

Moore’s Law may be slowing down performance increases in compute capacity, but InfiniBand networking did not get the memo. Mellanox Technologies has actually picked up the pace, in fact, and is previewing 200 Gb/sec InfiniBand switches and server adapters that are timed to come to market with a slew of Xeon, Opteron, ARM, and Power processors due around the middle of next year.
The new Quantum InfiniBand switch ASIC and its companion ConnextX-6 adapter ASICs come relatively hot on the heels of the 100 Gb/sec Enhanced Data Rate, or EDR, products that were announced in the fall of 2014 and started shipping in systems in early 2015. Considering that it gets progressively more difficult to squeeze more speed out of silicon even as processes for etching transistors shrink, the fact that Mellanox is able to announce InfiniBand High Data Rate, or HDR, products this week and show them off at the SC16 supercomputing conference next week is a testament to its commitment to keep InfiniBand ahead of the Ethernet pack in terms of high bandwidth and low latency and to keep well ahead of Intel’s Omni-Path alternative for higher performance computing and analogous workloads at large enterprises and hyperscalers.
The Quantum ASIC is a kicker to the current Switch-IB 2 chip, a second-generation of 100 Gb/sec InfiniBand switch chips that actually only debuted last fall at the SC15 conference, so Mellanox is actually doing a tick-tock model that is akin to how Intel rolls out Xeon processors and, interestingly, that Intel has not yet adopted for its own Omni-Path interconnect, which runs at 100 Gb/sec and is slated to hit 200 Gb/sec in its second generation. That Switch-IB 2 chip was significant because it included features to offload MPI collective and other operations that are key for parallel supercomputing workloads from the central processors on the server nodes of a cluster to the switch, where oddly enough, everything is already being collected and arguably where these operations should be to improve latency and reduce load on the number-crunching server nodes.
The Switch-IB chip from 2014 and the Switch-IB 2 chip from 2015 are essentially the same in terms of their raw networking capability. Port-to-port latency was pushed down to an absolute low of 86 nanoseconds with both chips, and the ASICs can support 36 ports running at 100 Gb/sec speeds. Both ASICs had 7.2 Tb/sec of aggregate bandwidth and supported 7.02 billion messages per second. The adaptive routing and congestion control features and the support for multiple topologies – fat tree, 2D mesh, 3D mesh, 2D torus, and 3D torus – were the same between the Switch-IB and Switch-IB 2 fabrics, too. But with the switch offloading capabilities of the Switch-IB 2 chip and the companion Connect-X5 adapter cards, which also take some of that MPI collectives work off of the CPUs in the cluster, around 60 percent of the MPI load in the system was running on the network, compared with the about 40 about 30 percent with the Switch-IB 2 and ConnectX-4 combination launched in late 2014. Gilad Shainer, vice president of marketing at Mellanox, tells The Next Platform that with the Quantum and ConnectX-6 combo, the percentage of MPI operations that are shifted from the CPUs to the network adapters and switches is now more like 70 percent.
“Future devices will take it further,” says Shainer, who already has his eye on 400 Gb/sec switches and adapters. “At some point we will be in a situation where the entire MPI stack will be running on the network. In probably another couple of generations, we will be there.”
That will be a very interesting development, indeed, and standing in stark contrast to the approach that Intel is taking with Omni-Path, which is to exploit cores on the server to accelerate and scale the network.
There is a religious war brewing about which way is better, and every HPC center and a few hyperscalers and cloud builders are making their choices because, at the end of the bidding process, they have to pick something. Every site has its history and preferences, and there is no question that Intel is benefitting from a cornucopia sale, mixing Xeon, Xeon Phi, Omni-Path, Lustre, and soon HPC Orchestrator, its commercialized version of the OpenHPC stack that is really a supercomputing cluster operating system as much as Mesos and Kubernetes are ones for hyperscalers and OpenStack is one for clouds. There is no question that Mellanox InfiniBand is going to benefit from having the bandwidth edge and from its partnerships within the Xeon server establishment and relationships it has with suppliers of Power, ARM, and Opteron iron. Eventually, Mellanox will roll out 200 Gb/sec Ethernet, probably under the Spectrum 2 name, and there is no reason that techniques for MPI offloading to the switch cannot be added to these machines; the ConnectX cards tend to speak both InfiniBand and Ethernet protocols, although with the 56 Gb/sec FDR generation there was a Connect-IB card that has special tunings for InfiniBand to boost performance and lower latency. Mellanox could do that again as it moves into 400 GB/sec and maybe 800 Gb/sec technology some years hence, driving those MPI operations completely off the server.
While the “Summit” and “Sierra” hybrid supercomputers being built for the US Department of Energy by IBM, Nvidia, and Mellanox had been sold and accepted with 100 Gb/sec EDR InfiniBand, Mellanox had always hoped to get 200 Gb/sec InfiniBand out the door in time to slip that 2X bandwidth jump into these machines, and Shainer confirms to us that this will indeed happen.
A Quantum Leap, Maybe Two
Unlike CPU makers, network switch chip suppliers are particularly cagey about letting out too many details about their chip layout and feature stack, except perhaps to the largest organizations that aim to deploy their devices or complete equipment based on them. Both Mellanox and Intel are willing to sell raw switch and adapter chips to third parties making their own devices, but they are also selling finished boxes as well as cables and software stacks to give customers a one-stop shopping experience for their network fabrics.
The main innovation in the Quantum ASIC is that the speed of the serializer/deserializer (SerDes) communications circuits run at 50 Gb/sec per lane, twice the 25 Gb/sec per lane that the Switch-IB and Switch-IB 2 chips as well as the Spectrum Ethernet chips employ. All three InfiniBand chips – Switch-IB, Switch-IB 2, and Quantum – have 144 of these SerDes blocks on them, and with the HDR InfiniBand, four lanes of 50 Gb/sec are grouped together to create a 200 Gb/sec port on the switch. The initial top-of-rack switch from Mellanox will support 40 ports running at 200 Gb/sec or 80 ports running at 100 Gb/sec. Interestingly, that 80-port configuration can be done by using cable splitters on the ports or by slicing the lane groups and two and literally making an 80 port switch, depending on what Mellanox or its ASIC customers want to do. Further down the road, Mellanox intends to provide modular, director-class switches that have as many as 800 ports running at 200 Gb/sec and 1,600 ports running at 100 Gb/sec.

