

The long wait for volume shipments of Intel’s “Knights Landing” parallel X86 processors is over, and at the International Supercomputing Conference in Frankfurt, Germany is unveiling the official lineup of the Xeon Phi chips that are aimed at high performance computing and machine learning workloads alike.
The lineup is uncharacteristically simple for a Xeon product line, which tends to have a lot of different options turned on and off to meet the myriad requirements of features and price points that a diverse customer base usually compels Intel to support. Over time, the Xeon Phi lineup will become more complex, with the addition of versions of the processor that have integrated Omni-Path networking ports on the Knights Landing package, and eventually Intel will deliver versions of the chip that slide into PCI-Express peripheral slots like the previous “Knights Corner” generation of Xeon Phi coprocessors do. It remains to be seen how much demand there will be for these coprocessors compared to the directly bootable versions that Intel is currently shipping.
Intel revealed the basic architecture of the Knights Landing chips back in March 2015, and lifted the veil a bit further about more of the specs on the chip in November last year as it started shipping pre-production silicon to Cray and early adopter customers Sandia National Laboratory in the United States and CEA in France. We will give you a brief review, but drill down into those stories for a deeper look into the feeds and speeds.
The Knights Landing chip is etched in 14 nanometer manufacturing processes, like the current “Broadwell” Xeon E5 and E7 processors used in servers, and with over 8 billion transistors, it is the largest chip that Intel has ever made.
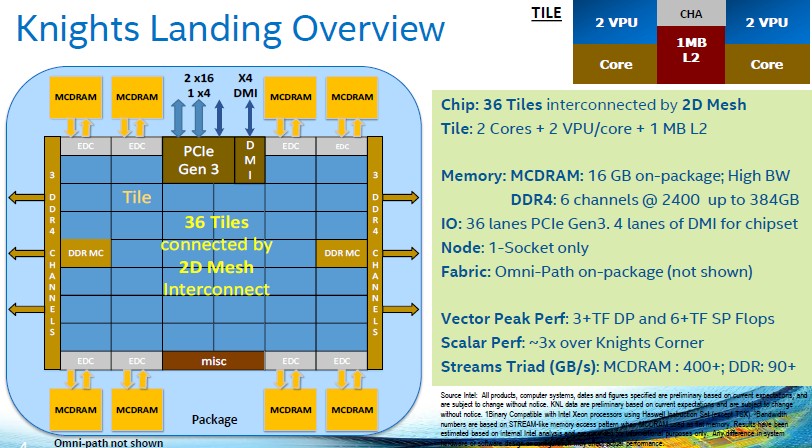
The Knights Landing die actually has 76 cores on the die, but to increase the yield on chip manufacturing process, Intel’s is only shooting for chips that have 72 cores as the top-bin part and, as it turns out, will be offering versions with lower clock speeds and core counts to have some variation in the SKU stack and therefore providing different price points. The cores on the Knights Landing chip are based on a heavily modified “Silvermont” Atom core that has four threads on it. These are tiled in pairs, with each core having two AVX512 512-bit vector processing units and 1 MB of L2 memory shared across the tile. The tiles are linked to each other using a 2D mesh interconnect, which also hooks into the two DDR4 memory controllers that feed into so-called far memory, which scales up to 384 GB capacity and which delivers around 90 GB/sec of bandwidth on the STREAM Triad memory benchmark test. That 2D mesh also hooks the cores into eight chunks of high bandwidth stacked MCDRAM memory, which scales up to 16 GB of capacity; this is known as the “near memory” in the Knights Landing chip and offers more than 400 GB/sec of bandwidth to keep those cores well fed. Intel has a number of different modes of memory addressing in the Knights Landing processor, including using the combined memory as a single address space or using the MCDRAM as a L3 cache for the DRAM memory. Add it all up, and Intel has promised that a Knights Landing processor would deliver more than 6 teraflops of single precision and more than 3 teraflops of double precision floating point performance.

The Knights Landing chip embodies a number of firsts for Intel, including the first integrated high speed main memory on any class of Xeon processor, the first on-package integrated interconnect, and the first bootable implementation of what has been, up until now, a coprocessor that had to be tied to a regular Xeon chip to do any useful work.
