

The companies under the control of Elon Musk – SpaceX, Tesla, xAI, and X (formerly known as Twitter) – all need a hell of a lot of GPUs, and all for their own specific AI or HPC projects. And the trouble is, there just are not enough GPUs to satisfy their respective ambitions. And so Musk has to prioritize where the GPUs will go that he can get his hands on.
Back in 2015, Musk was a co-founder of OpenAI, and after a power struggle in 2018, which we think had as much to do about the massive investments needed to drive AI models as it did over governance of those AI models, Musk left OpenAI and opened the door for Microsoft to walk in with its big bags of money. Seeing how OpenAI had become the leading force in production-grade generative AI, Musk quickly formed xAI in March 2023, and since that time that startup has been scrambling to raise money and find GPU allocations to build competitive infrastructure to take on OpenAI/Microsoft, Google, Amazon Web Services, Anthropic, and others.
Getting the money was the easy part.
At the end of May, Andreessen Horowitz, Sequoia Capital, Fidelity Management, Lightspeed Venture Partners, Tribe Capital, Valor Equity Partners, Vy Capital, and Kingdom Holding (a Saudi royal family holding company) all kicked in $6 billion of Series B funding for xAI, bringing its total haul to $6.4 billion. That is a good start, and luckily Musk has a $45 billion pay package coming from Tesla, so he can sweeten the xAI GPU pot any time he wants to. (He might be wise to save some of that money for GPU allocations for Tesla, X, and SpaceX.)
In a way, Tesla is going to pay Musk in a lump salary all of the $44 billion it took for him to acquire X back in April 2022, with an extra $1 billion to boot. That’s a 24,000 GPU cluster right there as spare change. To be fair, Tesla has shaken up the car industry, and had $96.8 billion in sales in 2023 with $15 billion of that dropping down as net income, with $29.1 billion in cash. But even in this New Guilded Age, that is a ridiculous pay package. But, Musk has big things to do, and he has a board that is willing to sacrifice Tesla’s cash and then some to make him happy.
Still, using the same logic, we would like to do a takeover of JPMorgan Chase for $650 billion, with money borrowed from Bank of America, Abu Dhabi, the Federal Reserve, and anywhere else we can find it, and take out a salary next year that is a teeny weeny bit larger than the acquisition cost – $675 billion ought to do it. And then we can change its name to TPMorgan Caught, and have $25 billion left over to play with after we pay back the loans. . . . .
But we digress. Frequently, and with enthusiasm.
That brings us to the vast computing, storage, and networking needs of xAI. The Grok-0 large language model, which spans 33 billion parameters, was trained in August 2023 a few weeks after xAI was founded. Grok-1, with a conversational AI for prompting and spanning 314 billion parameters, was available in November 2023 and that model was open sourced in March 2024, shortly before the Grok-1.5 model came out, with a larger context window and a better grade point average across cognitive tests than Grok-1.