The Quantum ASIC has 16 Tb/sec of aggregate switching bandwidth, which is 2.2X that of the prior generation of EDR switch chips, and can handle an aggregate of 16.6 billion messages per second, which is also (not surprisingly) about 2.2X more than the 7.02 billion messages per second rate that the Switch-IB and Switch-IB 2 chips could do.
As far as latency goes, when the Switch-IB and Switch-IB 2 chips came out, Mellanox said it would be around 86 nanoseconds for a port-to-port hop, but that has subsequently revised upwards to around 90 nanoseconds. Shainer says that the Quantum ASIC will do a little better and push it down below 90 nanoseconds as was the plan for the EDR family of chips. As we have pointed out before, getting latency much lower than that is difficult and pointless because the latency is elsewhere in the network – like in the MPI stack. This is where Mellanox is focused, and it can reduce that latency from tens of milliseconds to single-digit milliseconds or lower on a round trip through a network topology. Speaking of which, the Quantum switches will support fat tree, torus, dragonfly, and other topologies.
On the adapter side, the ConnectX-6 adapters that are paired with the Quantum switches and future Spectrum 2 Ethernet switches have 200 Gb/sec of bandwidth per port and deliver 600 nanosecond latency, end to end. These adapters will plug into both PCI-Express 3.0 and PCI-Express 4.0 ports, and it will probably be a good idea to have them in the latter for the extra I/O bandwidth this protocol – which ships first in Power9 servers next year – supplies. Interestingly, it will take 32 lanes of PCI-Express capacity to handle one ConnectX-6 card, so the servers will presumably have to have a pair of x16 slots next to each other to work in current servers. With the PCI-Express 4.0 protocol, you only need an x16 slot to meet the bandwidth needs of the card because it has twice the bandwidth. Each ConnectX-6 adapter can handle 200 million messages per second of HPC-style traffic.
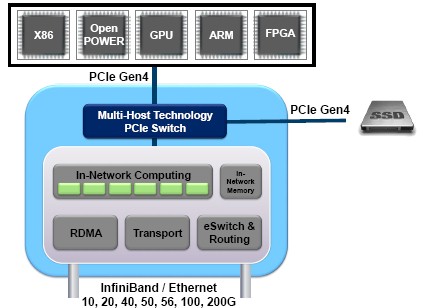
The ConnectX-6 cards have their own memory so they can do in-network computing in addition to MPI operation offload, and also accelerate NVM-Express over Fabric protocols for shared access to flash storage within a rack of systems. One very key thing that the ConnectX-6 adapters will manage is background checkpointing on clusters, saving the state of each node as it is running without having to quiesce the application as happens now. This is a huge feature for HPC shops.
The ConnectX-6 adapters also sport the multi-host partitioning capabilities that first debuted in the ConnectX-4 Lx adapters aimed at hyperscalers, which carved up a 100 Gb/sec adapter into four virtual 25 Gb/sec ports and embedded a PCI-Express switch on the device to route traffic from server nodes through the ConnectX ASIC and out to a companion 100 Gb/sec switch. With the ConnectX-6 adapters, Mellanox is doubling up the number of multi-host ports to eight per adapter. These multihost capabilities can cut down on datacenter networking costs by as much as 50 percent, and the wonder is why we don’t hear about more HPC centers using this capability.
Bandwidth is one thing, which helps clusters do more work, but having more ports on an ASIC means that it takes fewer switches to build out a network. And while the jump from 36 ports to 40 ports running at 200 Gb/sec may not seem like a lot, it helps some, and for those who are happy with 100 Gb/sec speeds, the Quantum ASICs supporting 80 ports are going to seriously cut back on the amount of gear needed to build a network and provide a significant advantage over the 48-port Intel Omni-Path switches that debuted last year. These Omni-Path switches, of course, had a radix advantage over the Switch-IB and Switch-IB 2 switches. (Radix is a term that refers to the number of ports per device.)
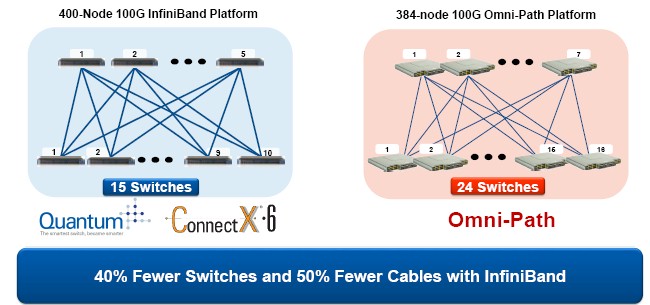
Here is one example Mellanox ginned up comparing a 400-node Quantum network with two levels compared to a 384-node Intel Omni-Path network with two levels:
Here is another comparison, this one for a 1,536-node setup:

