
Generative AI is still very much an emerging technology and it’s morphing and evolving rapidly, as is illustrated with the trend toward agentic AI, which we’ve written about previously. But enterprise adoption is ramping quickly and organizations are moving from testing out the technology to applying it to various use cases.
Jeremy Foster, senior vice president and general manager of Cisco Compute, saw that at a recent meeting of the IT vendor’s Customer Advisory Board, where almost all of the companies said they had AI projects underway to one degree or another.
“Some of those projects might be starting in the cloud and some of those projects might be starting in projects on-prem, but we’re seeing that process accelerate over the last six months or more from where it was and we think it’s just going to continue to go faster,” Foster told The Next Platform. “Some of them made initial orders and they are waiting on delivery. Between the order and delivery, they’re defining their use cases and how they’re going to develop those applications to deliver value. It’s still very early in the enterprise, but it’s not one or two organizations of ten, it’s eight or nine. When they get there, it’s all going to come very, very fast.”
One challenge they’ll have to contend with is ensuring they have the right infrastructure to run AI workloads. According to Cisco’s AI Readiness Index, 89 percent of IT professionals surveyed said they plan to deploy AI workloads within the next two years, but only 14 percent said their infrastructure is ready for the jobs. Overhauling infrastructure can be a costly and complex proposition.
Cisco is looking to make that transition easier and cheaper with new hardware offerings announced this week at its Partner Summit in Los Angeles that pull from its UCS portfolio and validated design initiatives, which put as much of the technology needed into converged and highly integrated systems. Such offerings are important to enterprises that are weighing what AI tasks they want to do in the cloud and on premises.

“We are seeing a lot of preference for being able to deploy things on-prem and the infrastructure patterns depend on what you’re going to do,” Daniel McGinniss, vice president of product management for Cisco Compute, told The Next Platform. “Maybe you’re training as an enterprise in the cloud and then you go on-prem. People have a lot of data on-prem and that’s got a lot of gravity. If a lot of these applications are important to them, are their crown jewels, then they’ll want to run them on-prem. That will lead to what we’re seeing, which is all the use cases around all this coming together and taking the guesswork out, because all of those infrastructure patterns are different. I will do inferencing on a CPU but I won’t be doing training on a CPU. Some of our large enterprise customers are doing that training in the cloud or maybe they’ll be doing that training on-prem.”
At the event, Cisco unveiled the UCS C885A M8 servers, aimed at large GPU-intensive AI training and inferencing jobs. It’s the latest edition to the UCS portfolio, which Cisco first introduced in 2009 as it expanded its datacenter presence beyond networking to compete with the likes of Dell and Hewlett Packard in compute.

