
Just about everybody, including Nvidia, thinks that in the long run, most people running most AI training and inference workloads at any appreciable scale – hundreds to millions of datacenter devices – will want a cheaper alternative for networking AI accelerators than InfiniBand.
While Nvidia has argued that InfiniBand only represents 20 percent of the cluster cost and it boosts performance of AI training by 20 percent – and therefore pays for itself – you still have to come up with that 20 percent of the cluster cost, which is considerably higher than the 10 percent or lower that is the normal for clusters based on Ethernet. The latter of which has feeds and speeds that, on paper and often in practice, make it a slightly inferior technical choice.
But, thanks in large part to the Ultra Ethernet Consortium, the several issues with Ethernet running AI workloads are going to be fixed, and we think will also help foment greater adoption of Ethernet for traditional HPC workloads. Well above and far beyond the adoption of the Cray-designed “Rosetta” Ethernet switch and “Cassini” network interface cards that comprised the Slingshot interconnect from Hewlett Packard Enterprise and not including middle of the bi-annual Top500 rankings of “supercomuters” that do not really do either HPC or AI as their day jobs and are a publicity stunt by vendors and nations.
The discussion of how Ethernet is evolving was the most important thing discussed during the most recent call with Wall Street by Arista Networks, which was going over its financial results for the first quarter of 2024 ended in March.
As we previously reported, Meta Platforms is in the process of building two clusters with 24,576 GPUs each, one based on Nvidia’s 400 Gb/sec Quantum 2 InfiniBand (we presume) and one built with Arista Network’s flagship 400 Gb/sec 7800R3 AI Spine (we know), which is a multi-ASIC modular switch with 460 Tb/sec of aggregate bandwidth that supports packet spraying (a key technology to make Ethernet better at the collective network operations that are central to both AI and HPC). The 7830R3 spine switch is based on Broadcom’s Jericho 2c+ ASIC, not the more AI-tuned Jericho 3AI chip that Broadcom is aiming more directly at Nvidia’s InfiniBand and that is still not shipping in volume in products as far as we know.
The interconnect being built by Arista Networks for the Ethernet cluster at Meta Platforms also includes Wedge 400C and Minipack2 network enclosures that adhere to the Open Compute Projects favored by Meta Platforms. (The original Wedge 400 was based on Broadcom’s 3.2 Tb/sec “Tomahawk 3” StrataXGS ASIC and the Wedge 400C used as the top of racker in the AI cluster is based on a 12.8 Tb/sec Silicon One ASIC from Cisco Systems. The Minipack2 is based on Broadcom’s 25.6 Tb/sec “Tomahawk 4” ASIC. It looks like Wedge 400C and Minipack2 are being used to cluster server hosts and the 7800R AI Spine is being used to cluster the GPUs, but Meta Platforms is not yet divulging the details. (We detailed the Meta Platforms fabric and switches that create it back in November 2021.)
Meta Platforms is the flagship customer for Ethernet in AI, and Microsoft will be as well. But others are also leading the charge. Arista Networks revealed in February that it has design wins for fairly large AI clusters. Jayshree Ullal, co-founder and chief executive officer at the company, provided some insight into how these wins are progressing towards money and how it sets Arista Networks up to reach its stated goal of $750 million in AI networking revenue by 2025.
“This cluster,” Ullal said on the call referring to the Meta Platforms cluster, “tackles complex AI training tasks that involve a mix of model and data parallelization across thousands of processors, and Ethernet is proving to offer at least 10 percent improvement of job completion performance across all packet sizes versus InfiniBand. We are witnessing an inflection of AI networking and expect this to continue throughout the year and decade. Ethernet is emerging as a critical infrastructure across both front-end and back-end AI data centers. AI applications simply cannot work in isolation and demand seamless communication among the compute nodes consisting of back-end GPUs and AI accelerators, as well as the front-end nodes like the CPUs alongside storage.”
That 10 percent improvement in completion time is something that is being done with the current Jericho 2c+ ASIC as the spine in the network, not the Jericho 3AI.
Later in the call, Ullal went into a little more detail about the landscape between InfiniBand and Ethernet, which is useful perspective.
