
The HPC centers of the world like fast networks and compute, but they are also always working under budget constraints unlike their AI peers out there in the enterprise, where money seems to be unlimited to what sometimes looks like an irrationally exuberant extent.
They are also don’t have a lot of money, which has limited their use of cloud capacity. The reason is this: If you have time and do not need large scale to run a simulation, and if you amortize the cost of an X86 cluster over four or five years – or sometimes longer – it generally costs a lot less to buy a lot of servers and some switches and storage sufficient to run a parallel file system than it does to rent equivalent capacity from one of the big cloud builders.
To be fair, if you need to run a simulation quickly and time is of the essence, then paying a premium for cloud capacity is worth it. And if you need very hefty compute and or you want to get out of running a datacenter altogether, as many academic and research supercomputing centers are pondering, then you can just go to the cloud and be done with it.
Whatever the case, all of the cloud builders want to attract customers who run traditional scientific simulations and run them on CPUs for those workloads that have not yet been ported to GPUs. Google, as the third largest cloud provider in the United States, needs to find angles to attract new customers that Amazon Web Services and Microsoft Azure have not always focused on but have been doing more with in the past several years. If Amazon and Microsoft are chasing HPC, with both CPU and GPU systems, then Google has to as well.
Last month, Google rolled out its A4 instances based on eight of Nvidia’s “Blackwell” B200 GPUs and providing 72 petaflops of floating point oomph at FP8 resolution, which offers 2.25X more performance on AI work than the prior A3 Mega instances on Google Cloud using “Hopper” H100 GPUs. These A4 instances were generally available in March.
Google also has installed a variant of the rackscale GB200 NVL72 system equipped for its own datacenters, which has 72 of the B200 GPUs with slightly more oomph and HBM3E memory than the earlier B200s and that delivers 720 petaflops at FP8 precision in a rack. The A4X virtual machines slice this rackscale system into slices with four GPUs, which is 40 petaflops at FP8. The A4X instances are still in preview.
We presume there is a way to have a single Google Cloud VM scale all 72 of the Blackwells, which is why Nvidia engineered it the way it did. (For HPC applications, this may happen naturally using MPI over NVLink/NVSwitch.) The point is: Any machine that is great at AI can be great at HPC, too.
But as we say, there are still a lot of CPU-only HPC workloads out there, and that is what the H4D instance from Google Cloud is all about.
The H4D instance is based on AMD’s fifth generation “Turin” Epyc 9005 processor. And when we say processor, we mean a single processor SKU. Which just don’t know which one as we go to press. The Google announcement counts cores, not vCPUs or what we call threads around these parts, but we don’t know if that is accurate. (We have calls into both AMD and Google because people say cores when they mean threads all the time.)
Let’s look at the options, and there are five:
It could be a single socket server node underneath the H4D instance using the Epyc 9965 CPU that makes use of the trimmed down “Zen 5c” core. The Zen 5c variants of Turin have half the L3 cache per core and the resulting packages deliver higher core count, higher throughput, and more aggressive price/performance than the plain vanilla Turin chips based on the Zen 5 core. We doubt this is the choice because plenty of HPC workloads are cache sensitive. And thus underneath that H4D instance could be a two-socket server using a pair of 96-core Epyc 9655 processors.
If Google meant to say “vCPU” instead of “core” in its announcement, then it might be a pair of 48-core Epyc 9475F Turin processors underneath the H4D, which as an F model is actually aimed at HPC workloads. This chip is based on Zen 5 cores. Or it could be a single 96-core Epyc 9645 based on the Zen 5c cores that delivers 192 threads.
On the prior H3 instances on Google Cloud, which were based on Intel’s “Sapphire Rapids” Xeon 4 processors, simultaneous multithreading was turned off, so the vCPU count and the physical core count are the same, and the underlying machine was a two-socket server with a pair of 44-core Xeon 4s.
So if you twist our arms, we will say the H4D is actually based on a pair of 96-core Epyc 9655s with the threading turned off, and it meant to say cores. (Google could just tell us and eliminate the mystery.)
Note: after we went to press, AMD confirmed it was indeed our guess.
To continue: There are three different configurations of the H4D instance. There is one with 720 GB of main memory, one with 1,488 GB of memory, and one with 1,488 GB of memory and 3.75 TB of local flash storage.
The H4D instances offer significantly more performance than the prior C2D and C3D “compute intensive” instances that Google Cloud offered. On the left in the chart below is shown the performance, in gigaflops, of a 192-core instance and a single core running the High Performance LINPACK benchmark commonly used to measure flops performance in the HPC community:

A full H4D instance can drive 12 teraflops of HPL oomph using the integrated vector engines on the Turin cores at FP64 precision. That is five times that of the C2D instance (based on a prior generation of AMD Epyc CPUs) and nearly 1.8X higher than the C3D instance.
