


The generative AI revolution is making strange bedfellows, as revolutions and emerging monopolies that capitalize on them, often do.
The Ultra Ethernet Consortium was formed in July 2023 to take on Nvidia’s InfiniBand high performance interconnect, which has quickly and quite profitably become the de facto standard for linking GPU accelerated nodes to each other. And now the Ultra Accelerator Link consortium is forming from many of the same companies to take on Nvidia’s NVLink protocol and NVLink Switch (sometimes called NVSwitch) memory fabric for linking GPUs into shared memory clusters inside of a server node and across multiple nodes in a pod.
Without a question, the $6.9 billion acquisition of Mellanox Technologies, which was announced in March 2019 and which closed in April 2020, was a watershed event for Nvidia, and it has paid for itself about three times over since Mellanox was brought onto the Nvidia books.
The networking business at Nvidia was largely driven by Quantum InfiniBand switching sales, with occasional high volume sales of Spectrum Ethernet switching products to a few hyperscalers and cloud builders. And that Ethernet business and experience with InfiniBand has given Nvidia the means to build a better Ethernet, the first iteration of which is called Spectrum X, to counter the efforts of the Ultra Ethernet Consortium, which seeks to build a low-latency, lossless variant of Ethernet that has all of the goodies of congestion control and dynamic routing of InfiniBand (implemented in unique ways) with the much broader and flatter scale of Ethernet, with a stated goal of eventually supporting more than 1 million compute engine endpoints in a single cluster with few levels of networking and respectable performance.
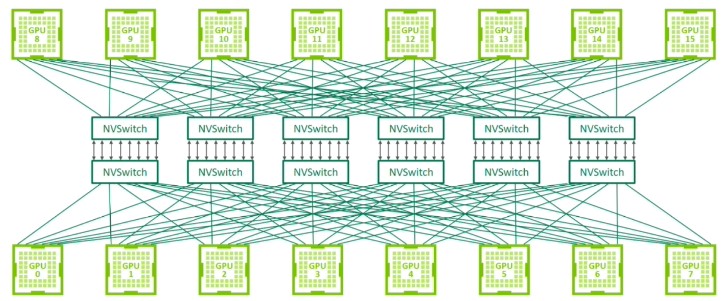
NVLink started out as a way to gang up the memories on Nvidia GPU cards, and eventually Nvidia Research implemented a switch to drive those ports, allowing Nvidia to link more than two GPUs in a barbell topology or four GPUs in a crisscrossed square topology commonly used for decades to create two-socket and four-socket servers based on CPUs. Several years ago, AI systems needed eight or sixteen GPUs sharing their memory to make the programming easier and the datasets accessible to those GPUs at memory speeds, not network speeds. And so the NVSwitch that was in the labs was quickly commercialized in 2018 on the DGX-2 platform based on “Volta” V100 GPU accelerators.
We discussed the history of NVLink and NVSwitch in detail back in March 2023 a year after the “Hopper” H100 GPUs launched and when the DGX H100 SuperPOD systems, which could in theory scale to 256 GPUs in a single GPU shared memory footprint, debuted. Suffice it to say, NVLink and its NVLink Switch fabric have turned out to be as strategic as to Nvidia’s datacenter business as InfiniBand is and as Ethernet will likely become. And many of the same companies that were behind the Ultra Ethernet Consortium effort to agree to a common set of augmentations for Ethernet to take on InfiniBand are now getting together to form the Ultra Accelerator Link, or UALink, consortium to take on NVLink and NVSwitch and provide a more open shared memory accelerator interconnect that is supported on multiple technologies and is available from multiple vendors.
The kernel of the Ultra Accelerator Link consortium was planted last December when CPU and GPU maker AMD and PCI-Express switch maker Broadcom said that the xGMI and Infinity Fabric protocols used to link its Instinct GPU memories to each other and also to the memories of CPU hosts using the load/store memory semantics of NUMA links for CPUs would be supported on future PCI-Express switches from Broadcom. We had heard that it would be a future “Atlas 4” switch that adheres to the PCI-Express 7.0 specification, which would be ready for market in 2025. Jas Tremblay, vice president and general manager of the Data Center Solutions Group at Broadcom, confirms that this effort is still underway, but don’t jump to the wrong conclusion. Do not assume that PCI-Express will be the only UALink transport, or that xGMI will be the only protocol.
AMD is contributing the much broader Infinity Fabric shared memory protocol as well as the more limited and GPU-specific xGMI, to the UALink effort, and all of the other players are agreeing to use Infinity Fabric as the standard protocol for accelerator interconnects. Sachin Katti, senior vice president and general manager of the Network and Edge Group at Intel, said that the Ultra Accelerator Link “promoter group” that is comprised of AMD, Broadcom, Cisco Systems, Google, Hewlett Packard Enterprise, Intel, Meta Platforms, and Microsoft is looking at using the Layer 1 transport level of Ethernet with Infinity Fabric on top as a way to glue GPU memories into a giant shared space akin to NUMA on CPUs.
