


If you want to buy an exascale-class supercomputer, or a portion of one so you can scale up, there are not a lot of places to go shopping because there are not a lot of companies who have a balance sheet that is big enough to get all of the parts to build the machines.
The cut-throat nature of pricing in the HPC sector also limits your choices, as we have lamented over the years. It is very difficult to make a profit on the very large machines that represent a substantial portion of the revenue stream in the HPC area. And yet, because someone has to build these HPC systems, dozens of companies hang in there and do the work. (Bow.)
In the United States, Europe, and sometimes Japan and South America and the Middle East, you have Hewlett Packard Enterprise, which brings together the heritages of Cray, Silicon Graphics, Convex, Compaq, and HP. In Europe, South American, Africa, and sometimes Asia, you have the Eviden division of Atos, which has its heritage in Groupe Bull with a twinge of IBM and NEC if you look back far enough. Fujitsu has a presence in Japan, obviously, and also has some footing in Europe thanks to its merger with the IT division of Siemens many years ago. Lenovo, which spans China and the United States has a presence in Europe thanks to long-standing relationships IBM built with supercomputer centers before selling off its System x server division to Lenovo a decade ago. China has indigenous labs that work with local vendors like Inspur and Sugon to put together machines. Dell obviously does a lot of business outside of the exascale upper echelon, too, and did not have to acquire a Cray or SGI to be the number two supplier of on premises HPC machines worldwide. And if you are a hyperscaler or cloud builder, Supermicro is happy to build a big machine for you, as are the big ODMs like Quanta, Foxconn, and Invensys.
Here is how Hyperion Research carved up the on premises HPC server market for 2023, including a revision that brought in HPC machines made by Supermicro and other non-traditional suppliers:
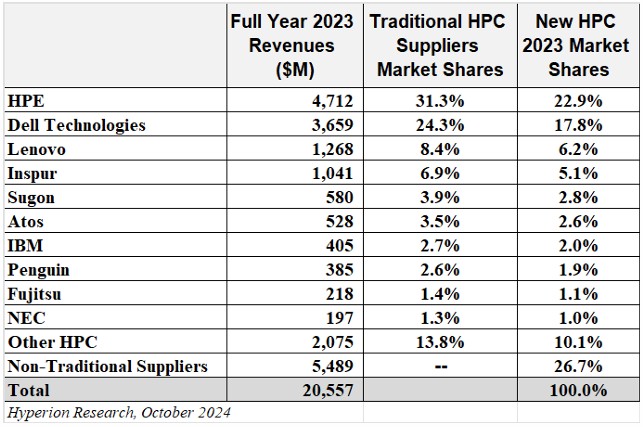
Those non-traditional suppliers, who are by and large building “AI supercomputers,” as a group have a little more than a quarter of the market, and HPE has the dominant market share at just a little under a quarter – thanks in large part to the massive deals taken down by Cray to build pre-exascale systems in the United States and Europe and exascale machines in the United States.
If you want to stay in the HPC space, that means constantly upgrading your systems with new networking, compute, and storage, and HPE took the opportunity of the SC24 supercomputing conference to give a preview of the upgrades it has underway for its supercomputers in the coming year.
Let’s start with networking instead of compute, which would be our natural inclination. With alternative InfiniBand and commercial-grade Ethernet firmly established at 400 Gb/sec speeds and moving on up to 800 Gb/sec speeds, the first generation “Rosetta” Slingshot switch ASIC and “Cassini” Slingshot network interface ASIC were both looking a little long in the tooth at the 200 Gb/sec speeds that went into production at the end of 2019 and was fully ramped in 2022 with the delivery of the “Frontier” supercomputer at Oak Ridge National Laboratory. Rosetta and Cassini embodied a new HPC-tuned Ethernet, and therefore it took a bit longer to bring it to market and shake it down in full-scale systems.
