

Living in the future, as we do now, you no longer have to expend huge amounts of capital to build a petaflops-scale supercomputer. You can rent it on a public cloud and do the big job a lot faster – provided that the job can scale, of course.
To make that point, University of California San Diego researchers Alexander Breuer (now at Fraunhofer ITWM) and Yifeng Cui created a cloudy cluster based on Intel’s “Skylake” Xeon SP processors and comprised of 768 c5.18xlarge instances with a total of 27,648 cores on Amazon Web Services. This system, running a seismic simulation on CPUs only, achieved 1.09 petaflops of performance. The technology tricks to make this happen are well explained, benchmarked, and applicable to a wide-variety of HPC applications, and in fact are detailed in a paper, presented recently at the ISC ’19 supercomputing conference, entitled Petaflops Seismic Simulations in the Public Cloud.
“By exploiting the public cloud for the setup of tailored elastic supercomputers, we obtain a true end-do-end approach, starting at the machine setup, covering HPC optimizations and reaching the full spectrum of modeling and simulation,” the authors write. This work illustrates, “the open source HPC ecosystem is well-prepared to operate high performance cloud computing solutions with the latest hardware enhancements.”
Vast Compute Drives 3D Topography
The EDGE (Extreme-scale Discontinuous Galerkin Environment) tool uses a fused forward simulation approach that was able to achieve petascale performance in the cloud, nearly matching the performance of an entire Top10 leadership supercomputer running the same workload in 2013 (that is, the workload ran on SuperMUC supercomputer, which was which was ranked ninth fastest in the world as of June 2013 and which was based on Intel Xeon E5-2680 processors. What was a capability class supercomputer only six years ago can now be rented on a public cloud, and that means the HPC community needs to start considering cloud as a viable resource, as this research and other cloudy supercomputers fired up in the past several years demonstrate.
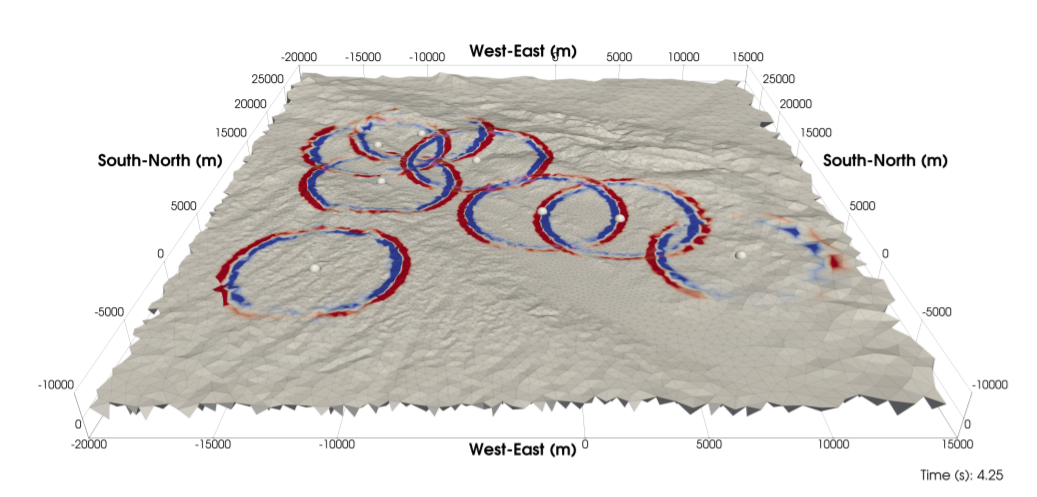
According to the UCSD team, such large compute capability meant they were able to utilize more complex 3D topological data as illustrated above. This addresses a challenge in the seismic community, “As we are reaching higher resolved frequencies through the use of more powerful supercomputers, the lack of modeling complexity is getting more severe.”
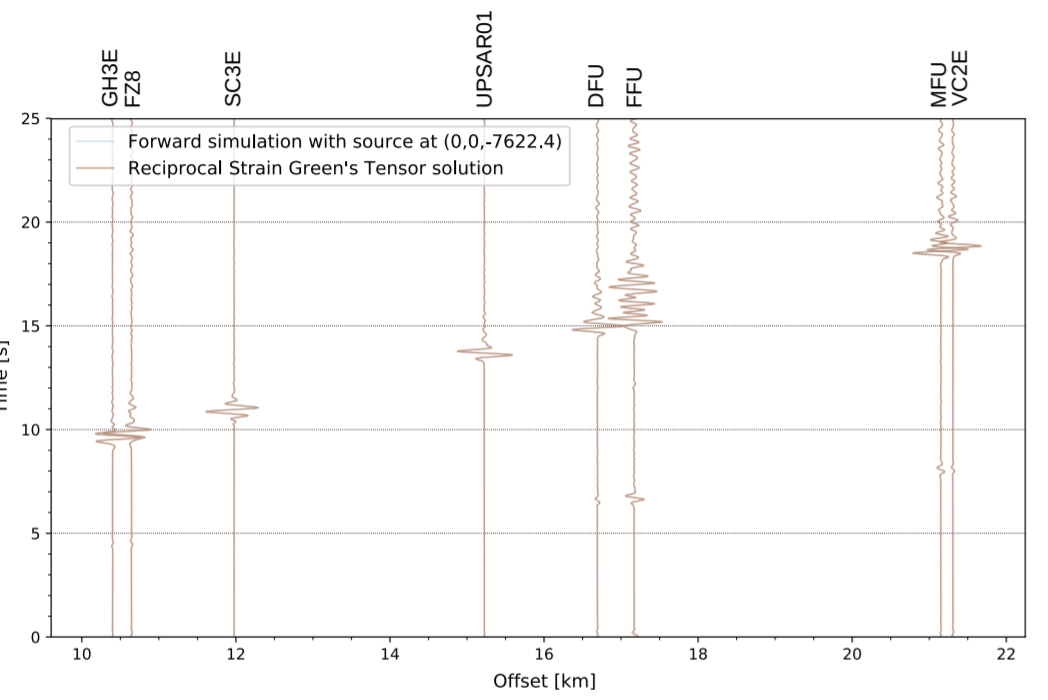
For their incorporation of 3D DEM data in reciprocal settings, the details of which are covered in the paper, the team found they achieved an almost perfect fit of the seismograms as shown in the figures below, which confirms the applicability of this aspect of the EDGE pipeline and which opens the door to further data-processing to benefit the seismic community such as the insertion of rupture uncertainties. All in all, the combination of more compute and 3D data reflects a nice step forward in seismic simulations.
