
When it comes to funding rounds for high tech companies, the alphabet usually runs out somewhere around Series E. If you haven’t figured out who you are by then – or the market hasn’t – that probably means the you are going to be one of the 80 percent or so of companies that don’t make it and not one of the 20 percent that either cashes out in a sale to a bigger firm, to a venture capitalist, or through an initial public offering down on Wall Street.
If we had to make a bet – and we can’t because we don’t invest in the companies that we write about – we would bet that Vast Data, which has made flash storage and the NFS protocol work well and scale far and which has blurred the lines between storage and databases more recently, will not only be one of the 20 percent of startups that make it, but will be one of the blockbuster IPOs of 2024 – or perhaps 2025 if the global economy goes up on the rocks.
Modern high performance, scale-out workloads need a new kind of storage, one that can work well with HPC simulation and modeling as well as AI training, and that is what the Vast Data Platform, the most recent iteration of the storage created by Vast Data, is all about. And with Vast Data raising another $118 million in its Series E financing round, bringing the company to $381 million in total funding and giving it a valuation of $9.1 billion according to co-founder Jeff Denworth, up 2.5X in the past two years, Vast Data could be one of the breakout IPOs next year as it has already become a go-to storage platform for large scale infrastructure.
Lawrence Livermore National Laboratory was a big and early customer of Vast Data, and this is not surprising since some of the company’s founders were instrumental in the creation of the Lustre parallel file system that cut its teeth at this flagship US Department of Energy HPC center. Since then, the Texas Advanced Computing Center is employing Vast Data for a scratch file system on the “Stampede 3” supercomputer, and AI cloud builders CoreWeave, G42, and Lambda have also tapped Vast Data to provide the back-end storage for their GPU clusters.
This is in keeping with the philosophy that Denworth and co-founder Renen Hallack described to us way back in February 2019, when Vast Data dropped out of stealth, saying that unlike Nutanix, Pure Storage, and a bunch of prior storage startups, Vast Data was only going to focus on the needs of large-scale customers and chase big deals instead of lots of smaller ones because this was the fastest way to create and improve a product and to reach profitability. We look forward to seeing the S-1 filing that Vast Data makes when it goes public so we can see in its historical financial figures if this has truly played out as planned.
“We have a few dozen of the other clouds as customers, but that is not the totality of our business,” Denworth, who is now titleless after having the vice president of products and chief marketing officer roles and who is now simply called co-founder because he is wearing many hats, tells The Next Platform. (Michael Wing is already president of Vast Data, so that title is taken.) “We have a lot of enterprise customers coming in to buy big AI systems, but AI is definitely the tip of the spear and part of every selling motion.”
Denworth is not at liberty to say much capacity it has installed in the past four years, but he brackets it at somewhere between 10 exabytes and 20 exabytes, and adds that the business has more than tripled in the past year along with its valuation. The company has been a software-defined storage vendor for the past two years after starting out selling complete hardware and software appliances for the first two years of its corporate life. To date, it has sold more than $1 billion in cumulative Vast Data Platform software bookings, and has grown the company by 3.3X in the past twelve months and maintained positive cash flow during that time and gross margins of nearly 90 percent.
It sure looks like that “go big and go strong” strategy put together by Denworth and Hallack at the beginning has worked.
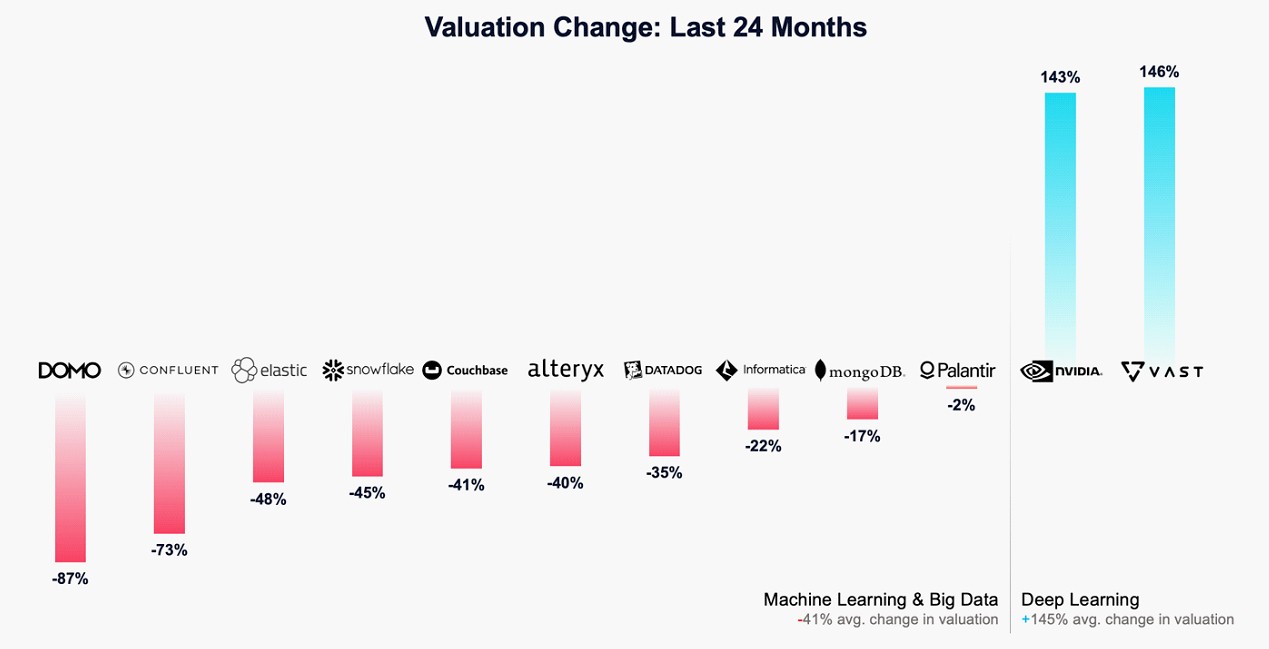
Denworth says there are only five AI companies worth at least $5 billion that have increased their valuation by 2X or more in 2023, and they are Anthropic, OpenAI, Nvidia, CoreWeave, and Vast Data. And this was an upround for Vast Data, which means with the funding the valuation of the company went up, not down, as many unicorns in Silicon Valley have done this year.