In the commercial networking business, Ethernet upgrades happen every two years, and that is the cadence that Nvidia wants for its Ethernet and InfiniBand networks. We will see how that pans out. The cadence for InfiniBand has stretched here and there and were timed more to the supercomputer upgrade cycles that have tended to be three or four years apart. The timing for Cray’s interconnects varied greatly based on the amount of change went into each generation, with the “SeaStar” XT3 interconnect coming out in 2004, the “SeaStar2” for the XT4 in 2006, the “SeaStar2+” interconnect for the XT5 in 2007, the “Gemini” interconnect for the XK7 in 2010, and the “Aries” interconnect for the XC in 2012.
The big gap between Aries and Rosetta is when Intel bought the technology behind Gemini and Aries and tried to merge it with a variant of InfiniBand to create Omni-Path. When that plan did not work out so well (Cornelis Networks, which bought Omni-Path from Intel, is rationalizing it and trying to make it right), Cray decided to create Rosetta and slingshot itself back into HPC interconnects, this time choosing Ethernet as a foundation protocol.
The Rosetta ASIC, which we detailed back in January 2022, had 32 SerDes blocks that did PAM4 multi-level modulation on top of 28 Gb/sec native signaling per lane to deliver 56 Gb/sec of throughput. (PAM4 delivers two bits per signal as opposed to prior NRZ modulation, which is one bit per signal.) The Rosetta chips was etched in 16 nanometer processes from Taiwan Semiconductor Manufacturing Co, and burned at about 250 watts to deliver 64 ports running at 200 Gb/sec. (That’s four PAM4 lanes per port at 50 Gb/sec after data encoding overhead is taken off.)
In the dragonfly topology that Cray (and now HPE) prefers for the Slingshot family, the Rosetta-1 chip, as we now call this first Slingshot ASIC, could support up to 279,000 endpoints in a three-level network (top of rack, aggregation, and spine). Rosetta can be set up to support fat tree, torus, flattened butterfly, and other network topologies; you don’t have to just use dragonfly.
With the Cassini 1 NIC chips, HPE created a 200 Gb/sec adapter that had an injection bandwidth of around 28 TB/sec and a bi-section bandwidth of around 24 TB/sec. The Cassini-1 card has a lot of neat offload tricks aimed at accelerating HPC workloads, one of which we detailed here.

We also presume that HPE is on a cadence to get to 800 Gb/sec speeds with a future Slingshot 800 (perhaps in the fall of 2027) and 1.6 Tb/sec speeds with an even further out Slingshot 1600 (perhaps in the fall of 2029). The first jump is relatively easy – double up the native signaling speed. It is hard to imagine how to get to 1.6 Tb/sec per ports without just adding more ports per lane and trying to keep the speeds as low as possible. It could turn out that lane doubling per port happens at 800 Gb/sec and signal boosting only happens at 1.6 Tb/sec. All we know for sure is that with AI driving high-end system sales and Ethernet becoming a future standard here, HPE has to compete bandwidth for bandwidth with Broadcom, Nvidia, and Cisco Systems for switch and adapter ASICs.
We will let you know as we find out more about Slingshot 400 and the roadmap going out to 2030 or so.
The Compute Upgrade Next Year
With networking out of the way, we can now talk about compute. And the Cray EX and ProLiant XD (formerly known as the Cray XD) are both getting compute engine enhancements next year.
The Cray Shasta systems, which have been around for several years, have HPE’s Slingshot interconnect as their backbone and offer a wide variety of compute engine options that HPC centers can mix and match to support their various workloads. For instance, the Cray EX4000 chassis is the cabinet from which the 2.79 exaflops “El Capitan” supercomputer at Lawrence Livermore National Laboratory is made. In fact, seven of the top ten supercomputers ranked on the November 2024 Top500 rankings are based on the Cray EX platform; ten of the top twenty machines are based on the Cray EX, which is remarkable considering how much European HPC centers do not want to buy outside of the European Union.