Importantly, the tailored virtual machines available on AWS eliminate a plague of HPC bottlenecks, such as overhead from operating systems, TLB trashing, and libraries. The cloud provides the ability to boot with lightweight hypervisors with Nitro SmartNICs that are optimized for performance. In a beautiful demonstration of what is possible with access to these VMs, the UCSD team eliminated many of the performance-sapping bottlenecks that have plagued HPC applications since the development of general-purpose hardware.
For example, the cloud-based virtual machines were booted with two cores reserved for the operating system and the remaining cores were dedicated to running the seismic workload without any timeslicing, system call, or other OS overhead. This dedicated core approach is similar to computing-core approach used by the IBM BlueGene systems, an approach that has proven to be challenging to implement on conventional batch-oriented supercomputers that don’t allow VMs or rebooting of the operating system between jobs. However, this ability is supported in the AWS cloud using only freely available open source software and tools.
Managing Communications In A Petascale Cloud Environment
Communications between the dedicated compute cores and an additional set of two communication cores per instance (see slide 15 in the presentation) is accomplished through shared-memory so the UCSD team were able to utilize conventional HPC communications schemes. However, the team observed that they needed to adjust to a cloud-based communications fabric, “from an interconnect point of view, one has to tackle a 4X to 5X slow-down in terms of bandwidth and 25X in terms of latency, compared to latest high-speed and low-latency interconnects.” For this reason, the team fused multiple simulations in one execution of the solver to accommodate latency and bandwidth discrepancies in the memory subsystem and network interconnect.
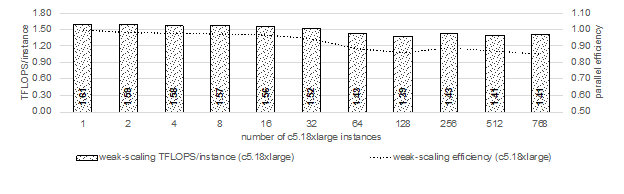
With this approach, the team was able to achieve “a peak efficiency of over 20 percent and a close-to 90 percent parallel efficiency in a weak scaling setup. In terms of strong scalability, we were able to strong-scale a science scenario from 2 to 64 instances with 60 percent parallel efficiency” the team wrote, concluding, “This work is, to the best of our knowledge, the first of its kind at such a large scale.”
Comparisons were also made to a dedicated on-premises bare-metal dual-socket Xeon SP 8180 Platinum machine connected by a 100 Gb/sec Omni-Path fabric. The results of the microbenchmark runs were used to tweak the cloud instances to achieve best performance.
Scaling results showing the impact of bare-metal Intel Xeon SP cluster compared to the cloud instances are shown below. Succinctly, better performance can be achieved with a higher-performance processor and fabric, but the UCSD fusion technique clearly delivers good performance.