The funding round, it seems, was more about being able to call out a higher valuation then it was about trying to get some cash to spend. It was also a way to get Fidelity Management & Research Company, the investing arm of Fidelity Investments, on the board, which that company likes to do ahead of hot IPOs. New Enterprise Associates, BOND Capital, and Drive Capital also kicked in some dough on this round. By the way, Denworth says the Series B, Series C, and Series D money that Vast Data collected over the years is still sitting in the bank, collecting interest. So we really do want to see that S-1. . . .
While there is consensus of a sort for AI compute, there is not such a consensus for storage.
“The world that Nvidia wants you to live in is a world where you have to buy bespoke storage for your training or for your inference,” Denworth explains. “We want to live in a world where customers just bring AI to their data – not buying storage specific for AI is kind of the Holy Grail. Because then you just have different applications that run on the network. It’s fast enough down to your data infrastructure. We’ve got customers now with hundreds of petabytes of capacity, and they’re looking at how they can apply large language models against all this data. If they have to copy 200 petabytes into some sort of SuperPOD with local storage on the nodes, that’s wasteful. Think of it this way: If I have ten flash drives in my AI server, I have a certain amount of throughput that I can send into that machine. If I have got ten NICs on that machine, you have way more throughput on the network than you can from local SSDs.”
We have said it before, and we will say it again. At some point, we think that Vast Data will have to have a Vast Compute companion, with a Vast Network linking them. An IPO might just give Vast Data enough fuel to expand its mission and just change its name to Vast Systems. What Hallack told us back in August, when the database extensions of the Vast Data Platform were announced, bears repeating as we consider that possibility:
“Back in 2015, in my pitch deck, there was one slide about storage in that entire deck, which had maybe fifteen slides. One of them had storage in it, the rest of them had other parts that needed to be built in order for this AI revolution to really happen in the way that it should. Eight years ago, AI was cats in YouTube videos being identified as cats. It was not close to what it is today. But it was very clear that if anything big was going to happen in the IT sector over the next twenty years, it would be AI and we wanted to be a part of it. We wanted to lead it. We wanted to enable others to take part in this revolution that looked like it might be confined to a few very large organizations. And we didn’t like that. We want to democratize this technology.”
AI everywhere is probably better than AI in the hands of the Super 8 only. Now we get to find out.

AI Powerhouses Choose The Nuclear Option
When you need to provide electricity to power and cool 100,000 accelerators, or maybe even 1 million of them in a few years, in a single location to run an AI model, you have to start thinking about the unthinkable if you also want to use carbon-free juice to power …
After The 2022 Bump, Arista Is Back To The Grind In 2023
For Arista Networks, the poster-child of hyperscaler and cloud build networking that, more than any other vendor, has championed merchant silicon and Linux as the basis of a modular network operating system, 2022 was a bumper crop year. This year, there are many new things going on, but the compares …
An Architecture for Artificial Intelligence Storage
As we’ve talked about in the past, the focus on data – how much is being generated, where it’s being created, the tools needed to take advantage of it, the shortage of skilled talent to manage it, and so on – is rapidly changing the way enterprises are operating both …
I do wish Vast Data all the success in the world, especially seeing how they’ve reached Series E, suggesting that they’re pretty much ready for the big time. But I do also have a couple of mild “concerns” (if one might call them that).
In the “copy 200 petabytes” example, I’m not sure if Denworth is suggesting that “local storage on the node” is a bad thing, or mainly that it’s ok if one has “ten NICs on that machine” at the ready to handle the situation. This because LLNL’s Rabbit experiment (de Supinski) seems to find that “a baby dedicated flash array for a pod of El Capitan nodes”, “converged into a […] PCI-Express network”, as a kind of “disaggregated and converged” relatively local storage subsystem, is useful (TNP’s “ideas for exascale storage” piece). Both Denworth and de Supinski could be right of course, depending on specifics of the workload beeing executed, and the flexibility of the data transport system in terms of conduit-type management (PCIe/CXL, ethernet, infiniband, …) (I guess?).
Also, at some point, both Aurora’s DAOS (Intel’s Distributed Asynchronous Object Storage), and Vast’s Universal Storage, were going to rely on 3D XPoint and/or Optane for some aspect of their system’s architecture. It is not entirely clear what is now replacing that tech in Aurora and in Vast’s system (was there really a need for it in the first place?), and/or how these systems were re-architected (if at all) to make up for the discontinuation of these products.
Irrespective though, yes, as Goldstone puts it (3rd link: “Blazing the trail”) “VAST Data […] uses the standard NFS client that’s part of Linux [and] on the backend […] It’s a scale out architecture [with] lots of innovative features” … in other words a winning product. Well done (IMHO)!