
If Intel hopes to survive the next few years as a freestanding company and return to its role as innovator, it can not afford to waste its time and it cannot afford to make any more mistakes.
Which is why the new top brasses at Intel – chief executive officer of Intel Products Michelle Johnston Holthaus and chief financial officer Dave Zinsner, who are co-CEOs of the company – are pushing out the next generation of its E-core Xeon CPUs and turning a future AI accelerator that represents the convergence of its datacenter GPU and AI accelerator lines into a research platform as it goes back to the drawing board to create a rackscale AI design that presumably will do a better job competing against Nvidia.
The roadmap changes, which we backcast into our recent CPU roadmap story, were made during the call with Wall Street analysts yesterday going over Intel’s financial results for Q4 2024. We will get to the numbers in a second, but first let’s update the Intel datacenter compute engine roadmap, starting with the “Clearwater Forest” Xeon 7 E-core chip that was expected later this year and that was expected to be the first datacenter chip to use its 18A RibbonFET manufacturing process.
“So I really look at the datacenter market in kind of two buckets,” Johnston Holthaus said on the call when asked about the timing change for Clearwater Rapids. “We have our P-core products, which you know is Granite Rapids and then we have our E-core products which equates to Clearwater Forest. And what we’ve seen is that’s more of a niche market, and we haven’t seen volume materialize there, as fast as we expected. But as we look at Clearwater Forest, we expect that to come to market in the first half of 2026. 18A is doing just fine on its performance and yield for [Diamond] Rapids, but it does have some complicated packaging expectations that move it to 2026. But we expect that to be a good product and continue to close the gap as well. But this is going to be a journey.”
Johnston Holthaus said “Granite Rapids” in the paragraph above, but meant to say “Diamond Rapids.” The Granite Rapids Xeon 6 processor has already been launched and is etched with the Intel 3 process, which if you want to be generous is akin to 3 nanometer processes from Taiwan Semiconductor Manufacturing Co.
It sounds to us that some of the packaging kinks need to be worked out for Xeon-class chips using 18A. We also think, given the niche nature of the E-core variants, Diamond Rapids P-core variants could come to market ahead of E-core Clearwater Forest variants. And if it gets crazy enough, the E-core chip could be moved to custom products and not rolled out as part of the official Xeon roadmap at some point.
The reason that might happen is simple: The E-core chips do not have full-on AVX vector math units and they do not have AMX matrix units or HyperThreading simultaneous multithreading. The first and second are increasingly important for AI inference and light AI training. AMD does not have matrix math units on any Epyc CPUs as yet, but it does have full-on vectors on boith the plain vanilla and skinny core “C” variants for the “Genoa” Epyc 9004 and “Turin” Epyc 9005 CPUs. The AMD approach to skinny cores is to cut the L3 cache in half for the C variants and rejigger the core such that you can fit more cores in a socket. With the Genoa chips, that was 33 percent more cores, and with Turin, it is 50 percent more.
As we put it at the Granite Rapids launch: Intel Brings A Big Fork To A Server CPU Knife Fight. It is amazing to us that Intel didn’t do the same trick that AMD did to make a skinny core and preserve compatibility, and it is also amazing to us that hyperscalers and cloud builders indicated that they were fine with this forking of the architecture. Then again, a hyperscaler/cloud builder talking up FPGA-based DPUs is how Intel got scared into spending $16.7 billion on Altera. Sometimes, Intel gets a bad steer, and it doesn’t compensate by stiffening its arms. (And to be fair, we caught a little FPGA religion, too, at the time, but still think Intel’s exuberance was much larger than ours.)
Because of the intense competition that AMD is bringing with the Genoa and Turin datacenter CPUs, Intel has had to circle back and actually chop prices on the Granite Rapids chips, which were announced in September 2024 with the highest prices we have ever seen for Intel CPUs. This price cuts better align Granite Rapids chips to Genoa Epyc 9004 pricing, which was probably happening informally in every deal anyway. All five of the Granite Rapids chips that were announced last fall had a price cut, with three getting a 30 percent cut, one getting a 20 percent cut, and another getting a 13.4 percent cut. The top bin parts with 128 and 120 cores and the lower bin part with 72 cores had the deepest cuts.
That brings us to the ever-changing “Falcon Shores” accelerator.