As far as we know, Intel intended to offer Knights Landing processor packages and coprocessor cards with either 8 GB or 16 GB of MCDRAM, and we learned last fall from Charles Wuischpard, general manager of the HPC Platform Group within Intel’s Data Center Group, that Intel had planned to offer a version of Knights Landing that did not include any MCDRAM at all, and with the express intent of offering a processor that would scream on certain benchmarks, including the Linpack Fortran matrix math test that is used to rank the world’s most powerful HPC systems.
In a briefing ahead of the ISC16 event, Wuischpard said that Intel had reconsidered its SKU plans with Knights Landing.
“All of the memory is 16 GB across the board, and we had originally talked about having a much richer matrix of SKUs ranging from no MCDRAM memory to 16 GB,” Wuischpard explained in a briefing with The Next Platform. “It was just too busy and too complex, and in the end, everyone wanted the on-package memory for the bandwidth and performance benefits. So we decided to shrink the SKU stack and make it easier to understand. It also makes it easier from a manufacturing standpoint to just populate everything with 16 GB.”
Obviously if customers want other Knights Landing variants, Intel has shown itself to be perfectly happy to make accommodations with custom parts with regular Xeon server chips and would likely do so with Xeon Phi processors, too.
There are, as it turns out, four different versions of the Knights Landing processor that Intel is launching this week, and four more will be coming out in October with integrated dual-port, 100 Gb/sec Omni-Path ports on the Xeon Phi package. Intel will eventually offer coprocessor versions of the Knights Landing chip that plug into PCI-Express 3.0 slots inside servers, but the precise configurations of these have not been revealed and their timing has been pushed out as far as we know. Here is the Knights Landing lineup and a comparison between the older Knights Corner coprocessors:
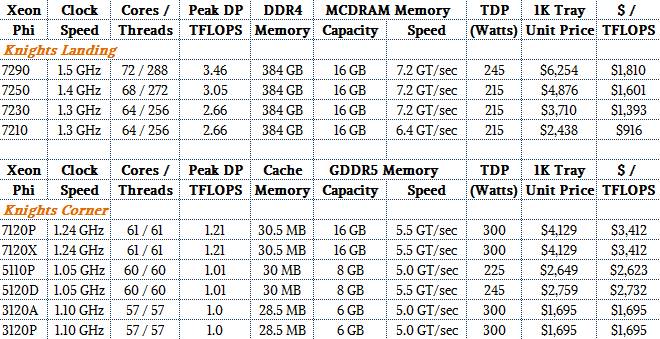
This, quite frankly, is the moment that we have been waiting for. As you can see from the table above, there are four different SKUs of the Knights Landing standalone processor that Intel is shipping now. Intel is varying the core counts, clock speeds, and memory transfer rates into and out of the MCDRAM a bit to yield different performance points. The Xeon Phi 7290 is what Wuischpard called the “Formula 1” version of the card, which has all 72 cores on the die running at 1.5 GHz and delivering 3.46 teraflops of peak theoretical double precision performance. This chip has a thermal design point of 245 watts and carries a single unit price of $6,254 when bought in 1,000-unit quantities.
“There will be some buyers for the Xeon Phi 7290, but it is a premium product and it is relatively low yielding so there will not be great supplies,” Wusichpard said. “Most of our early customers, including the large HPC research labs, are really focused on the 7230 and 7250, and in the HPC world, they tend to take top bin minus one to get the best price/performance. We actually think that the 7210 will be the more general purpose, high volume part, and you will notice that we priced it accordingly. You will get about 80 percent of the performance of the high-end Knights Landing at about 40 percent of the cost.”
In September, Intel will ship the variants of these four Knights Landing parts with on-package Omni-Path 100 series ports. Adding the Omni-Path links to the chip package boosts the price by $278 and raises the thermal design point by another 15 watts. Intel could eventually offer lower bin chips in the Knights Landing at even lower prices with lower core counts, but maybe not because the overlap with the Xeon CPUs might be too great.
