



Big Blue might be a little late to the AI acceleration game, but it has a captive audience in its System z mainframe and Power Systems servers. Many of these customers, who spend millions of dollars for their application and database servers, will want a more native approach to AI inference and training. Which is why IBM has a chance to make a little hardware money among its systems base despite the overwhelming dominance of Nvidia GPUs and its AI Enterprise software stack in the market at large.
At the Hot Chips 2024 conference, Chris Berry, distinguished engineer in charge of microprocessor design at IBM, walked through the AI acceleration that will be embedded in the next generation of mainframe processors, codenamed “Telum II” and presumably to be marketed as the z17, following the “Telum” processor that was unveiled at Hot Chips 2021 and was known as the z16. Berry disclosed some of the details about the Telum II chip, including its on-die DPU, and also revealed that IBM is indeed going to commercialize the AI Acceleration Unit, or AIU, which was developed by IBM Research over the years and which we talked about in detail back in October 2022.
At the time, we also admonished Big Blue, saying that the AIU had better not be a science project. . . and apparently it is not and will be commercialized as an AI acceleration card for the System z17 mainframes when they ship next year. Known as the Spyre accelerator now, the second generation of the AIU will provide a lot more oomph for larger AI models than can be supported on the on-chip AI units in the Telum and Telum II processors, and still allow for AI acceleration to be within the security perimeter of the PCI-Express bus on the mainframe, which is something that mainframe shops worry about.
The maniacal focus on security stands to reason, given the workloads that mainframes have been doing for decades. Big Blue estimates that 70 percent of all financial transactions on Earth – at banks, trading houses, insurance companies, healthcare companies, and so forth – go through a mainframe.
There are reasons for this, and one of them is not that mainframes are inexpensive. They are most certainly not. But they are almost indestructible and extremely stable high I/O systems that can run at 98 percent to 99 percent utilization in a sustained fashion and deliver 99.999999 percent uptime. (That is one hour of unplanned downtime every 11,400 years.) Moreover, these customers have homegrown applications, usually written in COBOL but more often these days in Java, and they want to use code assistants like the one IBM has created for its Watson.x AI platform and run it on the mainframe and keep the AI model weights and resulting applications created on the mainframe – again for security reasons. There is no offloading core banking software or the AI models that drive it to the cloud.
The Telum II z17 Processor
The Telum II processor has 43 billion transistors and like the Telum chip, it has eight very fat cores to do the card walloping processing that is common in the back office systems that represented the first wave of computing in the datacenter. The Telum z16 processor had 22.5 billion transistors in 530 mm2 and was implemented in Samsung’s 7 nanometer processes. With the Telum II, IBM is nearly doubling the transistor count to 43 billion and boosting the chip area to 600 mm2 thanks to a shrink to Samsung’s 5 nanometer processes (5HPP, to be precise). A lot of those extra transistors are going to beefier L2 caches, but some of it is allocated to the on-chip DPU as well as to a more capacious on-chip AI accelerator, which is a segment of circuits derived from the AIU, we expect.