Gigabyte Page Sizes Sliminate MMU Overhead And TLB Trashing
The UCSD team noted that ”EDGE’s unstructured accesses to data of the four faced-adjacent tetrahedrons in the neighboring update kernel (4 · 35 · 9 · 16 · 4 byte/float = 80,640 bytes) generate a significant pressure on the memory subsystem.”
HPC application developers are well aware of the many benefits and key challenge of running in a virtual memory environment from a performance perspective. While virtual memory provides application protection (as no process can inadvertently write into the address space of another process in a batch environment), it also introduces the need to fetch address lookup information into the MMU (Memory Management Unit). Unstructured memory accesses can cause a performance challenge called TLB thrashing, which can insert a delay of many thousands of processor cycles per application memory access, causing cause application performance to plummet. This occurs even when the application is running entirely out of main memory. The fix is to use gigabyte pages, which are supported by modern processors.
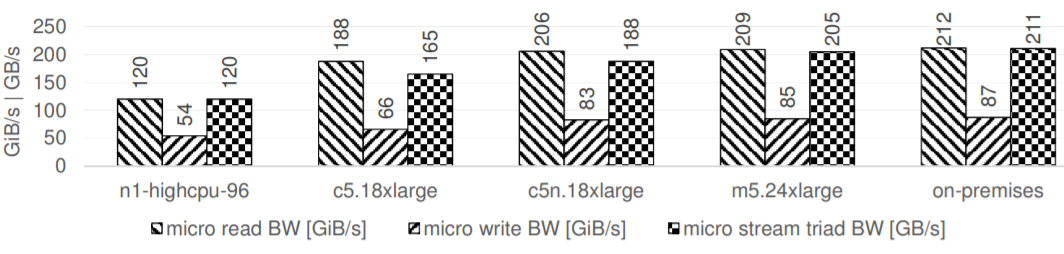
The STREAM-Triad microbenchmark tests performed by the team confirmed that the AWS instances run at close-to full read bandwidth. However, we refer the reader to section 4.4 of the ISC’19 paper, Petaflops Seismic Simulations in the Public Cloud, for full details and caveats when running in a cloud environment.
LIBXSMM Generates And Compiles Runtime Optimized Vectorized Kernels
Small matrix multiplication kernels are very common in scientific applications. Having a library that generates code for the specific processor architecture and which can achieve a high percentage of peak performance – particularly on sparse matrices – is invaluable. The forward thinking use of fused simulations and the use of hardware optimized instructions, and when desired, lower-precision arithmetic means that LIBXSMM can benefit a huge number of HPC applications.
LIBXSMM is freely available on github. It has been successfully integrated into other scientific code which employ small matrix multiplications including the Gordon Bell winning Nek5000/Box family, CP2K (a previous Gordon Bell finalist) and SeisSol (a previous Gordon Bell finalist and SC Best Paper winner) but also the deep learning framework Tensorflow and the linear algebra C++ package Eigen to name a few.
EDGE exploits the ability of LIBXSMM to run fused simulations to increase performance. Without getting too technical, the EDGE solver can utilize the results of a number of different seismic sources in its forward solver. Succinctly, the solver uses LIBXSMM to perform the many small, sparse matrix operations in parallel at the same time.
It is common in the scientific literature to refer to this as parallelizing over multiple right-hand sides of the PDEs, but the EDGE authors prefer the term fused simulation to highlight the advantages of their approach, which are:
- The ability to perform full vector operations even when using sparse matrix-operations by fusing multiples of the vector-width. Non-fused operations can have up-to a 50 percent zero padding, which represents wasted flops.
- Data structures are automatically aligned for vector operations.
- Shared read-only data structures can substantially increase arithmetic intensities.
- Fused simulations are less sensitive to memory latencies and conditional jumps. This reduces the performance penalty of start-up latencies or branch mispredictions. It also helps reduce network latencies due to larger MPI-messages having identical exchange-frequencies.
Arguably, the most important thing about the techniques used in the paper discussed above is that they can be applied to a number of HPC applications, be they cloud-based or dedicated to run on-premises.
Rob Farber is a global technology consultant and author with an extensive background in HPC and advanced computational technology that he applies at national labs and commercial organizations. Rob can be reached at info@techenablement.com

Intel Adjusts, However Slowly, To New Realities In The Datacenter
While chip designer and maker Intel has a new strategy and a new executive team to implement it, it is going to take a long time for changes made last year and this year to be felt and for product and process roadmap changes to put the company into a …

Putting TACC’s “Stampede3” Through The HBM Paces
When you host the workhorse supercomputers of the National Science Foundation, you strive to provide the best possible solutions for your scientists. The Stampede and Frontera systems at the Texas Advanced Computing Center (TACC) at the University of Texas at Austin have been those workhorses. TACC continues to get National …

Keeping Pace In A Fast-Moving AI Space
During the Intel AI Summit earlier this month where the company demonstrated its initial processors for artificial intelligence training and inference workloads, Naveen Rao, corporate vice president and general manager of the Artificial Intelligence Products Group at Intel, spoke about the rapid pace of evolution in the AI space that …
With the new AMD 7nm EPYC server chips, with 64 cores/ 128 Threads, and 128 cores/ 256 threads for dual socket configurations, it should take half the amount of processors for the same or better performance, and at a fraction of the cost.