The interesting bit is the performance per core, and you can see how the Turin Zen 5 core is around 40 percent faster on 64-bit floating point work than the Sapphire Rapids “Golden Cove” core on the HPL test.
On the right hand side of that chart, you see the STREAM Triad memory bandwidth benchmark results, which also show that on a per VM and per core basis, the Turin chip used by Google bests the prior Xeon chips used in earlier compute intensive instances. The Turn chip has about 30 percent more effective memory bandwidth on the STREAM test compared to the Xeon 4.
Here is how the H4D compared to the C2D and C3D instances on a variety of HPC workloads:

The H4D instance is also the first use case of pairing Google’s Titanium offload engines with an HPC instance. In this case, it is a 200 Gb/sec network link for the instance, which runs Ethernet with RDMA for low latency.
Don’t presume this is just ROCE v2. The Ethernet used by Google is based on its Cloud RDMA, which like many other Titanium network offloads. The Titanium offload is neat in that it has two stages of offload – one from the host to the network interface card and, funnily, the network card has a further intermediary offload processor for storage and network functions at the datacenter level.
Like this:

In addition to this double offload model, the networking used for the H4D instances also includes a new hardware-assisted transport layer that Google rolled out last year called Falcon, which puts certain transport layer functions in hardware instead of software in the network interface card to speed them up. Falcon can be slid underneath upper layer protocols in the network stack, like RDMA or NVM-Express, and sits on top of the UDP/IP layer. Falcon is binary compatible with Ethernet and InfiniBand protocols at the application level, which means any HPC applications you have running on either network can be moved to HD4 instances using the custom IPUs on Google Cloud without having to recompile them.
The performance benefits of Cloud RDMA powered by the Falcon transport layer and the Titanium offload engines is measurable, and scales across VMs like this on OpenFOAM and STAR-CCM:
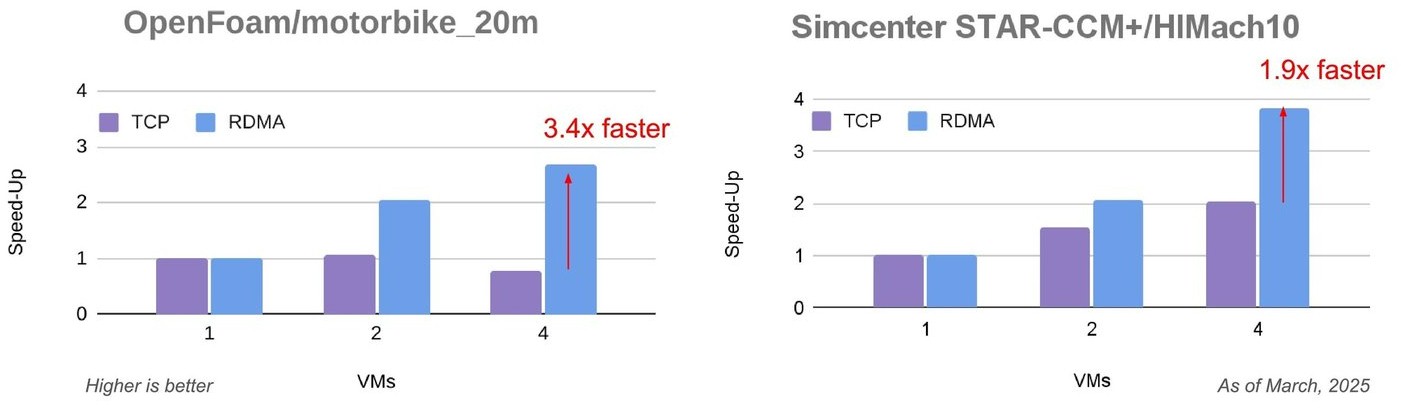
And here’s what it looks like running GROMACS and WRF:
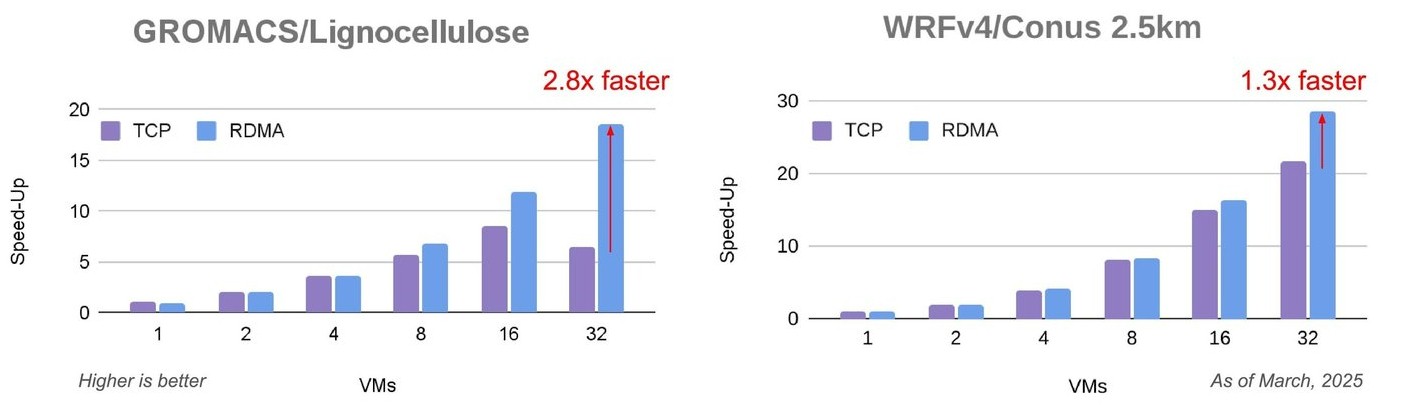
With the Ethernet protocol being more efficient because of the transport layer and RDMA also doing its part, you can see that the Google Ethernet variant significantly helps boost performance.