The DPU is in the middle on the left side, and has some dead area in the chip because, as Berry put it, the DPU design came in “a little smaller” than IBM expected. To our eye, it only takes up the space of 1.6 cores instead of the two cores that IBM planned for. And it looks like IBM figured out that it could sacrifice two z17 cores and trade them for an integrated DPU for accelerating and streamlining I/O and boost the overall effective performance of the compute complex even as the number of cores remained the same and the clock speed was only boosted by about 10 percent compared to the z16 cores to 5.5 GHz. Thanks to IPC and other improvements, the per-socket performance rose by 20 percent compared to the z16.
As with the z16, the z17 has done away with the L3 and L4 caches that were commonly used in earlier System z processors, and chunks of the L2 cache can present itself as a shared L3 or L4 cache as software requires. It looks like a chunk of the increased transistor count that is going into the Telum II processor is going into the caches. The Telum II has ten L2 caches, with each weighing in at 36 MB each, compared to eight 32 MB caches in the original Telum chip from two years ago.
The Telum II has 360 MB of virtual L3 cache, up 50 percent from the 240 MB virtual L3 cache on the Telum chip. The 2.88 GB of virtual L4 cache on Telum II is 40 percent larger than the L4 cache on the first-gen Telum chip. The virtual L4 cache presumably is a partition of the DDR5 main memory in the system, which is 16 TB maximum across a four-socket drawer with two Telum II chips per socket. (That is a 60 percent increase in main memory capacity compared to the z16 drawers.) This main memory implements the OpenCAPI Memory Interface, just like the z16 and Power10 processors did. Presumably it will use DDR5 memory chips as was just announced as an upgrade for the Power10 processors, not the DDR4 memory used in the z16 and originally in the Power10 systems.
The z16 and z17 systems expand from one to four drawers, which encompasses 16 sockets, 32 chiplets, and 256 cores, with 64 TB of main memory. The systems also have 192 PCI-Express 5.0 slots, which are encased in a dozen I/O expansion drawers that have 16 slots each. (These slots are where you plug in disk drives, flash drives, cryptographic processors, or Spyre accelerator cards for AI.)
The Data Processing Unit Comes Full Circle
“Mainframes handle massive amounts of data,” Berry explained in his presentation at Hot Chips. “One fully configured IBM z16 is able to process 25 billion encrypted transactions each and every day. That’s more encrypted transactions per day than Google searches, Facebook posts and tweets combined. That kind of scale requires I/O capabilities way beyond what typical compute systems can deliver. It requires custom I/O protocols to minimize latency, support virtualization for thousands of operating system instances, and can handle tens of thousands of outstanding I/O requests at any point in time.”
“So we decided to leverage a DPU for implementing those custom I/O protocols, and given all the communication between the processor and the I/O subsystem, instead of just connecting the DPU behind the PCI bus, we decided to put the DPU directly on the processor chip. We coherently connected it into the processor SMP fabric and gave it its own L2 cache by putting the DPU on the processor side of the PCI interface and enabling coherent communication of the DPU with the main processors running the main enterprise workloads. We minimize the communication latency and improve performance and power efficiency, realizing more than 70 percent power reduction for I/O management across the system.”
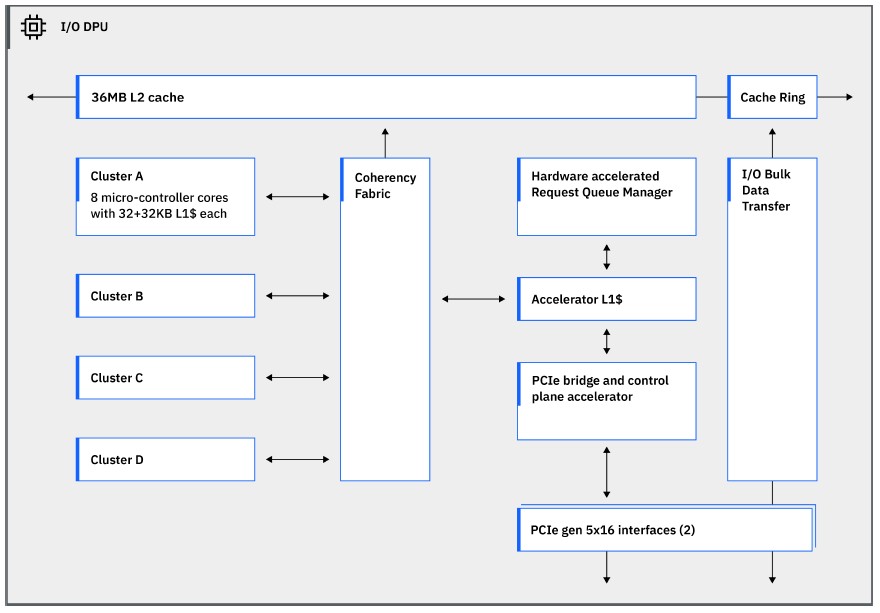
The Telum II DPU has four clusters of four cores each, with every core having 32 KB of L1 data cache and 32 KB of L1 instruction cache each. No details were given for these cores, but they could be IBM’s own Power cores – perhaps lightweight ones – or Arm cores. (We think the former rather than the latter.) The DPU connects to one of the 36 MB L2 cache segments, which means there is a spare 36 MB L2 cache that is not attached to any specific core or the DPU. The DPU has a pair of PCI-Express 5.0 x16 interfaces, which link out to the pair of PCI-Express 5.0 controllers that are also on the Telum II die and that link out to those I/O expansion drawers.
The on chip AI accelerator is on the lower left of the chip and has about the same area as one of the z17 cores, but it is flattened out. We presume the architecture is an improved version of the AI accelerator that was embedded in the same location on the first gen Telum chip. Berry says that IBM added INT8 data types to the existing FP16 supported in the first gen AI accelerator for the Telum chip, and also allows for the on-chip AI accelerators to be shared across all of the Telum II chips in a z17 system across the XBus and Abus NUMA interconnects that are also implemented on the dies to create the shared memory system.
The on-chip AI accelerator on Telum II has 24 teraops per second (TOPS) of performance; we do not have ratings for the Telum AI accelerator from three years ago. Customers now have access to 192 TOPS per z17 drawer and 768 TOPS across a full z17 system.
But it doesn’t end there. Now that Spyre is being commercialized, customers can load up Spyre accelerators in those I/O drawers and bring even more AI oomph to bear.
The Widening Spyre
The Spyre chip is implemented in Samsung’s low power variant of its 5 nanometer process (5LPE), and has 26 billion transistors in 330 mm2 of area.
The original AIU that IBM did as a research project and that we talked about two years ago had 32 cores that were very similar to the AI accelerator in the Telum processor, with 32 of them exposed as usable for yield purposes, all implemented in Samsung 5 nanometer processes with 23 million transistors. Spyre seems to be a tweaked version of this AIU chip, with 32 cores and 2 MB of scratchpad memory on each core.
Here is the block diagram of the Spyre core:

There is a 32 byte bidirectional ring that connects the 32 cores – well, we think 34 cores, with only 32 active – on the Spyre chip, and a separate 128 byte ring connects the scratchpad memories affiliated with the cores. The cores support INT4, INT8, FP8, and FP16 data types.
Here is what the Spyre accelerator card looks like:

The Spyre card has 128 GB of LPDDR5 memory implemented in eight banks – a lot more than the 48 GB implemented on the original AIU – and delivers more than 300 TOPS (presumably at FP16 resolution) within a 75 watt envelope. The Spyre card plugs into a PCI-Express 5.0 x16 slot. The LPDDR5 memory connects to the scratchpad memory ring and delivers 200 GB/sec of memory bandwidth into that ring.
If you gang up eight of the Spyre cards in an I/O drawer, which is the maximum that IBM recommends, you create a virtual Spyre card that has 1 TB of memory and 1.6 TB/sec of memory bandwidth on which to run AI models, with an aggregate of more than 3 petaops of performance (presumably at FP16 resolution). With ten such drawers, you are talking about 10 TB of memory and 16 TB/sec of aggregate bandwidth across 30 petaops of AI oomph.

This is absolutely enough for IBM mainframe shops to do some pretty serious AI within their applications and databases and within the security perimeter of the “main frame” of the z17 complex.
The Spyre card will ship next year, presumably when the z17 mainframe also ships. Berry did not provide precise dates, but did say that it is in tech preview now, which means select customers can get their hands on it now.
One last thing. There is absolutely nothing about the accelerator in the Telum II processor or in the Spyre accelerator that ties it specifically to the IBM System z mainframe. And in fact, the same approach of making the programming tools and compilers see both the on-chip AI accelerator and the external Spyre accelerator look like native instructions for the z17 processor could be done with, for instance, IBM’s future Power11 processors, also due next year.
And while we are thinking about it, why wasn’t IBM’s Power11 processor unveiled at Hot Chips 2024 this week? Given its delivery next year, we would have expected for some revelations about Power11 at this conference, as has been tradition. Perhaps we will hear more at the ISSCC 2025 conference early next year, with Power11 chips expected to roll out around the middle of next year.