Here is the concept of creating the UALink GPU and accelerator pods:
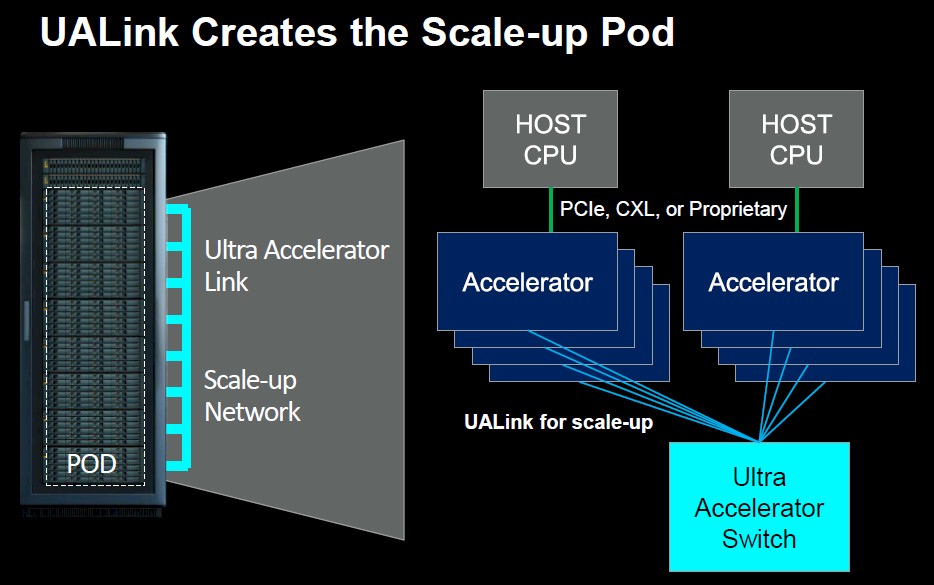
And here is how you use Ethernet to link the pods into larger clusters:

No one is expecting to link GPUs from multiple vendors inside one chassis or maybe even one rack or one pod of multiple racks. But what the UALink consortium members do believe is that system makers will create machines that use UALink and allow accelerators from many players to be put into these machines as customers build out their pods. You could have one pod with AMD GPUs, one pod with Intel GPUs, and another pod with some custom accelerators from any number of other players. It allows commonality of server designs at the interconnect level, just like the Open Accelerator Module (OAM) spec put out by Meta Platforms and Microsoft allows commonality of accelerator sockets on system boards.
Wherefore Art Thou CXL?
We know what you are thinking: Were we not already promised this same kind of functionality with the Compute Express Link (CXL) protocol running atop of PCI-Express fabrics? Doesn’t the CXLmem subset already offer the sharing of memory between CPUs and GPUs? Yes, it does. But PCI-Express and CXL are much broader transports and protocols. Katti says that the memory domain for pods of AI accelerators is much larger than the memory domains for CPU clusters, which as we know scale from 2 to 4 to sometimes 8 to very rarely 16 compute engines. GPU pods for AI accelerators scale to hundreds of compute engines, and need to scale to thousands, many believe. And unlike CPU NUMA clustering, GPU clusters in general and those running AI workloads in particular are more forgiving when it comes to memory latency, Katti tells The Next Platform.
So don’t expect to see UALinks lashing together CPUs, but there is no reason to believe that future CXL links won’t eventually be a standard way for CPUs to share memory – perhaps even across different architectures. (Stranger things have happened.)
This is really about breaking the hold that NVLink has when it comes to memory semantics across interconnect fabrics. Anything Nvidia does with NVLink and NVSwitch, its several competitors need to have a credible alternative – whether they are selling GPUs or other kinds of accelerators or whole systems – for prospective customers – who most definitely want more open and cheaper alternatives to the Nvidia interconnect for AI server nodes and rackscale pods of gear.
‘When we look at the needs of AI systems across datacenters, one of the things that’s very, very clear is the AI models continue to grow massively,” says Forrest Norrod, general manager of the Data Center Solutions group at AMD. “Everyone can see this means that for the most advanced models that many accelerators need to work together in concert for either inference or training. And being able to scale those accelerators is going to be critically important for driving the efficiency, the performance, and the economics of large scale systems going out into the future. There are several different aspects of scaling out, but one of the things that all of the promoters of Ultra Accelerator Link feel very strongly about is that the industry needs an open standard that can be moved forward very quickly, an open standard that allows multiple companies to add value to the overall ecosystem. And one that allows innovation to proceed at a rapid clip unfettered by any single company.”
That means you, Nvidia. But, to your credit, you invested in InfiniBand and you created NVSwitch with absolutely obese network bandwidth to do NUMA clustering for GPUs. And did it because PCI-Express switches are still limited in terms of aggregate bandwidth.
Here’s the funny bit. The UALink 1.0 specification will be done in the third quarter of this year, and that is also when the Ultra Accelerator Consortium will be incorporated to hold the intellectual property and drive the UALink standards. That UALink 1.0 specification will provide a means to connect up to 1,024 accelerators into a shared memory pod. In Q4 of this year, a UALink 1.1 update will come out that pushes up scale and performance even further. It is not clear what transports will be supported by the 1.0 and 1.1 UALink specs, or which ones will support PCI-Express or Ethernet transports.
NVSwitch 3 fabrics using NVLink 4 ports could in theory span up to 256 GPUs in a shared memory pod, but only eight GPUs were supported in commercial products from Nvidia. With NVSwitch 4 and NVLink 5 ports, Nvidia can in theory support a pod spanning up to 576 GPUs but in practice commercial support is only being offered on machines with up to 72 GPUs in the DGX B200 NVL72 system.