The ”Perlmutter” system at Lawrence Berkely National Laboratory in the US uses Cray EX235n blades that have a mix of AMD “Milan” Epyc 7763 processors and Nvidia A100 GPU accelerators. The “Venado” system at Los Alamos National Laboratory in the US and the “Alps” system at CSCS in Switzerland both have Cray EX254n blades based Nvidia “Grace” CG100 CPUs and “Hopper” H100 GPUs. The “Frontier” system at Oak Ridge National Laboratory in the US, the “HPC6” system at energy conglomerate Eni in Italy, and the “Lumi” system at CSC in Finland all use Cray EX235a compute blades based on custom “Trento” Epyc CPUs and “Aldebaran” MI250X GPUs. Of course, the “Aurora” machine at Argonne National Laboratory in the US has custom Intel blades that pack two of its “Sapphire Rapids” Xeon 9470 CPUs with HBM memory and six of its “Ponte Vecchio” Max GPUs on a custom blade that, as far as we know, do not have a product number for which you can order one from HPE. And finally, El Capitan and its sibling “Tuolumne” machine at Lawrence Livermore and “El Dorado” machines at Sandia National Laboratories in the US are based on hybrid MI300A compute engines that mix AMD “Genoa” GPU chiplets with “Antares” GPU chiplets on a single package and puts eight of them on a Cray EX255a blade.
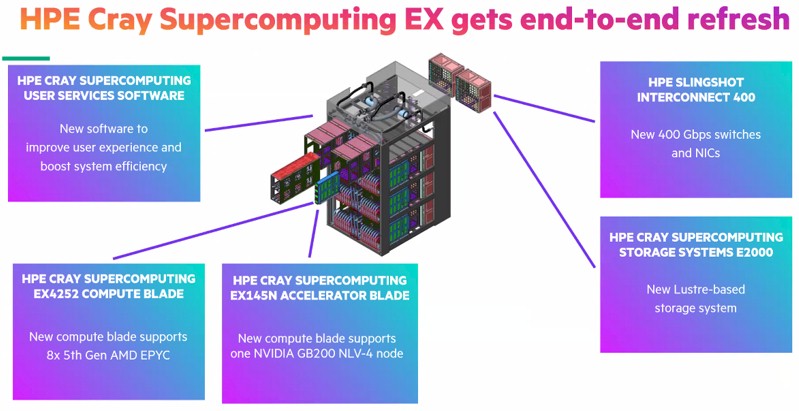
Two more Cray EX compute blades are coming in 2025 for the EX4000 enclosure:

Interestingly, HPE has chosen the “Turin” Zen 5c and not the plain vanilla, fatter cached Zen 5, variant of the top bin Turin processor for the upcoming Cray EX4252 Gen 2 compute blade shown on the right of the chart above. The Epyc 9965 CPU that HPE has chosen for its upcoming AMD compute blade has 192 Zen 5c cores running at a base clock speed of 2.25 GHz, and the Epyc 9755 that HPE has not chosen has 128 Zen 5 cores running at 2.7 GHz. You might think that clock speed reigns supreme in HPC, but by our estimate, the former chip has around 25 percent more integer and vector performance than the latter. And the price/performance on the higher performing chip is 8.6 percent better.
So that explains that CPU choice.
Anyway, with eight Epyc 9965s on each blade and 64 blades in one EX4000 chassis, that works out to a total of 98,304 cores in a single liquid-cooled rack, and by our math, there is 3.456 teraflops per socket at the base clock speed of 2.25 GHz, that is still 1.77 petaflops base per EX4000 cabinet in an all-CPU setup, and with all-core turbo, maybe that rack might hit 2 petaflops. With 500 racks, you could build an all-CPU exascale supercomputer. The 10.51 petaflops K supercomputer, arguably the most impressive all-CPU machine ever built, located at RIKEN Lab in Japan, had 800 racks when it was fully built out in 2011.
We live in the future. Five racks of AMD CPUs from 2024 with a total of 491,520 cores can match 800 racks of Sparc64-VIIIfx processors with a total of 88,128 cores. The K compute engines were heavily vectored, obviously and burned a ton of electricity – but were state of the art at the time.
In any event, the EX4252 Gen 2 compute blade will be available in early 2025.
By the end of 2025, timed to the market release of the double-whammy Grace-Blackwell GB200 NVL4 compute board from Nvidia, HPE will release the EX154n compute blade. (We know that it says 145n in the chart above, but 154n us actually correct.) We will be talking about the NVL4 unit from Nvidia separately, but basically it is a pair of Grace CPUs and a quad of Blackwell GPUs are interlinked in a six-way shared memory cluster using NVLink ports on a single board. Call it a superduperchip, we guess. . . .