As you can see, Grok-1.5 is a little bit less smart than the competition from Google, OpenAI, and Anthropic.
The upcoming Grok-2 model, which was set to be trained on 24,000 Nvidia H100 GPUs and which was reportedly being trained on cloudy infrastructure from Oracle, is due in August. (Oracle has already inked a deal with OpenAI to have it soak up any GPU capacity not used by xAI.)
Musk has said in various tweets that Grok 3 will come out by the end of the year and would require a cluster of 100,000 Nvidia H100 GPUs to be trained, and would be on par with the future GPT-5 model that OpenAI and Microsoft are working on. Oracle and xAI were trying to work out a deal for GPU capacity, and when a rumored $10 billion deal for GPU clusters with Oracle fell apart three weeks ago, Musk quickly shifted gears to build a “Gigafactory of Compute” in an old Electrolux factory on the southside of Memphis, Tennessee to house his own cluster with 100,000 GPUs. If you live in Memphis, things are gonna get a little bit crazy, because xAI wants to get 150 megawatts of power allocated to it.
The current factory, according to a report in Bloomberg, has 8 megawatts allocated to it and that can be raised to maybe 50 megawatts over the next several months. To go beyond that is going to require a whole lot of paperwork from the Tennessee Valley Authority.
By the way, if you have a massive supercomputer in Memphis, there is no way in hell you can nickname it anything other than something relating to Elvis Presley. And you can go through the different Elvis phases as you name successive machines over the future years. You might want to call this one “Hound Dog” from the early rock ‘n roll phase of The King. Although if Musk can’t get the full 100,000 H100 allocations by December, which seems unlikely unless Nvidia wants to be helpful, it might be called “Heartbreak Hotel.” (It is nicknamed “Colossus, alas.)
Last week, while we were away on a family medical emergency (we have had our share of those lately), Musk xitted this out:
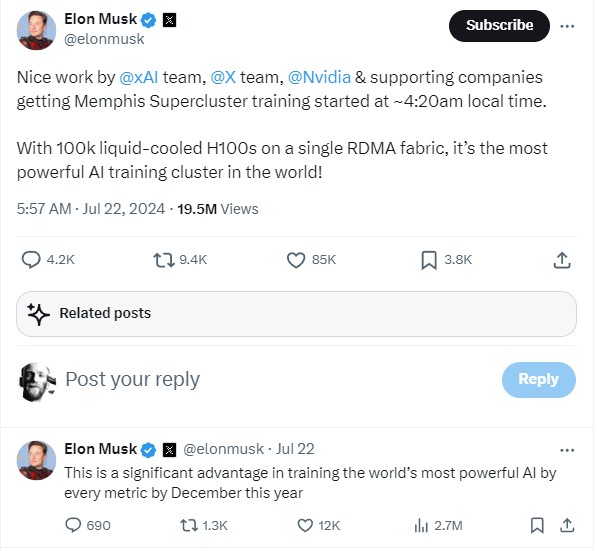
So maybe it will be called the SuperCluster, which is the same term that Meta Platforms used when it bought rather than built its own AI training machine. (We like “Hound Dog” a lot better.)
We think that 100,000 GPU count is an aspiration, and maybe xAI will only have 25,000 GPUs by December, in which case it will still be able to train a very large model. Some reports we have seen suggest that the Memphis SuperCluster won’t be fully extended until later in 2025, and we think this is likely.
We can infer from the xitts from Supermicro founder and chief executive officer, Charles Liang, that Supermicro is building the water-cooled machines that xAI is deploying in the Memphis datacenter:

There are no specifics about the server infrastructure, but we strongly suspect that this machine will be based on eight-way HGX GPU boards and will be Supermicro’s rackscale systems, inspired by Nvidia’s SuperPOD setups but with its own engineering tweaks and lower prices to be sure. Using eight-way HGX boards, that that works out to 12,500 nodes in total with 100,000 GPUs and 100,000 endpoints in the backend network and 12,500 endpoints in the front-end network that is used to access data in the cluster and to manage the nodes.
Rami Rahim, chief executive officer at Juniper Networks, also piped up about being involved with the Memphis SuperCluster:

If you just saw those tweets, you might jump to the conclusion that Juniper had somehow won the networking deal for the Memphis SuperCluster, which would be truly surprising given the hard push that both Arista Networks and Nvidia themselves have done in AI cluster networks. We have not seen anything from Arista about this system, or Cisco Systems for that matter, but on May 22, when Nvidia was going over its first quarter of fiscal 2025 financial results, chief financial officer Colette Kress had this to say:
“In the first quarter, we started shipping our new Spectrum-X Ethernet networking solution optimized for AI from the ground up. It includes our Spectrum-4 switch, BlueField-3 DPU, and new software technologies to overcome the challenges of AI on Ethernet to deliver 1.6X higher networking performance for AI processing compared with traditional Ethernet.
Spectrum-X is ramping in volume with multiple customers, including a massive 100,000 GPU cluster. Spectrum-X opens a brand-new market to Nvidia networking and enables Ethernet-only datacenters to accommodate large scale AI. We expect Spectrum-X to jump to a multibillion dollar product line within a year.”
Let’s face it, there are not that many 100,000 GPU deals in the works in the world at any given time, and we are pretty certain that Nvidia was talking about the Memphis SuperCluster in its statements back in May now that we see what Musk has said about the system. So we think Nvidia has the back-end (or east-west) network part of the deal with Spectrum-X gear, and Juniper has the front-end (or north-south) network. And Arista has said nadda.
We haven’t seen anything about what kind of storage the Memphis SuperCluster will use. It could be raw storage arrays based on a mix of flash and disk from Supermicro running any number of file systems, or it could be all-flash arrays from Vast Data or Pure Storage. If you put a gun to our heads, we would venture that Vast Data is involved with this deal for a big chunk of the storage, but that is just a guess based on the traction that the company has seen with large storage arrays in both HPC and AI over the past two years.