The performance jump from the Knights Corner coprocessors to the Knights Landing processors for the most similar SKUs between the two lines (realizing we are comparing bootable chip with a coprocessor) ranges from somewhere between 2.6X and 2.9X with the price only rising by 1.4X to 1.5X. Hence, the bang for the buck on the Knights Landing has increased by a factor of two, almost precisely and not coincidentally we think. The cost per teraflops (at peak theoretical double precision) with the Xeon Phi 7290 Knights Landing processor, for example, is $1,810, compared to $3,412 for the high end Xeon Phi 7120P or 7120X PCI-Express cards based on Knights Corner. This is about what you would expect for product that does not have a tick-tock cadence but rather does an architecture change and a process shrink every three or four years.
The performance customers get with a Knights Landing processor is going to vary depending on the nature of the application and the dataset. As we have previously detailed, the Knights Landing chip has respectable single threaded performance compared to the prior Knights Corner. Here are some early results that Intel is showing on various benchmark tests against GPU accelerated systems:

We will be gathering up information on these benchmarks above and system pricing for the machines used to run the tests to compare Xeon Phi and CPU-GPU hybrids on various workloads to get a system-level price/performance metric. While Nvidia’s “Pascal” GPU accelerators offer higher performance, they also carry higher prices and at the system level it may not be as big of a difference as many think. (We shall see.)
The thing is that Intel is now apparently able to ship Knights Landing processors in volume and will be shipping accelerators (presumably with lower prices still) at some point in the future.
 Wuischpard said that Intel expects to ship more than 100,000 Xeon Phi units this year into the HPC market, and there is a good chance that more than a few hyperscalers are going to buy a bunch, too, for machine learning and possibly other workloads. More than 30 software vendors have ported their code to the new chip, and others will no doubt follow. And more than 30 system makers are bending metal around the Knights Landing processors.
Wuischpard said that Intel expects to ship more than 100,000 Xeon Phi units this year into the HPC market, and there is a good chance that more than a few hyperscalers are going to buy a bunch, too, for machine learning and possibly other workloads. More than 30 software vendors have ported their code to the new chip, and others will no doubt follow. And more than 30 system makers are bending metal around the Knights Landing processors.
We also hear that Intel may do something special with Knights Landing for the machine learning crowd from a keynote address at the ISC 2016 conference today, so stay tuned for that. [Editor’s note: This rumor did not pan out.]
The single-socket Knights Landing processor is compatible with both the Linux and Windows Server operating systems that dominate datacenters today, and indeed any application that has been certified to run on either can run on a Knights Landing. That opens up the market for them pretty wide, too.
Now we find out how customers will use it.


Intel’s “Ponte Vecchio” GPU Better Not Be A Bridge Too Far
It is pretty obvious to everyone who watches the IT market that Intel needs an architectural win that leads to a product win in datacenter compute. And it is pretty clear that the top brass at Intel are putting a lot of chips down on the felt table that the …
Intel Downplays Hybrid CPU-GPU Engines, Merges NNP Into GPU
When Intel announced its “Falcon Shores” project to build a hybrid CPU-GPU compute engine back in February 2022 that allowed the independent scaling of CPU and GPU capacity within a single socket, it looked like the chip maker was preparing to take on rivals Nvidia and AMD head on with …

Crazy Move #1486: What If Intel Buys VMware
Does Michael Dell want to be Intel’s largest shareholder? Maybe, just maybe. And there could be an interesting turn of events once VMware is spun off to shareholders in Dell (the company), leaving Dell (the man) as VMware’s largest shareholder, with an approximate 42 percent stake. Imagine, if you will, …
In the tables, “GFLOPS” should be “TFLOPS”.
“integrated high speed main memory” ought to be useful on consumer processors and commodity servers. Consumers generally don’t need more than 16GB, 32GB max, and many servers are the same. Get rid of the DIMMs. Maybe this kind of on-die or on-MCM RAM could make L3 cache obsolete too?
Developer systems below 5k$ count me in. Where can I get one?
