
UPDATED With its Graviton 4 homegrown Graviton 4 Arm server processors, Amazon Web Services has put into the field a CPU that can compete with all but the toppest of bin parts from AMD for X86 CPUs and Ampere Computing and Nvidia for Arm CPUs, and it is driving price/performance that will in turn drive their adoption for Amazon’s various business units and for its IT infrastructure rental customers on AWS.
And now, the Graviton 4 processors are getting a memory boost, which in turn will allow them to take on more jobs that are bound by memory capacity and memory bandwidth.
The Graviton 4 processors were launched in November 2023, and are based on the “Demeter” Neoverse V2 core from Arm Ltd. There are lots of things we don’t know about the Graviton 4 processor, shown in the feature image at the top of this story, and we have tried to piece together what is known and fill in the blanks to give a more complete picture of how this Arm CPU stacks up to its predecessors and rival X86 and Arm chips in the datacenter. Take a gander:

As you can see, the Annapurna Labs division of AWS, which creates its “Nitro” DPUs as well as its Graviton CPUs, its “Trainium” AI training XPUs, and its “Inferentia” AI inference XPUs, has come a long way in its balancing act of pushing up to the state of the art in design and pushing down in terms of making these chips affordable and still profitable for AWS.
Note: Items marked in bold red italics in the table above are estimates from The Next Platform.
The Graviton 4 chip has faster cores, better cores, and more cores than its Graviton 3 predecessor, and for the first time AWS is creating two-socket NUMA memory clustering to bring 192 cores running at 2.8 GHz to bear on workloads. The original Graviton 4 chips were equipped with 1.5 TB of DDR5 main memory running at 5.6 GHz, and with the Graviton 3 using 4.8 GHz DDR5 memory and having only eight memory channels compared to a dozen for the Graviton 4, the latter chip gets a 50 percent capacity and bandwidth boost from those extra channels and a 16.7 additional boost from the faster DDR5 memory. Add it up, you get 537.6 GB/sec of bandwidth per Graviton 4 socket, which is as good as any other X86 or Arm CPU can deliver and which is sufficient for many HPC workloads that are stuck on CPUs and cannot be easily ported to GPUs.
The Graviton 4 R8g instances were generally available back in early July, and we covered them in detail at that time. They span from 1 to 96 vCPUs and from 8 GB to 768 GB per Graviton 4 socket; there is a sliding scale of network bandwidth up to 40 Gb/sec per instance and Elastic Block Storage (EBS) also scales up to 30 Gb/sec per socket.
As we said back in July, we think that the two-socket Graviton 4 instance is a special case given that there is only 50 Gb/sec of networking bandwidth and 40 Gb/sec of EBS bandwidth for the two socket machine. Moreover, there is no instance size that has between 96 and 192 cores, which you would expect there to be if all the physical machines that Amazon was building based on Graviton 4 were using two-socket motherboards. Or, maybe it just wants to sell fully populated machines once customer cross the NUMA barrier.
Here is how the new X8g memory-boosted instances that debuted today stack up against the existing R8g instances that came out in July:

When we went to press, AWS had not yet announced pricing on the memory-enfattened Graviton 4 instances, and as you know, we are impatient about such things.
And so, we took a look at Graviton 3 instances with different memory capacities – the base R7g and the double-boosted memory of the M7g Graviton 3s, to be precise – and calculated the memory different and the price difference. And it works out that it costs $0.0031875 per 8 GB per hour for the incremental memory running at 4.8 GHz. And so we took that number, uplifted it by the increase in memory speed used for the Graviton 4 instances (which was 16.7 percent more performance at 5.6 GHz) and then calculated the on demand rental costs for the X8g instances in the table above. As you can well imagine, that extra memory capacity is not free, but we think this is a logical way to estimate what AWS might charge for the X8g instances. If you scale up the memory on the R8g instances to the size of the X8g instances using such memory pricing – all of the other features of these machines are the same – then you find that the price would be 50.5 percent higher to rent the X8g instances than for the R8g instances.
If we were AWS, this is what we would do.
Subsequent to this story running, AWS put out on demand pricing for the X8g instances, and they are actually are signifiantly higher than we thought, up 65.9 percent higher than the R8g instance prices.
And here is how the various top bin configurations of the Graviton processors have stacked up since the Graviton 1 made its debut back in November 2018:
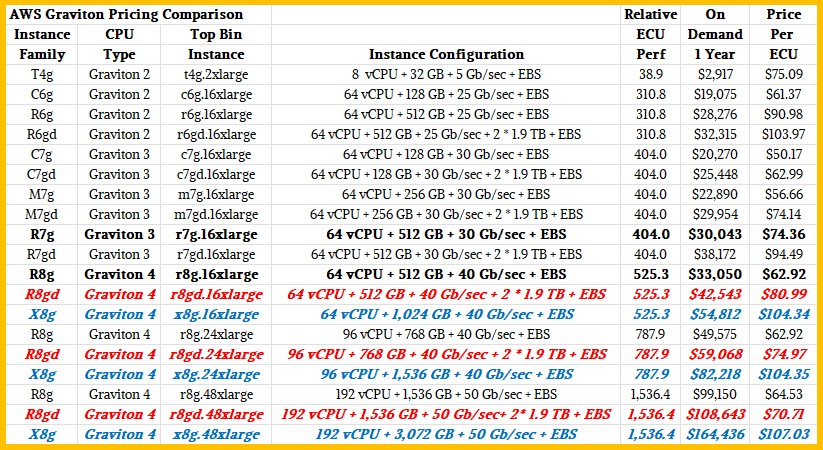
Back in July, we estimated what the annual on demand rental cost would be for regular Graviton 4 instances with local flash storage in the nodes, which is shown in the bold red italics. We are not trying to suggest that this is how customers will buy these instances, but we do want to show that these hourly charges “sure do mount up,” as actor Charlie Sheen once famously quipped in awkward testimony at trial.
In the bold blue italics, we are showing the annual on demand rental costs that we estimated for the new top bin X8g instances. The idea is that the fat memory is not free, and you have to have a need to use the X8g instances. And, based on what AWS is saying, we think lots of customers using prior Graviton 2 and Graviton 3 instances will be taking a hard look at the memory-enhanced Graviton 4 instances. Applications that could not be run on Graviton 2 and Graviton 3 processors – certain memory-intensive HPC applications and in-memory analytics and databases come to mind – will not be able to be run on Graviton 4 instances.
One interesting use case for the fat memory Graviton 4 processors is – you guessed it – designing future Graviton CPUs by Annapurna Labs. And just for fun, Jeff Barr, chief evangelist for AWS (a kind of PR manager), published this chart in the blog post announcing the memory-enhanced Graviton 4 chips:

This chart shows the number of Graviton instances that were fired up at AWS itself as it designed the I/O die and the compute dies for the Graviton 4 package. There is a an initial baseline of just under 2,000 instances that is humming along, with daily and weekly spikes that range as high as 2X this base level of compute. As the designs progress for the I/O die and the compute die towards tape out, virtual test and design verification gets more and more intense, and the baseline approaches more like 4,000 instances concurrently running with spikes up to 8,000 and sometimes as high as 11,000 concurrent instances if you squint at this chart.
As you can see, the Graviton 4 I/O die taped out in Q4 2022 and the compute die taped out in Q1 2023, which is a fun bit of information that AWS revealed.
What AWS did not say, however, is how the extra memory of the X8g would boost EDA performance or cut back on the number of instances that were being run.
As far as we know, EDA is really a one-core, one job kind of embarrassingly parallel workload, so the number of cores you throw at a job is analogous to the number of scenarios and configurations you can test in the possible design space. The peaks above, for instance, “represent several hundred thousand cores running concurrently,” according to Barr. Also as far as we know, EDA software is licensed by the core, so having faster cores – as the Graviton 4 cores most certainly are thanks to the Demeter V2 design – means you can get jobs done faster, and having more cores per socket means you can get more jobs done per instance. And this is how you have money and time on EDA work.
It would be interesting to see how Graviton 4 instances were able to speed up the design of Graviton 6 processors. . . . and maybe AWS should provide a case study on this. We would be happy to research and write it.
For a lot of HPC customers who are using the Graviton 2 X2gd instances, the Graviton 4 has twice the L2 cache per core (2 MB compared to 1 MB, with 2.6X the memory bandwidth and 60 percent higher compute performance per core. The X8g instances also have 3X the memory capacity and 3X the number of cores and 2X the EBS bandwidth and 2X the Ethernet bandwidth, too. All of which will help chip designers get more EDA work done quicker, presumably at a lower cost per unit of work.

Dell’s AI Server Business Now Bigger Than VMware Used To Be
We have been watching the big original equipment manufactures like a hawk to see how they are generating revenues and income from GPU-accelerated system sales. These OEMs provide the best indicator of the health of the GenAI revolution and the efforts to democratize the massively parallel – and massively expensive …

The Year Ahead In Datacenter Compute
For more than a decade, the pace of the server market was set by the rollout of Intel’s Xeon processors each year. To be sure, Intel did not always roll out new chips like clockwork, on a predictable and more or less annual cadence as the big datacenter operators like. …

AMD Finally Breaks The 10 Percent Server Share Barrier
History doesn’t really repeat itself, but it surely does use a lot of synonyms and rhymes, and sometimes, if you listen very closely, you can catch it muttering to itself. It is with this in mind that we contemplate the recent data coming out of Mercury Research, which is the …
My tests put a 4-core Gravitation 4 VM about 20 percent faster than a 4-core Graviton 3 VM. A 4-core 4-thread Epyc 9R14 VM is right in the middle between the Graviton 3 and 4 in performance. Of course, all of this depends on the type of computation.
The memory increase is super, but the on demand price increase is too much IMHO. It would be more reasonable and appealing to put the X8g_medium at $0.07583 (tops) in my view.
It is bigger than is justified, as I think I showed without intending to do that. Precisely.