“We are increasing the radix dramatically here,” says Shainer, and he did a little scalability math to make a point. “On a two-level fat tree network topology, you can do 3,200 ports with Quantum compared to 1,152 ports with the Omni-Path switches from Intel. If you go to three levels of fat tree, then Omni-Path is limited to 2,700 nodes and with Quantum we can do 128,000 nodes. That is a factor of 4.6X difference on a three level fat tree network.”
By the way, with the Switch-IB and Switch-IB 2 switches, a two-level fat tree cloud link to 648 server ports and a three-level fat tree could support 11,664 server ports across the fabric. So Quantum has a 4.9X scalability over Switch-IB on a two-level fat tree, and 11X on a three-level fat tree.
Mellanox has been talking for some time about how InfiniBand is being embraced by areas outside of HPC, particularly with database clusters and clustered storage as well as for selected jobs at hyperscalers and cloud builders. It remains to be seen if it can expand further than it has, but it seems pretty clear that Mellanox is intent on keeping InfiniBand well ahead of Ethernet and then keeping its Ethernet on the cutting edge as a hedge, hoping to keep growing both businesses. While Shainer cannot name a lot of names, he says that Baidu is using InfiniBand in its image recognition clusters, Facebook is using it in its Big Sur machine learning platform, PayPal is using it for its fraud detection systems, and even the DGX-1 machine learning appliance from Nvidia has four 100 Gb/sec adapters in it to keep those eight hungry “Pascal” Tesla P100 GPU accelerators well fed.
It is hard for people to let anything but Ethernet into their networks, but once they do, it probably gets a lot easier. The support of RDMA over Converged Ethernet (RoCE) mitigated this to a certain extent, but when HPC shops, hyperscalers, and cloud builders see they can get 200 Gb/sec InfiniBand in 2017 and 400 Gb/sec InfiniBand in 2019, they might have a rethink.
Stranger things have happened. Like InfiniBand taking off in supercomputers in the first place, for instance.


Lawrence Livermore Kicks In Funds to Foster Omni-Path Networking
Decades before there were hyperscalers and cloud builders started creating their own variants of compute, storage, and networking for their massive distributed systems, the major HPC centers of the world fostered innovative technologies that may have otherwise died on the vine and never been propagated in the market at large. …

Gelsinger Is Still Trying To Build The Next Intel
Intel chief executive officer Pat Gelsinger came into this week’s Intel Innovation 2022 conference less than two years into his plans to reshape the giant chip maker to fit into an IT world that is rapidly becoming more open, more cooperative, and more software-driven. During this keynote and ensuing meeting …

Building An Ecosystem for Heterogeneous Memory Supercomputing
The drive toward exascale computing is giving researchers the largest HPC systems ever built, yet key bottlenecks persist: More memory to accommodate larger datasets, persistent memory for storing data on the memory bus instead of drives, and the lowest power consumption possible. One of the biggest challenges architects and operators …
Not sure if I get the hype here. Isn’t Ethernet slated to release 400GBit/s next year? According to the roadmap or is that no longer valid? If it is still valid that lead would last relatively short.
The Ethernet 400 Gb/sec products are only for high-end routers with very expensive optical links. It is looking like 400 Gb/sec in aggregation and top of rack switches is somewhere between 2023 and 2027 if you look at the roadmap.
http://www.ethernetalliance.org/wp-content/uploads/2015/03/Ethernet-Roadmap-2sides-Final-27April.pdf