Three years ago, Intel was working on a GPU product line anchored by its “Ponte Vecchio” Max GPU and followed by its “Rialto Bridge” kicker and at the same time was creating a hybrid CPU-GPU device called Falcon Shores that, like AMD’s MI300A, would mix Xeon CPU cores and matrix math units that were derived from these GPUs as well as the Gaudi line of XPUs that it got through its acquisition of Habana Labs. In February 2022, we contemplated what Falcon Shores might look like, and the expectation was that these accelerators would plug into the same sockets as the Granite Rapids CPUs.
by March 2023, Intel’s GPU efforts were in a shambles with Ponte Vecchio being very late and Rialto Bridge canceled. AT the time, there were rumors that Falcon Shores using only GPU engines would be the future discrete accelerator from Intel and that project was pushed out “beyond 2025.” And in June 2023, Intel downplayed the whole idea of a hybrid CPU-GPU device and merged the Gaudi matrix math engines with the Falcom Shores all-GPU machine to create a new and improved plan for Falcon Shores. The idea was to take the wide Ethernet pipelines used in the Gaudi architecture and the Falcon Shores GPU and Gaudi matrix math to create a unified accelerator that could run workloads designed for Gaudi and Pente Vecchio.
Well, forget all of that. Now everything is shifting out further to a still future accelerator called “Jaguar Shores.”
“We are not yet participating in the cloud-based AI data center market in a meaningful way,” Johnston Holthaus said, stating what is obvious to us all given the explosive fortunes of Nvidia. “We have learned a lot as we have ramped Gaudi, and we are applying those learnings going forward. One of the immediate actions I have taken is to simplify our roadmap and concentrate our resources. Many of you heard me temper expectations on Falcon Shores last month. Based on industry feedback, we plan to leverage Falcon Shores as an internal test chip only, without bringing it to market. This will support our efforts to develop a system-level solution at rack scale with Jaguar Shores to address the AI datacenter. More broadly, as I think about our AI opportunity, my focus is on the problems our customers are trying to solve, most notably, to lower the cost and increase the efficiency of compute.”
So that is the end of Falcon Shores and the beginning of Jaguar Shores, of which we know nothing other than the hinted at rackscale approach mentioned above.
With that, let’s talk about Intel’s datacenter business as it was in the fourth quarter.
In the December quarter, Intel’s overall revenues were $14.26 billion, down 7.4 percent year on year, but up 7.3 percent sequentially. The company posted a $152 million net loss, compared to a $2.67 billion net gain in the year ago period, but a whole lot better than the nearly $17 billion loss it booked in Q3 2024 due mostly to restructuring charges.
Intel ended the quarter with $22.06 billion in cash and investments in the bank, money it is correctly parceling out very carefully as it invests in products and foundries.
Here is the breakdown of Intel’s revenues and operating income by group for the past two years:

And here is the same data shown graphically for revenues:

Intel was able to hold revenues in its Datacenter and AI (DCAI) group relatively steady in the fourth quarter, with sales down 3.3 percent to $3.39 billion but up 1.1 percent sequentially. Operating profits were $233 million, a pretty anemic 6.9 percent of revenues and down 68.4 percent from the year ago quarter. Intel’s profit levels for datacenter products has been declining over the past year, which is no doubt concerning and which is also compelling the company to break its Network and Edge (NEX) group into pieces, with Xeon processor and networking product sales in NEX eventually being merged back into DCAI. (Other parts of it will go into its Client Computing Group at some point in the future.)
The NEX group had a revenue bump of 10.3 percent to $1.62 billion, and operating income was $340 million (20.9 percent of sales), which is the healthiest profit levels Intel has had in this line of business in years. The Altera FPGA business, which we also think of as part of the core datacenter business, had sales of $429 million, down 10.6 percent, and operating income of $90 million, a factor of 21.5X higher than a year ago.
We have been tracking Intel’s Data Center Group, the core business that was created for server products way back in the day, for a long time, and have used the combination of DCAI and a portion of NEX and Altera as a proxy for the historical Data Center Group that was first headed up by Pat Gelsinger so many years ago.