The GB200 NVL4 board will allow HPE to put up 224 Blackwell GPUs in to a single EX400 cabinet across 56 blades. The fatness and hotness of the Grace-Blackwell complexes means eight compute slots are sacrificed in the EX4000 cabinet. Even still, a cabinet of these puppies will come in at just a tad over 10 petaflops with 42 TB of HBM3E stacked memory, and have another 52.9 TB of LPDDR5 memory and 8,064 Arm “Demeter” Neoverse V2 cores to give tasks to in a coherent NUMA space on the NVL4 board.
A mere hundred cabinets of the NVL4 boards and you break an exaflops at FP64 precision. That’s five times the compute density of the AMD Turin Epycs. But don’t get exuberant. The price/performance gap for FP64 performance is smaller than you might think.
Let’s do some math. The Nvidia Blackwell GPU plus half of the Grace CPU paired to it probably costs on the order of $40,000; the Epyc 9965 costs $14,813. An EX4000 rack of those Epyc 9965s (192 devices) will cost you around $2.72 million, and a rack of Nvidia B200s will cost you around $9 million. Five times the performance for 3.3X the cost is an improvement, to be sure. But the bang for the buck is only 35 percent better on the GPU compute engines versus the CPUs – $889 per teraflops for the Blackwells versus $1,362 per teraflops for the Turins.
The high cost of HBM memory has closed the price/performance gap between CPUs and GPUs a bit at least when just reckoning raw FP64 performance. The question is, can you get that performance and for what workload? Which is why you run benchmarks of your own.
In addition to the networking and compute upgrades in the Cray EX line, the flash storage used in the machines is also getting a boost:
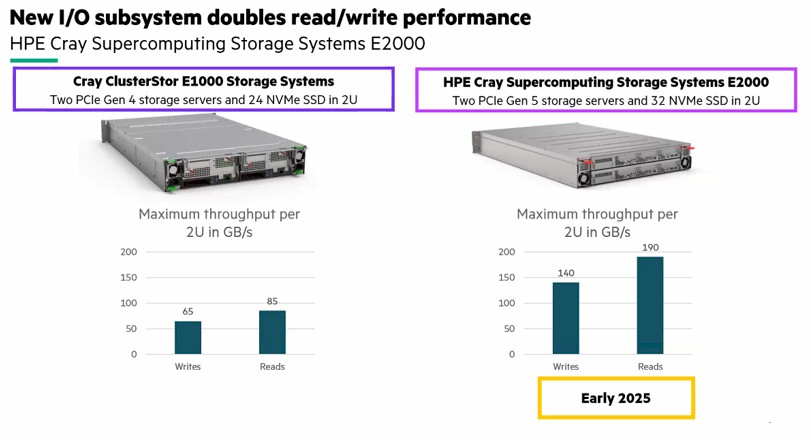
The new Cray E2000 all-flash array has 32 NVM-Express flash drives and two storage servers with PCI-Express 5.0 slots and delivers more than twice the read and write performance than the E1000 it replaces.
That brings us, finally the to ProLiant XD line of machines that are aimed at AI service providers and large enterprise customers who are used to using baseboard management controllers – in the case of HPE, this is the iLO or Integrated Lights Out card – and are not looking for the densest machinery or liquid cooling. (Although the ProLiant XD does offer liquid cooling on key components in the chassis.)
HPE is cooking up two new ProLiant XD eight-way accelerated systems for the near term:

The ProLiant XD680 pairs two “Emerald Rapids” Xeon SP processors with eight Gaudi 3 accelerators, both from Intel. This will be available before the end of the year, which is no surprise given that Intel has said the demand for Gaudi 3 devices is lower than expected.
The ProLiant XD685 will have a pair of AMD Turin Epyc CPUs on the host partition and then offer the choice of eight Nvidia Hopper or Blackwell GPUs or eight AMD “Antares” MI300X or MI325X GPUs. This machine will be offered in air-cooled and liquid-cooled versions and will be available in early 2025.