Nvidia Unifies AI Compute With “Ampere” GPU
The in-person GPU Technical Conference held annually in San Jose may have been canceled in March thanks to the coronavirus pandemic, but behind the scenes Nvidia kept on pace with the rollout of its much-awaited “Ampere” GA100 GPU, which is finally being unveiled today. All of the feeds and speeds …

The Faster The Switch, The Cheaper Bit Flits
It may have taken a while for the transition to 200 Gb/sec and 400 Gb/sec networking to take off in the datacenter, but this higher gear to switching is finally kicking in and delivering unprecedented bang for the buck in networks, and in fairly short order at least compared to …

The Iron That Will Drive AI At Meta Platforms
If there is one thing that is consistently true about HPC clusters for the past thirty years and for AI training systems for the past decade, it is as workloads grow, the network becomes increasingly important – and perhaps as important as packing as much flops in a node as …
I wonder did Musk’s publicist have any challenges taking that lede pic? Since Musk was so busy building the cluster with his own hands.
Sounds like Cisco is not in the picture
Well, I think I have to blame this one on Chef Nvidiaardee’s savant promotion of its gastronomic Testosterooni AI product that ubiquitously made its way into the canteens of hyperscalers the world over. It all started innocently enough with a gently proposed kitchen cage fight between Mark and Elon, where Brazilian Jiu-Jitsu cooking techniques would combine with eloquent dinner rethoric, to unquestionably determine who best concentrated the savory hormone … and turned into this unfortunate affair of “my AI dish is bigger than yours”.
And so it came to pass that once Mark had proposed cooking up TWO Open Compute Project Grand Teton (GT) soufflés, each with 24,576 cans of H100 GPU testosteroonis, which is already twice overstuffed in AI cheesy goodness when compared to the Top500’s MS Azure Eagle’s 10,752, Elon had to retort by baking his own extravagant pièce montée, filled to the brim with 100,000 of the GPU croquembouches (tastefully composed by award winning SuperMicro pâtissiers). The end? No!
The TNP cookbook gastronomy archives, and the Register’s SIGGRAPH recipe report, tell us that Mark has enough testosteroonis to grill, fry, bake, or steam, as many as twenty overstuffed GT soufflés, and is readying its utensils to serve some 600,000 cans of this yummy GPU-flavored dish ( https://www.nextplatform.com/2024/03/13/inside-the-massive-gpu-buildout-at-meta-platforms/ , https://www.theregister.com/2024/07/30/meta_personal_ai/ )! Just how will Elon respond to this blatantly elevated culinary throwing of the kitchen oven gauntlet? 8^b
(yes: Inquisition minds want to know!)
What we would ever do without you?
I remember datapack, ethernet, gigabit ethernet, 10 gigabit ethernet, 100 gigabit ethernet now spectrum ethernet.
Cons soon there will be AI Juniper porn – x ethernet in every american home. Cluster of 100 000 us black holes of bullshit. IPO $ 100 billion dogecoins mined by xAI.What have happened to blockchains, 5G, ITlol…. Wall street cojones and gypsies alway on the hunt for the new con.Ponzi bitcoin ETF, printing toilet paper, sending rockets to sombrero galaxy and tokenization of world assets it is what is left in tge con land.
Here in Memphis Musk is moving fast. Musk needs TVA power and gray water to cool the super computer. TVA wants supercomputer to cut back on power when the grid is at capacity and is willing to share gray water plant with Musk. Sounds like a go to me.
Xlnt article
Among all of these…… I suggest one name to engage …. that is Manish Shah (+1 437 375 9849) …. This Man has potential to Empower Elon Musk 10x…100x times…. Beyond Imagination … His thoughts are completely out of the Box…. Both Manis n Elon must come together…! Hopefully we will see them working together and change the complete scenario for Good….!
And today the 100k H100 cluster was supposedly completed…