Here is the trend:
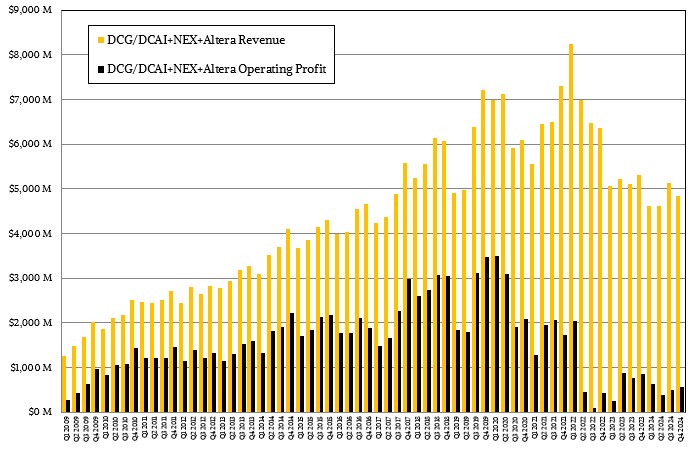
Intel’s rise in the datacenter and its hegemony over server compute is evidenced in the run from 2009 through 2019, and you can see where AMD started taking share in 2020 and how this has caused Intel much grief since then.
The server CPU business has become intensely competitive, and it is safe to say that a lot of Intel’s revenues are supply wins, not design wins, considering the much higher core counts and performance that AMD delivers for most workloads at this point.
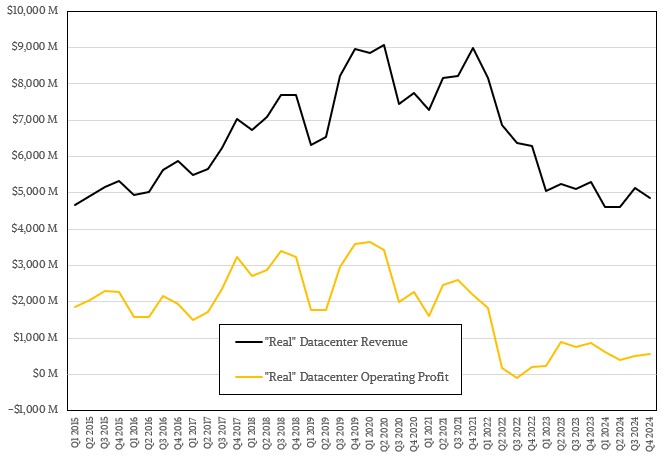
Intel used to sell flash and 3D XPoint memory storage, and it also used to sell network switches, and this all made the “real” systems business at intel much larger. (The company still sells network adapters and DPUs.) Since 2015, we have been modeling this “real” datacenter business, which ascended to around $9 billion a quarter in 2019 and kissed it once again in 2021 during a hypercaler and cloud buildout before deflating down to around $5 billion a quarter now. Profits have collapsed much faster, as you can see, but are better than the minor loss Intel posted in the third quarter of 2022.
The question we have – that everyone has – is: Can Intel ever get above $5 billion a quarter again in the datacenter, and can it do so profitably? Because we like competition, we certainly hope so.

Bechtolsheim Outlines Scaling XPU Performance By 100X By 2028
Effects are multiplicative, not additive, when it comes to increasing compute engine performance. And if there is one person who is not worried about how we are going to increase the oomph of those engines by two orders of magnitude in the next six years, it is Andy Bechtolsheim. Well, …

Programming The Network With Intel NEX Chief Nick McKeown
It would be very difficult indeed to find a better general manager for Intel’s newly constituted Network and Edge Group networking business than Nick McKeown, and Pat Gelsinger, the chief executive officer charged with turning around Intel’s foundries and its chip design business, is lucky that Intel was on an …
Intel Unrolls DPU Roadmap, With A Two Year Cadence
There is a fundamental disconnect between the cadence that chip makers want for their devices and what the hyperscalers and cloud builders would prefer. And it looks like they are working together to split the difference and accept a two year cadence for the architectural upgrade cycle for all key …
While going in the wrong direction is bad, I don’t see how changing direction every year will ever get anywhere. If I were the interim CEO I’d apply a tick cycle to the processors that just came online in Aurora and shrink the process node to leverage the AI and HPC software know-how generated by that supercomputer.
You get my vote!
