

When it comes to building extreme scale computing platforms, there are plenty of system design options but in supercomputing, the only practical choice for an OS is Linux.
A team from MIT and Sandia took note of this imbalance, noting that while traditionally it was the job of an OS to manage the hardware, now the controlling processor and the compute engines are far more separated. In other words, the OS is more like a resource tracker that manages usage of the hardware resources. They draw parallels between this and a database management system and have thus turned a database into an OS of sorts.
On the surface this may not sound logical—or more accurately, like it would be functional. But simulations of the database system (called TabulaROSA) on a 32k core supercomputer yield some impressive early results with a measured 20X performance boost over Linux while managing 2000X more processes in fully searchable tables.
“Current mainstream operating systems trace their lineages back 50 years to computers designed for basic office functions running on serial, local, homogeneous, deterministic hardware operating in benign environments. But increasingly, these traditional OS platforms are bystanders at best and impediments at worst at using purpose-built processors,” the team explains, pointing to GPU and other accelerators wherein the user has to interact with the OS to make use of specialized processors.
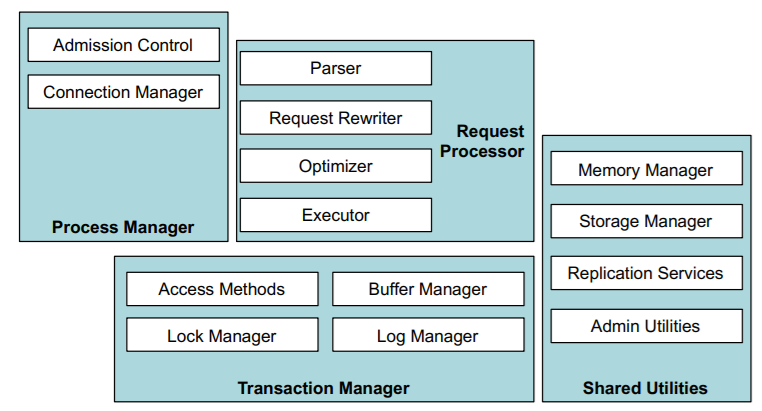
While there are Linux variants that support users with heterogenous systems, the team saw areas where further redundancies of the OS could be removed and replaced with their database approach.
TabulaROSA explores the “potential benefits of implementing OS functions in a way that leverages the power and mathematical properties of database systems,” with the idea that database systems already do much of what an OS handles, including data ingestion and cleaning, transformations, analytics, and moving unified data to other systems.
The team defines key OS functions in terms of “rigorous mathematical semantics (associative array algebra) that are directly translatable into database operations. Because the math of database table operations are based on a linear system over the union and intersection semiring, these operations possess a number of mathematical properties that are ideal for parallel operating systems by guaranteeing correctness over a wide range of parallel operations.”
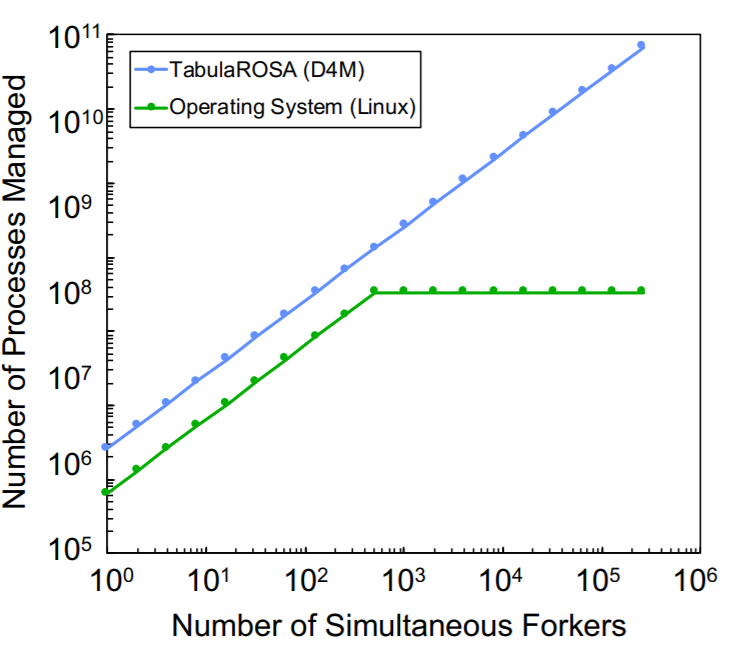
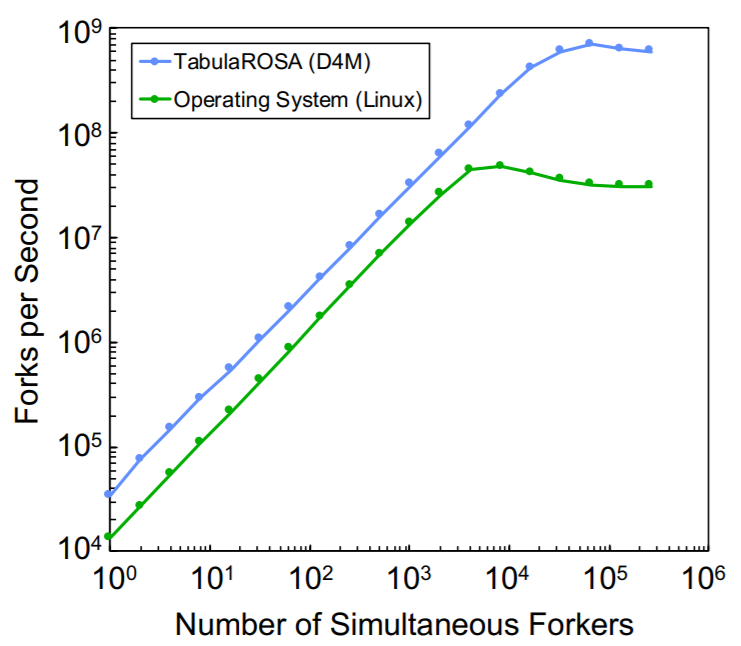
“Simulations of forking in TabularROSA are performed by using an associative array implementation and are compared to Linux on a 32,000+ core supercomputer. Using over 262,000 forkers managing over 68,000,000,000 processes, the simulations show that TabulaROSA has the potential to perform operating system functions on a massively parallel scale. The TabulaROSA simulations show 20x higher performance compared to Linux, while managing 2000x more processes in fully searchable tables”
Efficiencies can be easily measured in simulations and theory can be better than practice. There is far more to Linux running on large supercomputers than resource tracking and allocation. Still, this shows that there are further ways to continuing paring down the OS and let resource management be offloaded to software running in the background. Much more depth in the full paper.

Be the first to comment