“Historically, as you know, when you look at InfiniBand and Ethernet in isolation, there are a lot of advantages of each technology,” she continued. “Traditionally, InfiniBand has been considered lossless. And Ethernet is considered to have some loss properties. However, when you actually put a full GPU cluster together along with the optics and everything, and you look at the coherence of the job completion time across all packet sizes, data has shown – and this is data that we have gotten from third parties, including Broadcom – that just about in every packet size in a real-world environment, comparing those technologies, the job completion time of Ethernet was approximately 10 percent faster. So, you can look at this thing in a silo, and you can look at it in a practical cluster. And in a practical cluster, we are already seeing improvements on Ethernet. Now, don’t forget, this is just Ethernet as we know it today. Once we have the Ultra Ethernet Consortium and some of the improvements you are going to see on packet spraying and dynamic load balancing and congestion control, I believe those numbers will get even better.”
And then Ullal talked about the four AI cluster deals that Arista Networks won versus InfiniBand out of five major deals it was participating in. (Presumably InfiniBand won the other deal.)
“In all four cases, we are now migrating from trials to pilots, connecting thousands of GPUs this year, and we expect production in the range of 10K to 100K GPUs in 2025,” Ullal continued. “Ethernet at scale is becoming the de facto network and premier choice for scale-out AI training workloads. A good AI network needs a good data strategy delivered by a highly differentiated EOS and network data lake architecture. We are therefore becoming increasingly constructive about achieving our AI target of $750 million in 2025.”
If Ethernet costs one half to one third as much, end to end including optics and cables and switches and network interfaces – and can do the work faster and, in the long run, with more resilience and at a larger scale for a given number of network layers, InfiniBand come under pressure. It already has, if the ratio of four wins out of five on fairly large GPU clusters, as Arista Networks has, is representative. Clearly the intent of citing these numbers is to convince us that it is representative, but the market will ultimately decide.
We said this back in February and we will say it again: We think Arista Networks is low-balling its expectations, and Wall Street seems to agree. The company did raise its guidance for revenue growth in 2024 by two points, to between 12 percent and 14 percent, and we think optimism about the uptake of Ethernet for AI clusters – and eventually maybe HPC clusters – is playing a part here.
But here is the fun bit of math: For every $750 million that Arista Networks makes in AI cluster interconnect sales, Nvidia might be losing $1.5 billion to $2.25 billion. In the trailing twelve months, we estimate that Nvidia had $6.47 billion in InfiniBand networking sales against $39.78 billion in GPU compute sales in the datacenter. At a four to one take out ratio and a steady state market, Nvidia gets to keep about $1.3 billion and the UEC collective gets to keep $1.7 to $2.6 billion, depending on how the Ethernet costs shake out. Multiply by around 1.8X to get the $86 billion or so we expect Nvidia to book in datacenter revenues in 2008 and you see the target for InfiniBand sales is more like $12 billion if everything stays the same.
There is plenty of market share for UEC members to steal, but they will steal it by removing revenue from the system, like Linux did to Unix, not converting that revenue from one type of technology to another. That savings will be plowed back into GPUs.
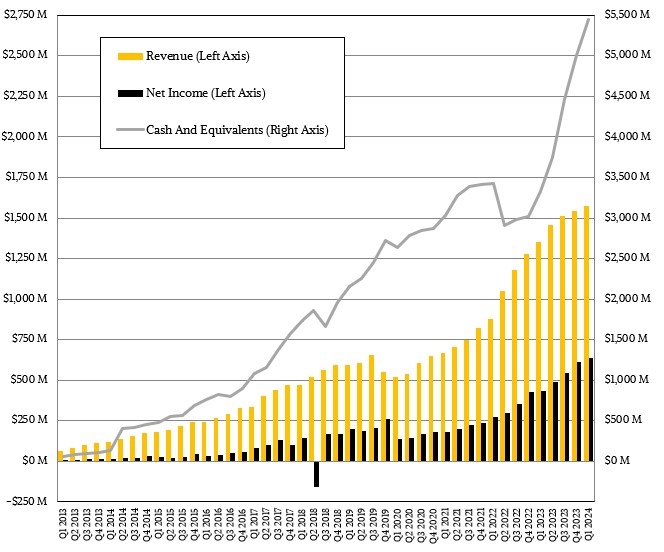
In the meantime, Arista turned in a pretty decent quarter with no real surprises. Product sales were up 13.4 percent to $1.33 billion, and services revenues rose by 35.3 percent to $242.5 million. Software subscriptions, which are within products, were $23 million, so total annuity-like services accounted for $265.6 million, up 45.6 percent year on year. Total revenues were up 16.3 percent to $1.57 billion. Net income rose by 46.1 percent to $638 million, and Arista Networks existed the quarter with $5.45 billion in cash and we estimate somewhere around 10,000 customers. We think Arista had about $1.48 billion in datacenter revenues, and an operating income of around $623 million for this business. Which is what we care about. Campus and edge are interesting, of course, and we hope they will grow and be profitable, too, for Arista Networks and others.