E-cores remind me a bit of Sun’s Niagara Falls (UltraSPARC T1, T2, …) and the Jonathan Schwartz days. I’m not sure that I fully support a focus on those at the expense of P-cores (Granite and Diamond Rapids) — and as many of these as possible, with solid matrix-vector units indeed. McCredie’s college professor was right about this imho: “Always stay close to performance”!
I’m sure Mr.DIMM would agree …
I can think of 4 possible explanations for the delay in Clearwater Forest. Intel’s Xeon Diamond Rapids uses an LGA 9324 package to support 16 channels of MR-DIMMs. If Clearwater Forest uses the same package (which seems likely), the delay in Clearwater Forest could be due to difficulty getting 16 channels of MR-DIMMs to run at full speed (12.8 GTransfers/sec ?). This is understandably a difficult engineering challenge but one that is required to support the high core counts. Sixteen channels of MR-DIMMs running at 12.8 GTransfers/sec has roughly double the MR-DIMM bandwidth of Granite Rapids-AP. A second possibility is a problem with Foveros 3D used to connect the Intel 3 base die to the Intel 18A compute tiles. A third possibility is that Intel is capacity constrained on Intel 18A due to reduced fab spending. If the client Panther Lake processor ships in the second half of this year with Intel 18A, that would suggest that 18A is healthy. A fourth possibility is that Clearwater Forest is mainly for hyperscalers and hyperscalers have no money to buy it because hyperscalers are spending all of their money on NVIDIA GPUs. Amazon, Microsoft, Google and Apple have designed their own server CPUs so they are less interested in Clearwater Forest. Oracle has invested $1B in Ampere Computing.
Falcon Shores probably got cancelled because Intel concluded it was not competitive. Intel should strengthen the AI capability of their server CPUs. This could be done by adding neural engines to the Intel 3 base die and supporting HBM3e on Diamond Rapids. Sensible enterprises don’t want to send highly confidential information in AI prompts to third parties. They want to run LLMs in their own data centers. Given the prices of NVIDIA GPUs, server CPUs that can run LLMs are a good option for these customers. To save power, arithmetic for LLMs should ideally occur inside the HBM stack and/or directly under it in the Intel 3 base die. Moving LLM weights from DRAM to CPU cores consumes far more power than LLM arithmetic.
semiconductor.samsung.com/news-events/tech-blog/hbm-pim-cutting-edge-memory-technology-to-accelerate-next-generation-ai
Moving some math/logic into the HBM and it’s not really M anymore it’s some kind of systolic thingy or maybe we can call it a step towards a “neuromorphic” thingy. Whether any of that should be build on DRAM is yet another question. And if it’s not M then the HB requirement maybe doesn’t matter so much either, and it can be put back outside.
Just exactly how you build such a systolic thingy has stumped the field for fifty years (or longer) but it *seems* like a good idea.
I don’t think there needs to be a systolic processor inside the HBM. The arithmetic for an LLM is just low precision multiplies (such as 8-bit) that are accumulated. One input of the multiply is a neural net weight read from DRAM and the other input is the output of the previous stage of neurons from a register bank. The reason for doing arithmetic inside the HBM stack is that it takes far more energy (> 10x) to move neural net weights from DRAM to CPU cores than to do the arithmetic. The arithmetic could be done on the DRAM die (which is what Samsung appears to have done) or it could be done on a logic die inside the HBM stack or it could be done directly under the HBM stack, which would be the Intel 3 base die on Diamond Rapids. The goal to is move the neural net weights the shortest distance possible because that reduces the energy consumed. As an example, if 8 8-bit multiplies are accumulated into 24-bits inside the HBM stack, instead of transferring 8 x 8-bit = 64 bits from HBM, only 24-bits would need to be transferred. This would provide more than a 2x improvement in HBM bandwidth and energy consumed. I have no evidence for this, but my guess is that NVIDIA will design a custom HBM for their exclusive use.
Agreed on all fronts. Especially when it comes to getting AI on CPUs and LLM math closer to the HBM that is on the CPUs.