The UCS C885A M8 is built atop Nvidia’s HGX supercomputing platform and is powered by eight Nvidia H100 or H200 Tensor Core GPUs or eight AMD MI300X OAM GPUs – support for Intel chips is expected later – and includes a Nvidia ConnectX-7 network interface card (NIC) or BlueField-3 SuperNIC for each GPU, allowing for AI model training workloads to run across a cluster of the servers. There also are Nvidia BlueField-3 data processing units (DPUs) and comes with two 4th or 5th Gen EPYC chips from AMD.
The systems are managed via Cisco’s Intersight cloud-based platform.
At the same time, Cisco announced its AI PODs, which extend the vendor’s validated designs – which Cisco has been offering for more than two decades – with pre-configured infrastructure stacks for AI inferencing workloads that can scale from edge deployments to large-scale clusters to retrieval-augmented generation (RAG).
The AI PODs are based in large part on Nvidia technology, including its GPUs and AI Enterprise software platform and HPC-X toolkit, as well as Cisco’s UCS X-Series modular design, chassis, M7 compute nodes, a PCI-Express node with Nvidia GPUs, Cisco UCS fabric interconnects, and Intersight management software.
It also includes Red Hat’s OpenShift application platform and the ability to choose between Nutanix, NetApp’s FlexPod or Pure Storage’s FlashStack.
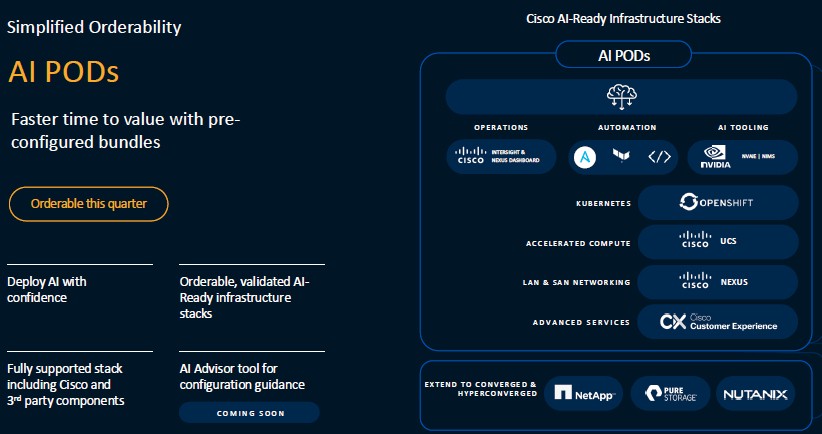
Such a technology stack can be benefit to organizations still trying to get their heads around the complex infrastructure environment needed for AI, according to Cisco’s McGinnis.
“People have been doing virtualized environments for decades,” he said. “In the beginning, that was confusing, too. Now we’re seeing the same thing. It’s almost history repeating itself. The concept of a stack is really reassuring to a customer in that they don’t know what they don’t know yet. They don’t know how to size their environment yet and they don’t understand this combination of CPUs and memory and drives and GPUs. It’s a whole new vector that needs to be considered. There’s a confidence when we can say, ‘We’ve already done the sizing for you. Here’s this entire stack for where you need to get started.’ They will customize it and deviate as they learn more about their needs and their environments, but the concept of a of a solution is probably very important.”
The UCS C885A M8 servers – which can be ordered now and will ship by the end of the years – and AI PODs (orderable in November) are joining a growing portfolio of AI infrastructure from Cisco, which includes 800G Nexus switching platforms running on the Cisco Silicon One G200 chip and the Nexus HyperFabric AI clusters developed with Nvidia and introduced in June and which combine Cisco’s AI networking with Nvidia’s accelerated computing and AI Enterprise software and a data store from VAST.
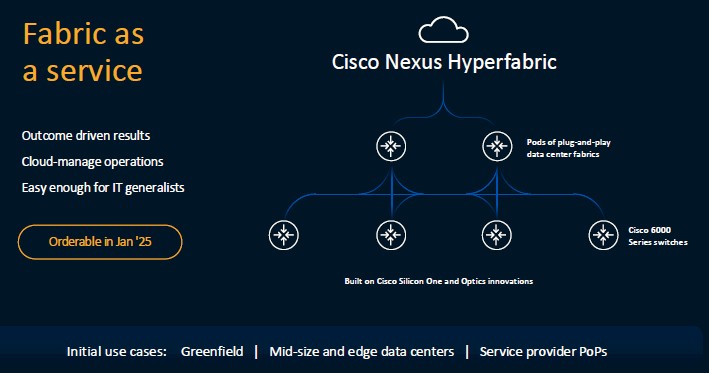
Cisco’s Foster said Nexus HyperFabric AI clusters, which will be orderable next year, allow enterprises to quickly get the necessary AI network in place.
“If you think about training two networks, you’ve got the frontend network and backend network,” he said. “We collapse that together one Ethernet network and allow them to manage them all the way from the network down to the NIC on the back of the server and then we leverage Intersight to keep that server environment up and running and optimized based on the requirements of their use cases.”

Micas Takes On Arista And The Whiteboxes In Datacenter Switching
The rise of the merchant silicon suppliers for datacenter networking and routing, which was spearheaded by Broadcom with chips and Arista Networks with switches, was not a foregone conclusion. It took decades for Cisco Systems and Juniper Networks to get complacent, leaving open the opportunity for cheaper and more capable …
Controlling The Network When You Don’t Own All Of It
Like others in the datacenter infrastructure space, Cisco Systems has had a front-row seat to the rapid changes in enterprise tech, from the accelerating adoption of the multicloud model to the increasing decentralization of the IT environment, rippling out to the network edge. And Cisco and other vendors in the …

The Citadel That Is Still Cisco Systems
The hyperscalers and cloud builders can be split into two camps, but a third one might be emerging. There are those who do not buy routers or switches from Cisco Systems, one of the early innovators in routing in the late 1980s – when a router was a funky kind …
Be the first to comment