science or nuclear weapons management, have enough need and enough money to have two classes of supercomputers. They have a so-called capability-class machine, which stretches the performance envelope, and a capacity-class machine, which plays an …
Nvidia, AMD, And Intel Help Stuff The Coffers At Ayar Labs
Everybody wants to get rich in AI these days, and if you can’t do it by investing in the compute engine makers or the hyperscalers and cloud builders, then the next best thing to put your money into is probably some form of optical I/O. It is no secret that …
Finally: Some Good News For The Intel Xeon CPU Roadmap
It was a reasonable enough gut reaction given the many changes happening at Intel in recent months. The chip designer and maker – the last one in the world that does both – had announced a datacenter product line update for Wall Street analysts only a week after Raja Koduri, …
Interesting analysis! I wonder what underlying factors (maybe the way the model is coded? or how the memory needs to be accessed?) makes Anelastic Wave Propagation (AWP) 2x faster with HBM, while Empirical Wave Propagation (EWP) is slightly slowed down by HBM (in the bar charts), which is surprising.
Also, for folks keeping up with the German language (scary!) I’ll note that strand = beach, berg = mountain, and so Strandberg = beach mountain (best of both worlds!)! 8^b