No word on what H4D instances cost or when they are available, but they are in preview now.
You know us, we can’t leave that alone. The on demand price for the prior generation H3 instance was $4.9236 per hour. There was no H2, so we can’t plot a line to see a possible trend. We also do not have H2 performance figures, but as far as we know, the H3 is based on the same 88-core Sapphire Rapids node as the C3D instance that was tested on HPL. Call it 7.4 teraflops, more or less, for the node, based on the picture above, for the H2 and C2D instance. That is a 62 percent increase in FP64 performance, and round it to 60 percent just to make it easy. That works out to an estimated price of $7.8777 per hour for on demand pricing for a 12 teraflops node, which is $69,056 for a full year of renting on demand. Do the math and that is $5,755 per teraflops.
How does that compare to an H100 or a B200 node on demand in terms of performance, price, and value for dollar at FP64 precision?
Let’s do the math.
An A3 High GPU instance with a single H100 GPU and a portion of the host CPU costs $11.0613 per hour to rent on demand, and that works out to $96,963 per year. The H100 has 67 teraflops of FP64 on its tensor cores and 33.5 teraflops on the vector cores. So on the vectors, that is exactly a factor of 2X better bang for the buck for an H100 using only the vector units compared to the full H4D and aa factor of 4X using the tensor units.
Google has announced A4 instances based on Blackwell GPUs as we point out above, but as we pointed out back in February, the B200 is rated at 40 teraflops on its vector and tensor units alike, which is actually 40 percent lower tensor core performance and only a 19.4 percent increase in vector performance. We think a B200 this year probably costs twice as much as what the H100 cost last year, and there’s no reason to think the underlying HGX B200 server doesn’t cost twice as much, then renting an A4 instance will cost around $193,923 for a year on demand, and at 40 teraflops at FP64 precision, that is $4,848 per teraflops. Which means that AMD CPU instance, which is clearly a lot larger and less power efficient, is only 18.7 percent more expensive on an FP64 flops basis than a B200 GPU. Google is paying the datacenter space, power, and cooling as well as the operations costs for all of this, so you don’t have to care, at least for the puposes of this conversaation.
This lessening gap on FP64 performance between AMD CPUs and Nvidia GPUs is a real gauge for how Nvidia is focusing on AI in its GPU designs, with lower precision and all kinds of hardware-assisted features, and is not being as aggressive about HPC. And that is because Nvidia thinks the future of HPC is AI. As many people do. But the reality of HPC centers is that CPUs are still the main compute engine, and it will stay that way, and Google and the other cloud builders can take advantage of that.


With Aquila, Google Abandons Ethernet To Outdo InfiniBand
Frustrated by the limitations of Ethernet, Google has taken the best ideas from InfiniBand and Cray’s “Aries” interconnect and created a new distributed switching architecture called Aquila and a new GNet protocol stack that delivers the kind of consistent and low latency that the search engine giant has been seeking …
Other Than Nvidia, Who Will Use Arm’s Neoverse V2 Core?
We are still plowing through the many, many presentions from the Hot Interconnects, Hot Chips, Google Cloud Next, and Meta Networking @ Scale conferences that all happened recently and at essentially the same time. And we intend to take our usual, methodical approach of finding the interesting bits and doing …
AMD’s Instinct GPU Business Is Coiled To Spring
Timing is a funny thing. The summer of 2006 when AMD bought GPU maker ATI Technologies for $5.6 billion and took on both Intel in CPUs and Nvidia in GPUs was the same summer when researchers first started figuring out how to offload single-precision floating point math operations from CPUs …
While Zen5 has full width AVX512, how does this complete with the high bandwidth memory of the Zen4 HBv5 instances in the Azure cloud? I suspect some HPC applications would prefer the HBM.
Good point. I will have to see what the memory bandwidth looks like.