Nvidia: There’s A New Kid In Datacenter Town
Unless you were born sometime during World War II, you have never seen anything like this before from a computing system manufacturer. Not the rise of Sun Microsystems, EMC, and Oracle during the Dot Com Boom, who were transformative to the commercialization of the Internet. And if the current trends …
Everyone Is Chasing What Nvidia Already Has
Transitions in the datacenter take time. It took Unix servers a decade, from 1985 through 1995, to supplant proprietary minicomputers and a lot of mainframe capacity that would have otherwise been bought. And from 1996 through 2001 or so, Sun Microsystems servers set the pace and reaped the profits, although …

RISC-V Upstart Targets ML Inference Performance, Power Efficiency
There is a growing number of vendors big and small going hard to the hoop to make processors for artificial intelligence workloads. AI and machine learning are key enablers of automation and analytics that play an increasingly crucial role in a highly distributed IT environment that spans on-premises datacenters, public …
AI DC networking :
Nvidia Infiniband 2023 : $6.47 billion
Arista Ethernet 2025 : $0.75 billion (?)
Why do customers choose Infiniband if “Ethernet is proving to offer at least 10 percent improvement of job completion performance across all packet sizes versus InfiniBand” ?
It’s been like the Hundred Years’ War between The Ethernets and the Infinibands, but it looks like the high-command field strategists and generals of the Ultra Ethernet Consortium have finally developed the needed low latency packet spraying dynamic load balancing and congestion control weaponry needed for their ultimate takeover of AI and HPC comms territories … but by 2025 this time (almost right away, but not quite, due to tail latency?). Will the “confederates” eventually win this one out against the “secessionists”? History will tell:
Greasing The Skids To Move AI From InfiniBand To Ethernet (2024)
Ethernet Consortium Shoots For 1 Million Node Clusters That Beat InfiniBand (2023)
CISCO Guns for Infiniband (2023)
Broadcom Takes on Infiniband (2023)
Google abandons ethernet to outdo infiniband (2022)
The Eternal Battle Between InfiniBand And Ethernet In HPC (2021)
Infiniband, still setting the pace for HPC (2020)
It sure looks like it to me.
Risk-management, because IB is a safe and well-understood fabric for clusters. And arguably until recently ethernet simply didn’t scale easily.
Another interesting point is that IB has traditionally carried aspirations of smarter networking – verbs, offloading collectives, etc. Is it true that IB efforts in this direction have failed? I still see marketing about smarter IB NICs – or is it just that that kind of offload isn’t leveraged by the central AI frameworks?
It is utterly astonishing how much money is being dumped into such little gain.
In the early days of computing, you could throw what would be the equivalent of a few million to transition from binary coding to assembly to using higher level languages for efficiency improvements of several thousand if not hundreds of thousands of percent in coding time.
Now it’s tens to possibly hundreds of billions, for nebulous promises of tens of percent, in both performance of the system itself and of what the output can do.
Historically, Infiniband had appreciably lower latency than Ethernet and quicker time-to-market for each new performance generation.
InfiniBand had low latency in a port to port hop inside the switch and that often translated into a very big performance difference across hundreds to thousands of endpoints. But now we are at tens of thousands of endpoints moving on to hundreds of thousands to perhaps a million, and the game is different. It is a statically configured network (InfiniBand) versus a dynamically configured one (Ethernet) and it is 3X the cost versus 1X the cost. There was a time when InfiniBand was cheaper and better and equally scalable. I remember it. Now it is more expensive, and not as scalable for a given number of layers in a network, and soon it will not have lower end-to-end latency for real applications. Nvidia would do well to license whatever Microsoft did with InfiniBand and add it to the Quantum line to add multitenancy and security.
Can you expand on this static-vs-dynamic thing? Are hyperscalers actually modifying the fabric topology dynamically, in response to job layout on nodes?