The two biggest steps forward here are the integration of this number of X86-64 cores on a single chip, and the remarkable multi-layer, silicon via, MCDRAM near memory.
Intel could use the same technologies to make a device with 8 to 16 Broadwell/Skylake cores (such as the 12 core 3GHz E5-2687W v4) and 16 or 32GB of MCDRAM near memory, WITH Ethernet/IB/Omnipath (does this require a separate chip?) and with NO DDR, NO PCI and NO QPI. This Intel-Micron “brick” would be a complete system suitable for some standalone commercial servers – and I think, some or many HPC clusters.
Intel et al. crams more and more (slower and slower) cores into each CPU, each with extra FPUs for vector operations. But the cores are starved for main memory bandwidth and this approach is only helpful for the subset of applications which can be done with large numbers of threads, each beavering away with a relatively small working set which fits in their L2 – and a subset of their shared L3 – caches. TFLOPS don’t matter when the cores are waiting for cache coherency and main memory access.
The brick’s ~12 fully fledged cores would run with much higher memory bandwidth and lower latency than any DDR-based server. A subset of applications would work with 12 threads in 16GB, and more would run fine with 32GB. The OmniPath/IB/Ethernet network with RDMA and the MCDRAM size, width and speed would be the primary bottlenecks.
The chip area and power saved by ditching DDR, PCI and QPI – and perhaps by reducing L3 cache – could be better used for 16 rather than 8 MCDRAM ports.
The bricks and the heatsinks for their local switching power supplies could be made the same height. 8, 16 or maybe more could populate a single PCB in a 1U box. There’s no DIMMs or other devices sticking up, so they could all be cooled by a single flat water-cooled heat exchanger with the whole blade now not needing a box, and still being no thicker than 1U. The blades would plug into a backplane that handles the networking and power. Water-based cooling is much more power-efficient and effective than using air.
Such racks of servers would be extraordinarily dense, with short signal paths for the networking. Water-cooled switches (no DIMMs there either) would plug into the backplane too. Conventional servers on the same network would have TBs of DDR RAM, FLASH, SSDs etc.
IF the MCDRAM per brick is big enough for all the applications, this would make a Jim Dandy cluster – fast, compact, quiet, efficient and easy to program.
I slightly disagree with all the enthusiasm of people who haven’t and will never touch this hardware. As a scientist & HPC practitioner, I do like Xeon Phi (MIC, in general) because it was offered as a cheap solution to cluster-builders. I was designing a CPU+GPU cluster and stumbled upon the fire sale of the 8GB, 57 core 31S1P’s ($125USD/ea) in December 2014, continuing to 2015 and perhaps even today. I ended up with all 3 platforms in my machinery.
I bought several dozen KNCs, built cheap clusters and am generally very happy with their reliability and functioning so far. Working alone I haven’t tried a lot of different software on them yet (mainly 3d CFD, which is a bandwidth limited task),
My price/performance ratio computed, like in the article, in a silly way, is therefore 10+ times better, namely $125/TFLOP. Silly, since you need to facor in the other hardware in a cluster.
I also did a lot of optimization of price/perf while constructing the clusters, and am absolutely sure that relative to commerial consolidators (using equivalent Phi’s), I can beat their Price/perf ratios by a factor of 4 or 5.
For medium-sized, BW-bound jobs like mine KNL is perhaps 2.5 times faster, for pure arithmetic jobs let’s say 3 times, ok? (that may actually be a generous estimate).
Price of the compute node with 4 KNL inside will be like $15k or god knows how much, no limit really; you can enquire if you’re curious. The cheapest KNL seems to be 7210 for $2438, so a node must cost $5k+4*2.4k = $15k at least, since consolidators want to sell you dual-E5 Xeon systems that won’t be very cheap.
I was able to construct 9 KNC machines with 31S1P for the price of 1 KNL machine,
so I’m clearly better off by a factor of 3 (or more) building a KNC cluster than an KNL cluster!
If you care about performance and are on tight budget, you now know what I’d recommend.
“If you care about performance and are on tight budget, you now know what I’d recommend.”
EPYC?