Interesting link by Mike (Harris) indeed! Doing Processing-In-Memory, in HBM (HPB-PIM), on AMD MI100s, Samsung saw a doubling of performance and lower power consumption (in 2023). Reminds me a bit of the researchers’ hardware-related recommendations from TNP’s last Monday’s DeepSeek deep dive (Jan. 27) where they did matrix-multiply in FP8 but processed master weights and gradients in FP32. Coupling those with a logarithmic perspective may suggest doing matrix multiplies in PIM as sums of biased exponents (8-bits in FP32), with an xor of the sign bit, followed possibly by a max() to simplify accumulation. It could save valuable silicon area, and energy, if it works in both training and inference!
The only Intel 3 product in the channel is 64C 6710E in sample volume. There is no Granite Rapids in the channel. Emerald Rapids at Intel 7 shows highly manufacturable on supply data but in slim volume. Entering January Emerald available supply is 158% more than Turin but only 18.7% of Bergamo + Genoa available.
Intel is selling Xeon on the cheap, well under AMD price floor, with room to raise price and remain under AMD’s Epyc price floor. One question is why that has not happened? In 2024 Emerald average gross range $884 to $1312. Sapphire Rapids gained availability in q4 + 68% q/q for gross $1571.
intel ships 13,745,725 DCG Xeon units in 2024 and 18,598,456 NEX units on a net basis covering all costs.
My full DCG + NEX report is here in comment string.
https://seekingalpha.com/article/4753856-intel-q4-theres-no-good-news-here-sell-now
Mike Bruzzone, Camp Marketing
Mike Bruzzone wrote: “DCG for 2024 by product on channel change in quarterly supply;
Sierra and Granite Rapids to date = 369,652 units”
What does “product on channel change in quarterly supply” mean and where does this number come from?
Sierra Forest was launched on 6/3/24 and Granite Rapids was launched on 9/24/24. I wonder if the limited shipment of Granite Rapids so far is due to limited supplies of MR-DIMMs. Granite Rapids-AP has up to 2x more cores than Emerald Rapids but only 1.7x more DRAM bandwidth when used with DDR5-6400. If customers are satisfied with the DRAM bandwidth per core of Emerald Rapids, they could use the 96 core version of Granite Rapids-AP with DDR5-6400, but that doesn’t appear to be happening. End-users and OEMs may be waiting until they can get MR-DIMMs to buy Granite Rapids. The only other explanation I can imagine is that there isn’t enough Intel 3 capacity for both customers who buy directly from Intel and for customers who buy from OEMs. There are currently no Granite Rapids servers available from Dell, HPE, Lenovo, Cisco or Supermicro.
Mike Harris,
Xeon Sierra Forrest and Granite Rapids at 369,652 units produced in 2024 or basically to date, is based on known channel supply volume of Emerald Rapids in its first 2 quarters of supply. My SF + GR estimate based on ER two quarter roll out, is averaged within the percent of known Emerald and Sapphire Rapids supply volume in 2024. It’s an SF + GR supply projection based on Emerald Rapids first two quarters volume recorded from open market ‘eBay’ sales offers.
Otherwise, there is no Granite Rapids in the channel and Sierra Forrest actual is 0.0057%. I record unit volume on Intel net take into division revenue. If on gross take into revenue the projection decreases to 189,652 units. On the higher estimate at 18 CPU per rack, equals 20,553 racks. My take is all ER + GR no matter the volume are Intel samples subject forward contract agreements for Intel product meeting customer specifications.
Alternately, there are none or few Sierra Forrest and Grante Rapids on a bad yield day?
‘Channel change in supply’ is just that. Relying on open market product available as a proxy for supply volume can cumulate quarter to quarter. Subsequently, the difference quarter to quarter reveals the gain or decrease in available supply. This can be relied to determine a production metric by backing out change in quantity from total quantity and cumulating quantities that are basic production microeconomic assessment methods.
mb
Mike Harris,
And thank you for this observation, “If customers are satisfied with the DRAM bandwidth per core of Emerald Rapids, they could use the 96 core version of Granite Rapids-AP with DDR5-6400, but that doesn’t appear to be happening. End-users and OEMs may be waiting until they can get MR-DIMMs to buy Granite Rapids. The only other explanation I can imagine is that there isn’t enough Intel 3 capacity for both customers who buy directly from Intel and for customers who buy from OEMs. There are currently no Granite Rapids servers available from Dell, HPE, Lenovo, Cisco or Supermicro. mb